10.10 条件变分自编码器
前面的变分自解码器是为了本节条件变分自解码器做铺垫的,在实际应用中条件变分自解码器会更为广泛一些,具体的内容如下。
10.10.1 什么是条件变分自编码器
变分自编码器存在一个问题,虽然可以生成一个样本,但是只能输出与输入图片相同类别的样本。虽然我们也可以在随机从符合模型生成的高斯分布中取数据来还原成样本,但是这样我们并不知道生成的样本属于哪个类别。条件变分解码器可以解决这个问题,让网络按你所指定的类别生成样本。
在变分自编码器的基础上,再去理解条件变分自编码器会很容易。主要的改动是在训练、测试时,加入一个one-hot向量,用于表示标签向量。其实,就是给变分自解码网络加了一个条件,让网络学习图片分布时加入了标签因素,这样可以按照标签的数值来生成指定的图片。
10.10.2 实例83:使用标签指导变分自编码网络生成MNIST数据
了解完原理,再来介绍下具体做法,在编码阶段需要在输入端添加标签对应的特征。在解码阶段同样也需要将标签加入输入,这样,再解码的结果向原始的输入样本不断的逼近,最终得到的模型,将会把输入的标签特征当成MNIST数据的一部分,就实现了通过标签来生成MNIST数据的效果。
在输入端添加标签时,一般是通过一个全连接层的变换将得到结果contact到原始输入的地方,在解码阶段也将标签作为样本输入,与高斯分布的随机值一并运算,生成模拟样本。
结构如图10-21所示。
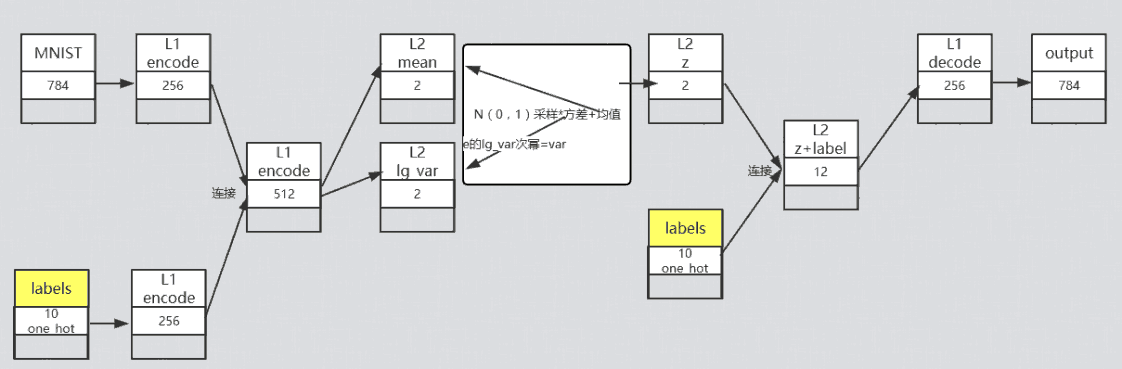
图10-21条件变分自解码结构
具体代码步骤如下。
案例描述
使用条件变分自编码模型实现通过指定标签输入生成对应类别的MNIST模拟数据。
1 添加标签占位符
在“10-8变分自编码器.py”代码基础上修改,添加占位符y。
代码10-9 条件变分自编码器

2 添加输入全连接权重
添加全连接层的权重'wlab1'与'blab1',作为输入标签的特征转换。这里输入的标签也转换成256个输出,因为最终要连接到原始的图片全连接输出,所以到第二层全连接时,输入就变成了256×2,于是也需要将mean_w1和log_sigma_w1的输入修改成n_hidden_1×2。
代码10-9 条件变分自编码器(续)
同样,对于生成的z也要与label连接后输入加码器,所以w2的输入维度需要被改成n_hidden_2+n_labels。
3.修改模型,将标签输出接入编码定义新节点hlab1为输入标签的输出,接着将它与原来的h1用concat函数合并到一起,变成hall1。此时,hall1的shape为[batch_size,n_hidden_1×2]。接着,将合成好的hall1代替原来的h1输入z_mean与z_log_sigma_sq中。
代码10-9 条件变分自编码器(续)


4.修改模型将标签接入解码
中间的z不用变化,在z之后同样连接上y的特征,一起输入到解码器中。这里需要把reconstruction和reconstructionout节点同时修改,一个用来训练,一个用来生成。
代码10-9 条件变分自编码器(续)

对于优化器方面不用变化,直接修改session的feed部分即可,在feed中加入标签占位符及对应的数据。
代码10-9 条件变分自编码器(续)
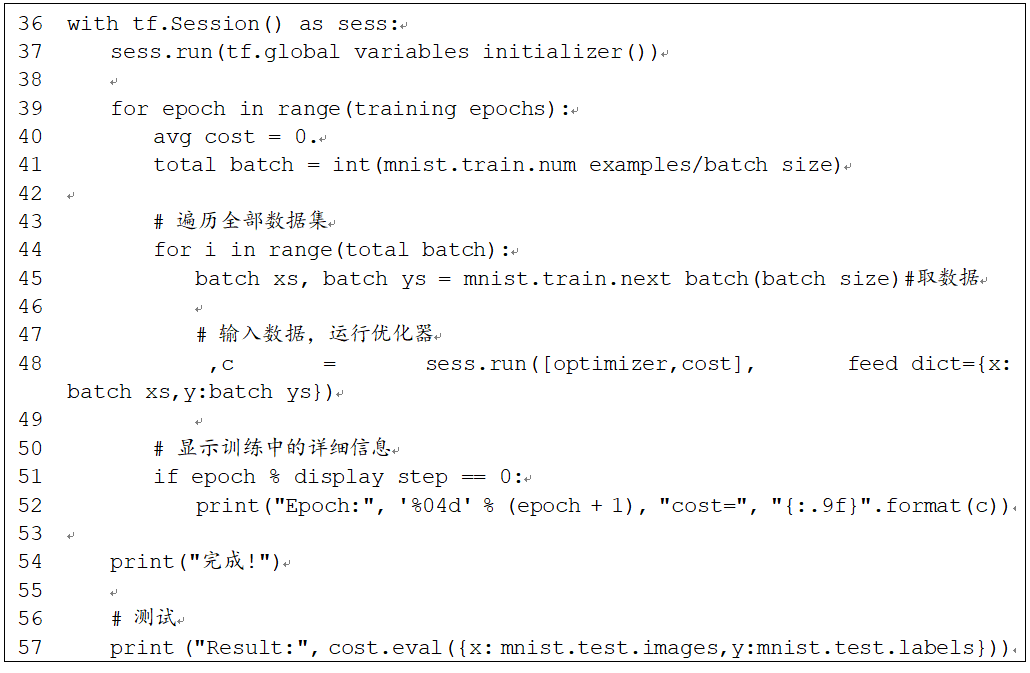
这是最有意思的部分了。随便生成个高斯分布随机数,并通过指定的one_hot输入标签,就可以命令模型生成指定的MNIST图片数据了。
代码10-9 条件变分自编码器(续)

上面代码取了10个测试样本数据,将样本数据的label与随高斯分布值z_sample一起生成了模拟MNIST数据。运行代码,生成如图10-22、图10-23所示的图例。
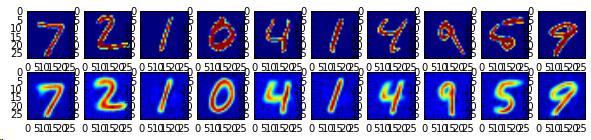
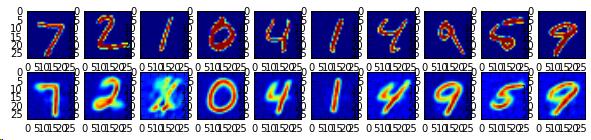
图10-23为根据label生成的模拟数据,第一行为label对应的原始数据,第二行为解码器生成的模拟数据。
比较两幅图片可以看出,使用原图生成的自编码数据还会带有一些原来的样子,而以标签生成的解码数据,已经测底的学会了数据的分布,并生成截然不同却带有相同意义的数据。
更多章节请购买《深入学习之 TensorFlow 入门、原理与进阶实战》 全本
10.10 条件变分自编码器
前面的变分自解码器是为了本节条件变分自解码器做铺垫的,在实际应用中条件变分自解码器会更为广泛一些,具体的内容如下。
10.10.1 什么是条件变分自编码器
变分自编码器存在一个问题,虽然可以生成一个样本,但是只能输出与输入图片相同类别的样本。虽然我们也可以在随机从符合模型生成的高斯分布中取数据来还原成样本,但是这样我们并不知道生成的样本属于哪个类别。条件变分解码器可以解决这个问题,让网络按你所指定的类别生成样本。
在变分自编码器的基础上,再去理解条件变分自编码器会很容易。主要的改动是在训练、测试时,加入一个one-hot向量,用于表示标签向量。其实,就是给变分自解码网络加了一个条件,让网络学习图片分布时加入了标签因素,这样可以按照标签的数值来生成指定的图片。
10.10.2 实例83:使用标签指导变分自编码网络生成MNIST数据
了解完原理,再来介绍下具体做法,在编码阶段需要在输入端添加标签对应的特征。在解码阶段同样也需要将标签加入输入,这样,再解码的结果向原始的输入样本不断的逼近,最终得到的模型,将会把输入的标签特征当成MNIST数据的一部分,就实现了通过标签来生成MNIST数据的效果。
在输入端添加标签时,一般是通过一个全连接层的变换将得到结果contact到原始输入的地方,在解码阶段也将标签作为样本输入,与高斯分布的随机值一并运算,生成模拟样本。
结构如图10-21所示。
图10-21条件变分自解码结构
具体代码步骤如下。
案例描述
使用条件变分自编码模型实现通过指定标签输入生成对应类别的MNIST模拟数据。
1 添加标签占位符
在“10-8变分自编码器.py”代码基础上修改,添加占位符y。
代码10-9 条件变分自编码器
2 添加输入全连接权重
添加全连接层的权重'wlab1'与'blab1',作为输入标签的特征转换。这里输入的标签也转换成256个输出,因为最终要连接到原始的图片全连接输出,所以到第二层全连接时,输入就变成了256×2,于是也需要将mean_w1和log_sigma_w1的输入修改成n_hidden_1×2。
代码10-9 条件变分自编码器(续)同样,对于生成的z也要与label连接后输入加码器,所以w2的输入维度需要被改成n_hidden_2+n_labels。
3.修改模型,将标签输出接入编码定义新节点hlab1为输入标签的输出,接着将它与原来的h1用concat函数合并到一起,变成hall1。此时,hall1的shape为[batch_size,n_hidden_1×2]。接着,将合成好的hall1代替原来的h1输入z_mean与z_log_sigma_sq中。
代码10-9 条件变分自编码器(续)
4.修改模型将标签接入解码
中间的z不用变化,在z之后同样连接上y的特征,一起输入到解码器中。这里需要把reconstruction和reconstructionout节点同时修改,一个用来训练,一个用来生成。
代码10-9 条件变分自编码器(续)
对于优化器方面不用变化,直接修改session的feed部分即可,在feed中加入标签占位符及对应的数据。
代码10-9 条件变分自编码器(续)
这是最有意思的部分了。随便生成个高斯分布随机数,并通过指定的one_hot输入标签,就可以命令模型生成指定的MNIST图片数据了。
代码10-9 条件变分自编码器(续)
上面代码取了10个测试样本数据,将样本数据的label与随高斯分布值z_sample一起生成了模拟MNIST数据。运行代码,生成如图10-22、图10-23所示的图例。
图10-23为根据label生成的模拟数据,第一行为label对应的原始数据,第二行为解码器生成的模拟数据。
比较两幅图片可以看出,使用原图生成的自编码数据还会带有一些原来的样子,而以标签生成的解码数据,已经测底的学会了数据的分布,并生成截然不同却带有相同意义的数据。
更多章节请购买《深入学习之 TensorFlow 入门、原理与进阶实战》 全本