1、线性分类器
在说线性分类器之前,先思考一下我们平时是如何来做决策的。我们做任何决策之前,我们都会考虑很多因素,这里我们以决策树中经常举的相亲例子来进行说明。
假设,现在有人说要给你介绍个女朋友,你会问他,女孩多大了?性格如何?长得好看吗?我们会考虑三个因素:年龄是否匹配、性格优劣和长相好坏(是否又勾勾又丢丢),这里我们用三个二进制数表示这三个因素,三个因素对你决定去或者不去相亲的影响程度为
,这时,你会得到一个想去相亲的程度:
那么你到底去不去?我们会设定一个阈值,如果我想去的程度大于
我就去,反之,我不去,因此决策模型就变成了
为了表示的简洁性,我们可以将计为
,那么有:
将其表示成向量形式,令:
有:
这也即是我们所说的线性分类器,如果y大于0,我们就去,反之我们就不去。
2、 Logistics Regression
如果权重和b细小的变化只是轻微影响到输出
,那么我们可以逐步更改权重
和b,让模型按照我们想要的方式发展,这样就能得到一个理想的模型。
但是,这里存在一个问题,权重和b中任何一个参数微小变化都能使得模型输出结果彻底翻转,从0到1,因此引入sigmoid函数,来克服上述问题,使用sigmoid函数后,他会将y的值域由
映射到
, 权重
和b中任何一个参数微小变化只会微小的影响到输出结果。
sigmoid函数定义为:
3、计算图算梯度
在Andrew Ng的深度学习课程中,我第一次接触到计算图,然后就被其简单明了的表示方法所吸引,计算图简单明了的描述了在进行计算时,我们需要进行的每一步计算过程,思路十分清晰,且不容易造成错误。
在说Logistics Regression的计算图之前,我们先看一下一个简单的计算图例子,如图1所示。
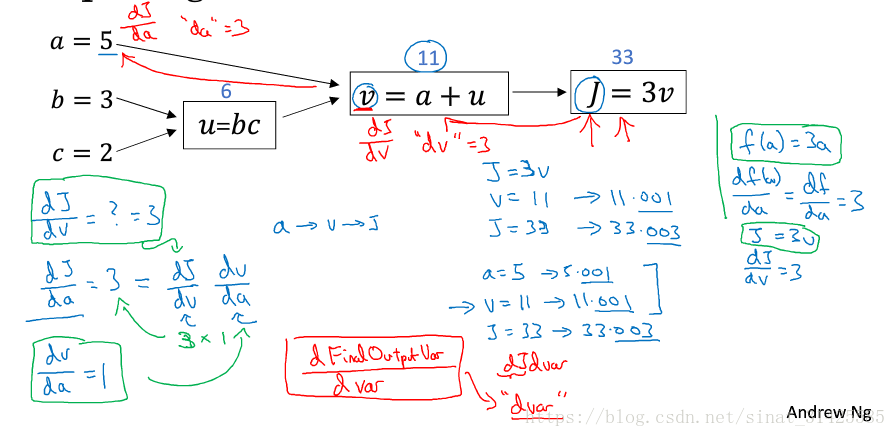
图1 计算图小例子(摘自参考资料[1])
我们已知三个变量a,b,c,而需要求解分别对于三个变量a,b,c的偏导,我们首先可以将计算J的步骤表示成计算图的形式(怎么样一步一步的通过对变量a,b,c操作,最后得到计算结果J),然后再基于计算图,一步一步的求解J对三个变量a,b,c的偏导。
举个例子,这里求J对a的偏导有:
1) 求J对隐变量v的偏导有:
2) 求v对变量a的偏导有:
所以,最终结果有:
这样,我们就能很清晰的得到需要求解偏导,同时,求解过程很符合我们的编程思路,有利于我们去实现这样一个求解偏导过程,其余两个变量偏导数求解就不做说明了。
我们再来看一看Logistics Regression的计算图,如图2所示。

图2 Logistics Regression 的计算图(摘自参考资料[1])
那么,我们再基于这个计算图来计算一个L分别对于对于的偏导:
1) 求L对a的偏导数有:
2) 求a对z的偏导数有:
3) 求z对的偏导数有:
同样的,求z对b的偏导数有:
这样,我们就可以得到L分别对于对于的偏导为:
采用计算图的方法使得求解过程瞬间变得清晰明了了,同时,也十分有利于编程。
4、Logistics Regression损失函数
这里其实还有一个问题,这里的损失函数L是如何得到的,为什么要采用这种形式的损失函数?其实,很简单,如果采用最常见的平方差损失来作为Logistics Regression的损失函数,在后面优化时,会出现损失函数非凸的情况,使得找到的最优解只是局部最优(局部极小值),而不是全局最优解,因此,Logistics Regression采用了一种等效形式:
这里,我们来进一步的看一看这个Loss function,当y=1时,有:
如果我们让L尽可能小,对应的就是让尽可能大,而
函数的值域为[0,1],那么其实优化L让其尽可能小的过程,其实就是在y=1时,让预测值尽可能让
的过程。
当y=0时,有:
如果我们让L尽可能小,对应的就是让尽可能大,等价于让
尽可能小,而
函数的值域为[0,1],那么其实优化L让其尽可能小的过程,其实就是在y=0时,让预测值尽可能让
的过程。
采用这种形式的损失函数还有一个好处,那就是这种损失函数是凸函数,局部极小值等价于全局极小值,求解得到的局部最优解即全局最优解。
5、代码实现
~~~~~未完待续~~~~~
参考资料:
[1] Andrew Ng deeplearning.ai课程