逻辑回归
从分类问题思考:线性回归与逻辑回归
分类问题
0:Negative class
1:Positive Class
二分类问题开始
将已知数据分类 0 1
采用算法 线性回归
假设函数 hx = theta0 + theta1*x1 + ... + thetaN * xN
设置阈值---什么情况下属于1类 or 0类
> 0.5 1
< 0.5 0
所有的点
对于分类问题应用线性回归并不是好办法
还有一个有趣的事情:
classification: 0 or 1
but 假设函数可以 大于1 or 小于0
接下来使用逻辑回归算法进行分类
logistic regression 逻辑回归
逻辑回归:实际上是一种分类算法
机器学习三要素 模型 策略 算法
逻辑回归假设函数 – 模型
logistic regression model
目标:
将假设函数值限定在[0,1]之中
如果 >= 0.5 属于 1类
反之 属于0类
want 0< hx < 1
逻辑回归的假设函数的表达式是什么?
逻辑回归的假设函数与线性回归的假设函数不同
带入了越阶函数 sigmoid function
线性回归hx = theta^T*x
逻辑回归hx = g(theta^T*x)
逻辑回归 – 从线性回归假设函数逐步优化
假设函数 : 逻辑回归的目标是分类 输出 0 or 1 引入 sigmoid function 即: 模型的解释 对于新输入样本x的y等于1的概率的估计值 即为:
也可以用概率公式来解释
总结:
逻辑回归的假设函数是什么
定义逻辑回归的假设函数的公式是什么
逻辑回归模型假设函数的推导
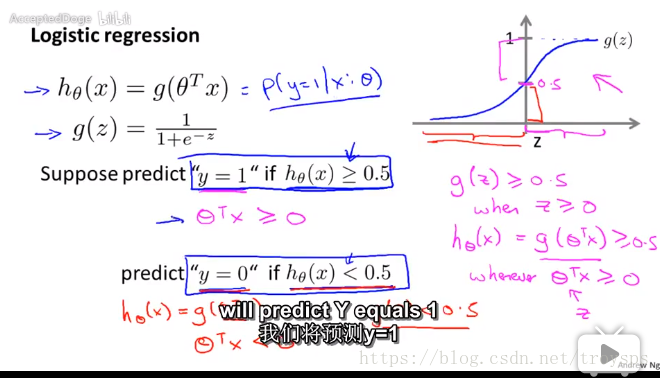
如何从解释该模型 模型转化的思路

决策边界
决策边界:假设函数在计算什么
目标:预测分类问题
suppose predict “y=1” if
即
“y=0” if
即
什么是决策边界
决策边界时假设函数的一个属性 包含
数据集 分平面
一旦确定
参数 决策边界就确定
决策边界可以是线性也可以是非线性
并不是用训练集来训练$\theta$ 而是拟合$\theta$
总结与思考: 什么范围内的假设函数可以选择
如何确定决策边界
非线性的决策边界

逻辑回归的代价函数
traning set
m examples x 属于 [x_0, x_1,…,x_n].T
逻辑回归的假设函数为:
线性回归的代价函数
linear regression cost function :
可以推导为:
即为:
由于 为复杂线性函数 开平方推导会造成非凸函数以及局部优化
因此 期望是 凸函数
可得逻辑回归的代价函数为
特性:当y=1时 if
cost=0
else:
代价函数无穷大
当y=0时 if
代价函数无穷大
else cost=0
代价函数作为惩罚系数
逻辑回归代价函数 推导1

逻辑回归代价函数 推导2 凸函数与非凸函数

逻辑回归代价函数 推导3

Simplified cost function and gradient descent
化简代价函数及梯度下降法
——问题 如何使用梯度下降法拟合函数
——线性回归和逻辑回归是一个梯度下降算法么
——如何检测梯度下降 确保他是收敛的
将代价函数再化简
Note! y=0 or 1 always
将代价函数优化为1行
即:
问题:如何不断的拟合 期望为 最小化代价函数 — 使得拟合模型
易于分类
目标 对新的输入变量x输出正确的预测
下一步目标 如何最大限度最小化代价函数 — 向量化实现



下一步目标 如何最大限度最小化代价函数 — 向量化实现
采用梯度下降法
want
:
问题: 线性回归和逻辑回归是一个梯度下降算法么
完全不是 两者的假设函数不同
问题: 如何监测梯度下降 确保它收敛
带入了代价函数 偏导数 实质上 会想最优或者局部最优点梯度下降
小结: 假设函数 sigmoid
代价函数 化简 -- 非凸性函数转化为凸性函数
梯度下降法
高级优化算法 optimization algorithm
代价函数
目标 最小化代价函数
给定
用计算机实现计算
—
代价函数
—$代价函数的偏导数 确保收敛性—计算代价函数 及代价函数的收敛性
梯度下降法
除了梯度下降法 还有
共轭梯度法 conjugate gradient
变尺度法 BFGS
限制尺度法 L-BFGS
这些算法都是对代价函数的不同优化
优点: 不需要手动计算学习速率
收敛速度快于梯度下降法
缺点:
过于复杂
obtave 如何使用梯度下降法计算

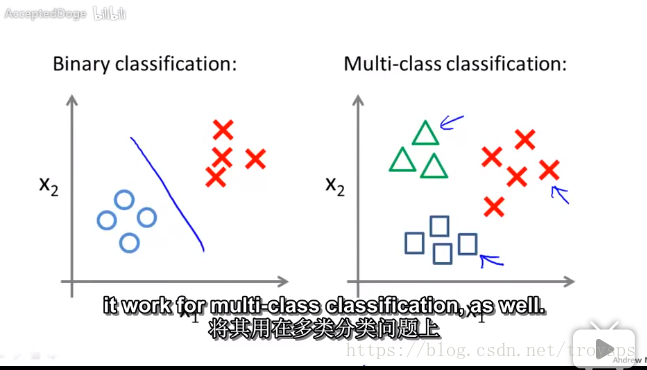
多分类问题
本质上来说 求得是 $\max p(y=i|x_i, \theta) i=1,2,3....$
概率最大化问题
参考文献
斯坦福 机器学习课程 吴恩达