版权声明:个人原创,禁止私自转载,如需转载引用请私信联系——Zetrue_Li https://blog.csdn.net/weixin_37922777/article/details/89482678
机器学习(周志华) 西瓜书 第八章课后习题8.5—— Python实现
-
实验题目
试编程实现Bagging,以决策树桩为基学习器,在西瓜数据集3.0α上训练一个Bagging集成,并与图8.6进行比较。
-
实验原理
- 自助采样法:给定包含m个样本的数据集,先随机取出一个样本放入采样集中,再把该样本放回初始数据集,使得下次采样时该样本仍有可能被选中,这样,经过m次随机采样操作,我们得到含m个样本的采样集,初始训练集中有的样本在采样集里多次出现,有的则从未出现,有的则从未出现。
- Bagging采样方法:采样出T个含m个训练样本的采样集,然后基于每个采样集训练出一个基学习器,再将这些基学习器进行结合。在对预测输出进行结合时,Bagging通常对分类任务使用简单投票法,对回归任务使用简单平均法。若分类预测时,出现两个类收到同样票数的情形,则最简单的做法就是随机选择一个,也可进一步考察学习器投票的置信度来确定最终胜者。
- 基学习器采用决策树桩,以单一属性作为树根,按连续型属性划分点作标签分类
- Bagging算法:

-
实验过程
数据集获取
获取书中的西瓜数据集3.0α,并存为data_3α.txt
密度,含糖率,好瓜
0.6970000000000001,0.46,是
0.774,0.376,是
0.634,0.264,是
0.608,0.318,是
0.556,0.215,是
0.40299999999999997,0.237,是
0.48100000000000004,0.149,是
0.43700000000000006,0.21100000000000002,是
0.6659999999999999,0.091,否
0.243,0.267,否
0.245,0.057,否
0.34299999999999997,0.099,否
0.639,0.161,否
0.657,0.198,否
0.36,0.37,否
0.593,0.042,否
0.7190000000000001,0.10300000000000001,否
---------------------
作者:Zetrue_Li
来源:CSDN
原文:https://blog.csdn.net/weixin_37922777/article/details/89473668
版权声明:本文为博主原创文章,转载请附上博文链接!算法实现
面向对象编程,构造决策树桩(单层决策树)类,决策树基于信息增益为准则来选择划分属性

仿造scikit-learn模块,封装构造Bagging分类器类

读取数据集

按照图8.6格式,绘制学习器边界图

X, Y分别是属性数据集,对应类别标签;
根据X, Y,画出在X上,Y对应的标签值;
根据每个基分类器决策树的节点属性,属性划分点,画出对应的边界线;
按照书上图8.4的格式设置绘图格式,包括x,y轴范围,标签名等;
main函数,调用上述功能函数,输出预测准确率

-
实验结果

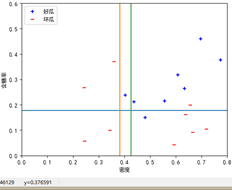
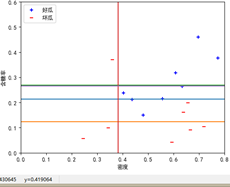


-
程序清单:
import math
import random as rd
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#单层决策树
class DTStump(object):
"""docstring for DTStump"""
def __init__(self, X, Y):
self.X = X
self.Y = Y
self.build()
# 叶节点选择其类别为D中样本最多的类
def choose_largest_example(self, X):
D = self.Y.loc[X.index]
Count = D.value_counts()
Max = -1
for key, value in Count.items():
if Max < value:
label = key
Max = value
return label
# 计算给定数据集的熵
def calc_Ent(self, X):
D = self.Y.loc[X.index]
numEntries = D.shape[0]
Count = D.value_counts()
Ent = 0.0
for key, value in Count.items():
#print(Count[key])
prob = Count[key] / numEntries
Ent -= prob * math.log(prob, 2)
return Ent
# 生成连续值属性的候选划分点集合T
def candidate_T(self, key, n):
L = set(self.X[key])
T = []
a, Sum = 0, 0
for value in L:
Sum += value
a += 1
if a == n:
T.append(Sum/n)
a, Sum = 0, 0
if a > 0:
T.append(Sum/a)
return T
# 计算样本D基于划分点t二分后的连续值属性信息增益
def calc_Gain_t(self, key, t, Ent_D):
Ent = 0.0
D_size = self.X.shape[0]
Dv = self.X.loc[self.X[key]<=t]
Dv_size = Dv.shape[0]
Ent_Dv = self.calc_Ent(Dv)
Ent += Dv_size/D_size * Ent_Dv
Dv = self.X.loc[self.X[key]>t]
Dv_size = Dv.shape[0]
Ent_Dv = self.calc_Ent(Dv)
Ent += Dv_size/D_size * Ent_Dv
return Ent_D - Ent
# 计算样本D基于不同划分点t二分后的连续值属性信息增益,找出最大增益划分点
def calc_Gain(self, key, Ent_D):
n = 2
T = self.candidate_T(key, n)
max_Gain, max_partition = -1, -1
for t in T:
Gain = self.calc_Gain_t(key, t, Ent_D)
if max_Gain < Gain:
max_Gain = Gain
max_partition = t
return max_Gain, max_partition
# 从A中选择最优的划分属性值,返回划分点
def build(self):
self.stump = {}
max_Gain = -1
for key in self.X.columns:
Ent_D = self.calc_Ent(self.X)
Gain, partition = self.calc_Gain(key, Ent_D)
if max_Gain < Gain:
best_attr = key
max_Gain = Gain
max_partition = partition
left = self.X.loc[self.X[best_attr] <= partition]
right = self.X.loc[self.X[best_attr] > partition]
if left.shape[0] == 0:
self.stump[0] = self.choose_largest_example(self.X)
else:
self.stump[0] = self.choose_largest_example(left)
if right.shape[0] == 0:
self.stump[1] = self.choose_largest_example(self.X)
else:
self.stump[1] = self.choose_largest_example(right)
self.attribute, self.partition = best_attr, max_partition
# print(self.attribute, self.partition, self.stump)
# 输入测试数据,输出预测标签类
def predict(self, X):
value = X[self.attribute]
if value <= self.partition:
return self.stump[0]
else:
return self.stump[1]
class Bagging(object):
"""docstring for Bagging"""
def __init__(self, iterate=3):
self.num = iterate
# 输入训练集数据和对应标签,训练集成学习器
def fit(self, X, Y):
size = X.shape[0]
weakClassers = [] #保存每次迭代器的信息
for _ in range(self.num):
indexs = [rd.randint(0, size-1) for _ in range(size)]
#indexs = [a for a in range(size)]
DX = pd.DataFrame(data=X.loc[indexs]).reset_index(drop=True)
DY = pd.Series(data=Y.loc[indexs]).reset_index(drop=True)
weakClasser = DTStump(DX, DY)
weakClassers.append(weakClasser) #保存每一轮的结果信息
self.weakClassers = weakClassers
return self
# 输入测试集,输出集成学习器预测预测的标签类,分类任务使用简单投票法
def predict(self, X):
predict_Y = []
for index, row in X.iterrows():
vote = {}
for weakClasser in self.weakClassers:
label = weakClasser.predict(row)
if label in vote:
vote[label] += 1
else:
vote[label] = 1
Max = -1
for label, num in vote.items():
if Max < num:
Max = num
vote_label = label
predict_Y.append(vote_label)
return predict_Y
#数据集
def loadData(filename):
dataSet = pd.read_csv(filename)
return dataSet
#绘制数据集
def pltDecisionBound(dataSet, clf):
X1 = np.array(dataSet[dataSet['好瓜']=='是'][['密度', '含糖率']])
X2 = np.array(dataSet[dataSet['好瓜']=='否'][['密度', '含糖率']])
x = np.linspace(0, 0.8, 100)
y = np.linspace(0, 0.6, 100)
for weakClasser in clf.weakClassers:
# print(weakClasser.attribute, weakClasser.partition)
z = [weakClasser.partition] * 100
if weakClasser.attribute == '密度':
plt.plot(z, y)
else:
plt.plot(x, z)
plt.scatter(X1[:,0], X1[:,1], marker='+', label='好瓜', color='b')
plt.scatter(X2[:,0], X2[:,1], marker='_', label='坏瓜', color='r')
plt.xlabel('密度')
plt.ylabel('含糖率')
plt.xlim(0, 0.8) # 设置x轴范围
plt.ylim(0, 0.6) # 设置y轴范围
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.legend(loc='upper left')
plt.show()
if __name__=='__main__':
filename = 'data_3a.txt'
dataSet = loadData(filename)
X, Y = dataSet[['密度', '含糖率']], dataSet['好瓜']
sizes = [3, 5, 11]
for size in sizes:
clf = Bagging(size)
clf = clf.fit(X, Y)
predict_Y = clf.predict(X)
accuracy = 0
for y1, y2 in zip(Y, predict_Y):
if y1 == y2:
accuracy += 1
print('Size:', size)
print('Accuracy:', accuracy, '/', Y.shape[0])
print('')
pltDecisionBound(dataSet, clf)