import numpy as np
def sigmod(z):
return 1/(1+np.exp(-z)
def gradAscent(data,label):
dataMatrix=np.mat(data)
classLabels=mat(label).transpose()
m,n = shape(dataMatrix)
a=0.001 #梯度幅度
maxCycles=500 #迭代次数
weights = ones((n,1))
for i in range(maxCycles):
h=sigmod(dataMatrix*weights)
error = label-h
weight=weight+a*error* dataMatrix.transpose()
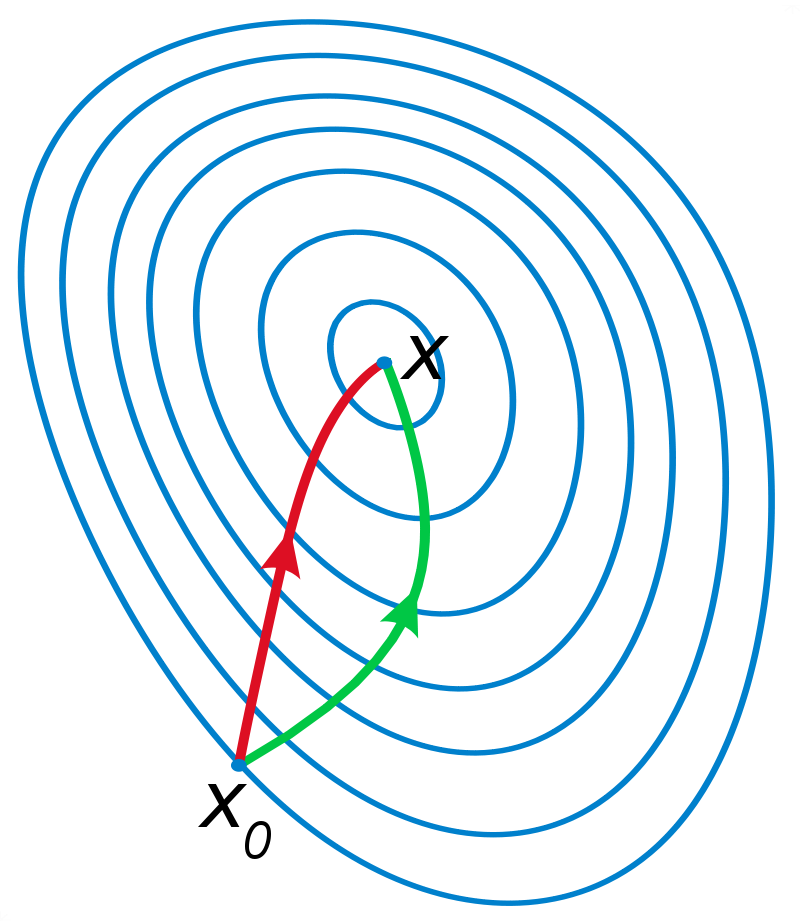
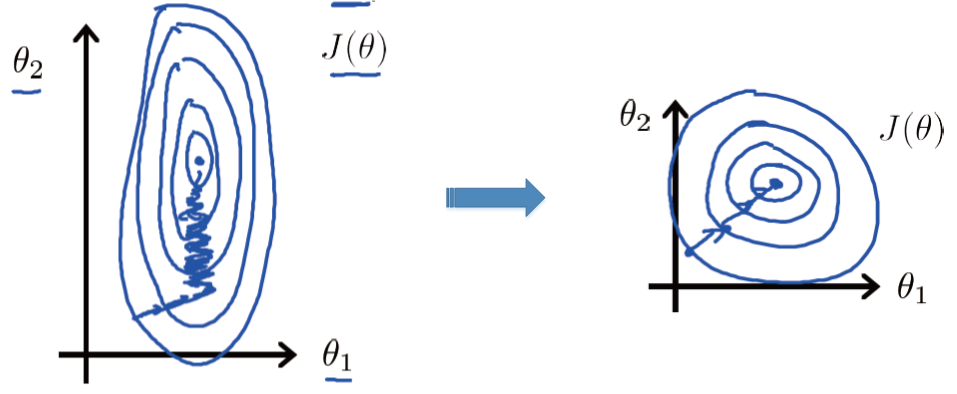
return array(weights)由于处理的数据有不同的量纲和量纲单位,导致不同维度的数据之间尺度差异很大,如下图(左)所示,目标函数的等高线是椭圆形的。这样在通过最小化目标函数寻找最优解的过程中,梯度下降法所走的路线是锯齿状的,需要经过的迭代次数过多,严重影响了算法的效率。
为了解决这个问题,可以对数据进行归一化,例如采用min-max标准化将输入数据范围统一到[0,1]之间,处理后的结果如上图(右)所示,经过很少次数的迭代就可以达到目标函数的最低点,极大提高算法的执行效率。
2. 牛顿法
数据归一化是从数据预处理的角度解决梯度下降法迭代次数过多这个问题的,若从目标函数优化的角度去思考,可以用牛顿法替代梯度下降法,从而提高参数最优值的求解速度。
有n个变量的函数J(θ)J(θ)的一阶导数为:
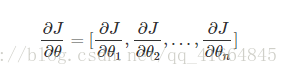
二阶导数(也称为Hessian矩阵)为:

目标函数J(θ)J(θ)的包含二阶导数的泰勒展开式为:
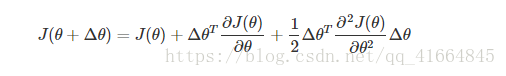
将J(θ+Δθ)J(θ+Δθ)看做ΔθΔθ的函数的话,其最小值在其偏导数等于0处取得:
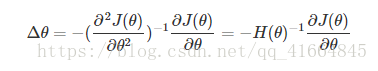
θ+Δθθ+Δθ是对目标函数取得最小值时参数的一个较好的估计,在牛顿法中会在ΔθΔθ的基础上乘以一个步长αα(取值小于1,比如0.001)。 使用牛顿法迭代过程为:
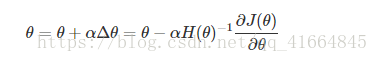
for i in xrange(0, num_passes):
Jprime = X_expand.T.dot(sigmoid(X_expand.dot(theta))-y.reshape(X.shape[0],1))
for j in xrange(0, num_examples):
H_theta = sigmoid(X_expand[j,:].dot(theta))
A[j,j] = H_theta*(1-H_theta) + 0.0001
Jprime2 = X_expand.T.dot(A).dot(X_expand)
delta_theta = np.linalg.solve(Jprime2,Jprime)
delta_theta += reg_lambda*theta
theta += -al*delta_theta
return theta