转载请注明链接:http://blog.csdn.net/Cracked_hitter/article/details/78888491
该系列文章为对Andrew Ng老师ML视频的学习笔记。主要是对其中的知识做一些梳理,并加入自己的一些理解与公式的推导。文章记录的并不详细,只对一些知识的要点进行整理。可能文章中会有不当之处,也希望各位在阅读过程中不吝赐教。
一、问题引入
在机器学习领域,有很大一部分问题为分类问题,例如垃圾邮件的分类,贷款风险的分类等等。本文中将要介绍的logistics regression是常用在分类问题中的一种方法,其理解与实现都比较简单。假设我们在预测肿瘤是否恶化的问题时,根据肿瘤的大小,标记处出了一系列的样本点。
我们可以一条直线将是否为恶性肿瘤分割成两部分,我们的预测函数仍为h(theta).当h(theta)>0.5时判定为恶性肿瘤,反之则非恶性.我们把这种分类问题成为logistics regression。
二、假设函数(Hypothesis )和误差函数(CostFunction)
1.假设函数
这里我们引入sigmod函数,
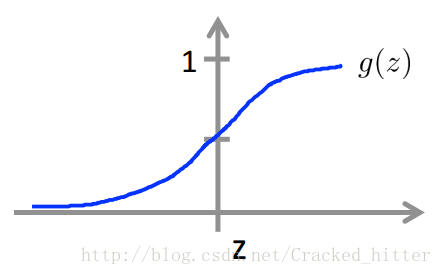
当z>0时,g(z)>0.5;当z<0时,g(z)<0.5
我们将z替换为
则我们的分类问题变成了,当
并且
有了预测函数之后,我们接下来要做的就变成了通过算法来改变
2.误差函数
如要想要寻找到最适合的权重矩阵
二进制分类问题的误差函数,实际上就是一种极大似然函数的对数形式。所以logistics问题则可以认为是一种极大似然估计的问题。这里我们不直接以极大似然函数来给出这个误差函数
我们先以分段函数来给出其误差函数的形式,以及它们的取值。
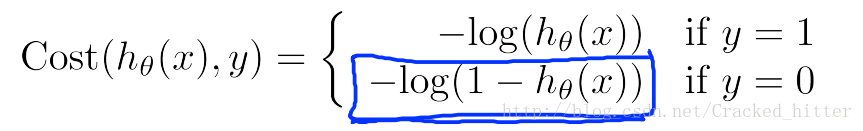
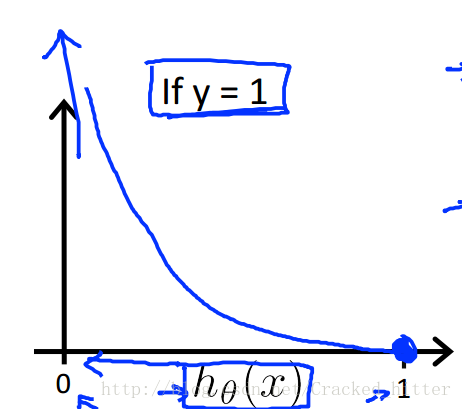
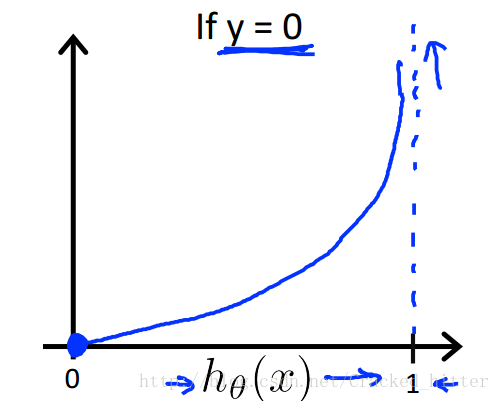
可以看出,当
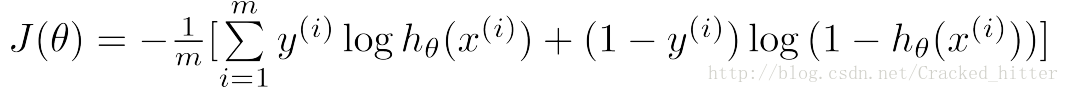
PS:去掉
三、梯度下降
用计算机来对极大似然函数求极值的问题,常用的为梯度下降的方法。即对误差函数求梯度,在其梯度方向以一个学习速率
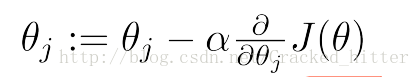
以算法的形式来表示类似于linear regression的梯度函数的形式

注意:以矩阵进行运算,同步的更新权重矩阵
在这里也给出了一些相较于梯度下降更高级的算法以及它的优缺点,如下

四、One Vs All 分类问题
当利用该方法来求解多类别的分类问题时,我们尝试将其中一个类别作为我们待分类的类别,其余的归为一类。这样就将问题转换成了二进制的logistics问题。
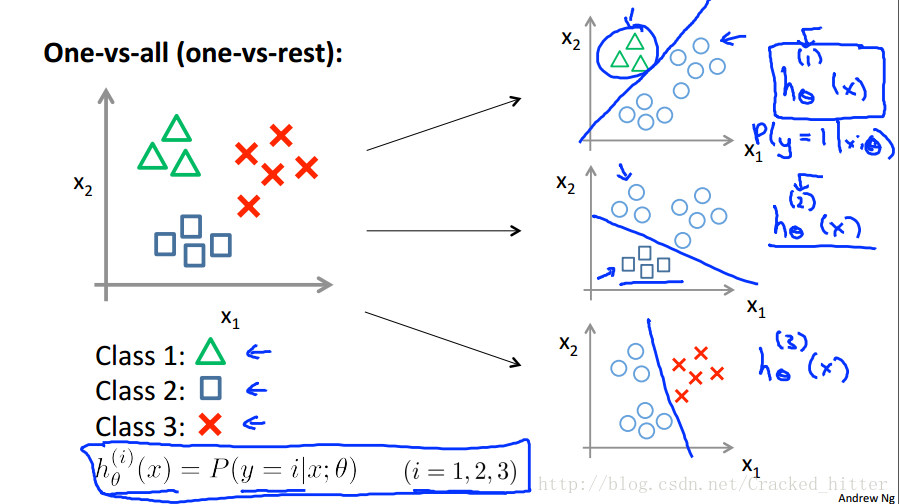

如上图,当我们有一个新的输入
五、正则化
在logistics问题中,仍会存在过拟合的问题或欠拟合的问题,如下第一张图为欠拟合,这样会存在较大的误差;而如图三的情况则为过拟合的情况
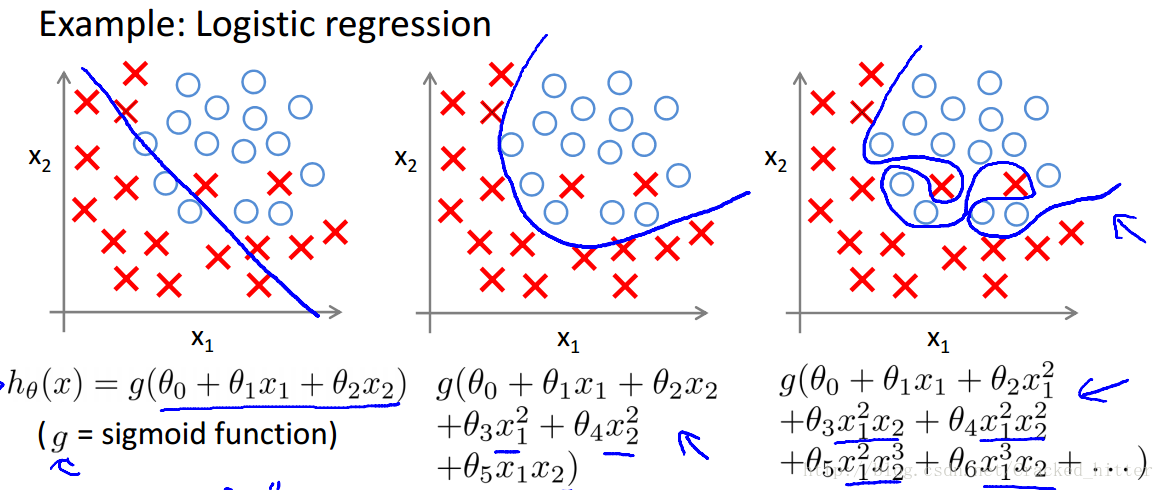
防止过拟合的方法主要有:
1.减少特征的数量
①.手动选择想要保留的变量
②.模型选择算法
2.正则化
①.保留所有的变量,加入”惩罚项”,来减小
②.当我们拥有很多的特征变量,并且每种特征变量对预测函数的贡献都不大,这种情况下使用正则化效果较好
正则化误差函数表示:
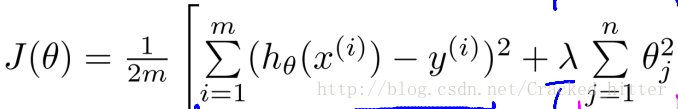
正则化梯度下降公式: