Logistics Regression
对于 线性回归
y=wz (将b写在了第0维 同时将x做特征转化 转化到z空间)
error = (y-wx)2
对于线性回归如果增加了 regression项 那么得到的就是ridge regression
对于ridge regression而言 其表达式为
minwλ/NwTw+1/2(y-wx)2
根据之前的推导 最佳的w可以表示为z的线性组合 即 w=∑nβnzn (1)
由之前推导可以得出 zmTzn 可以写成kernel的形式 K(xm,xn)
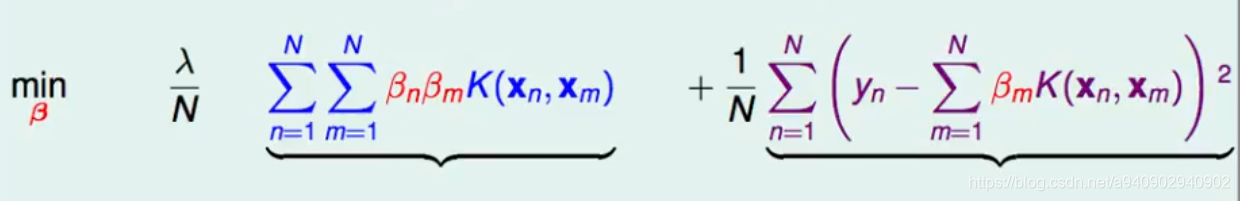
所以将原来的w的问题 转化为求解β的形式
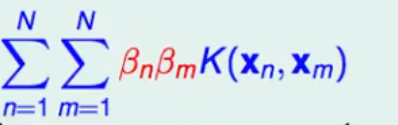
对于double summation 可以写成矩阵的 形式
βTKβ
对于βmK(xn,xm) 可以写成向量形式 Kβ
从Soft margin 出发
对于soft margin 而言 和 hard margin唯一的不同就是增加了一个 ζ,而ζ代表的是 margin violation (即违反margin的大小)
也就是说 对于support vector而言 违反的margin大小就是当前点的位置到原始边界的距离,如下图黑线所示
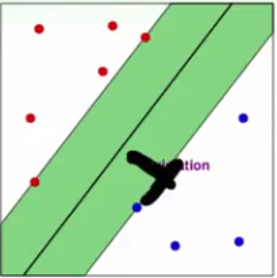
因此对于ζ 存在两种可能:
有违反margin的情况出现: ζ=1-yn(wxn+b)
如果对于点n没有违反margin 此时 ζ=0
所以ζ=max(1-yn(wxn+b),0)
SVM和L2regression的联系
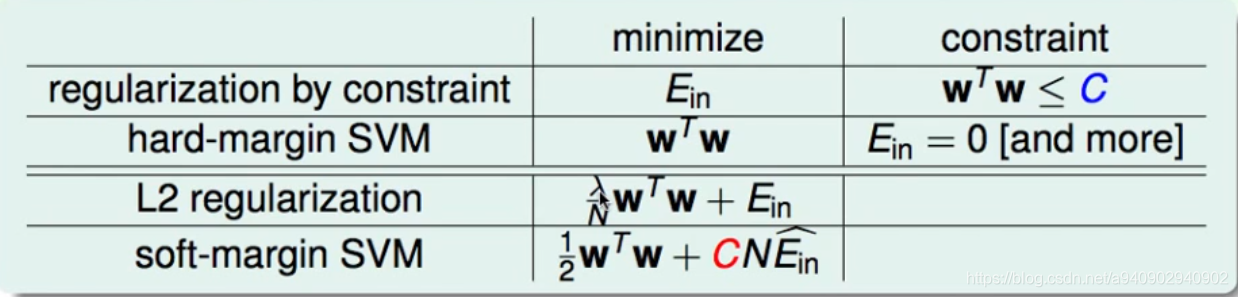
C越大 分类器越不能允许分类错误(离群点) C过大 分类器就会竭尽全力保证每个都不犯错 会造成过拟合
这和正则化中正则系数类似 λ越大正则项越大 表示会控制模型复杂度 防止过拟合
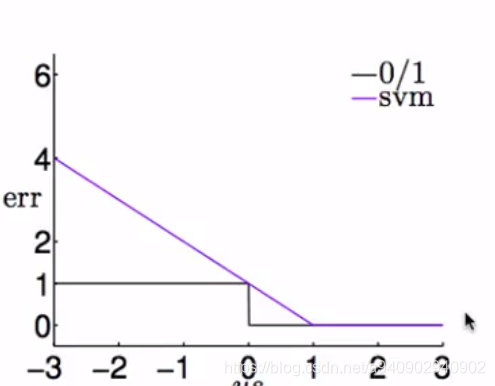
对于0,1损失
以y(wx+b) 为横轴(即y和分数的乘积) 如果它小于0 那么说明 y和wx+b 是异号的 损失为1 如果大于0 则说明是同号的 损失为1
同理对于上述推导的
ζ=max(1-yn(wxn+b),0)
如果 y(wx+b) 大于1 那么损失也是0 如果小于1 那么损失为 线性损失
SVM 和 logistics Regression结合
1.首先跑一个SVM 得到 w和b
2.将原始特征转化到SVM的特征空间 zn’=wsvmTΦ(x)+bsvm
3.得到 g(x)=θ(A zn’+B)
回想一下能够使用Kernel trick的原因是 能够写成两个向量的内积的形式 即
K<xn,x>
所以对于SVM和logistics regression 的组合 求得的w 如果能够写成一堆z的线性组合
W=∑nβnzn
那么WTZ=∑nβnznz=∑nβnK(xn,x)
由此可见 如果w可以写成z的线性组合 就能够使用kernel trick

那么什么时候w可以写成z的线性组合呢 ,这里可以证明 只要是存在wTw L2正则的项的最优w都可以写成 zn的线性组合
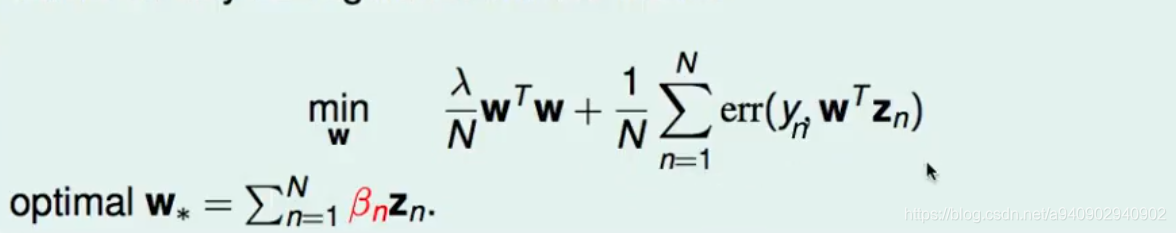
如果最优的w可以写成z的线性组合 那么 w应该是平行于z的 又因为在任意空间中 两个垂直的向量可以作为基底表示出空间中的全部向量
因此可以将最优w分解为垂直于∑zn的向量和平行于∑zn的向量
如果最优的w可以写成z的线性组合 垂直于