博主的其他平台:博客园
自动编码器的结构
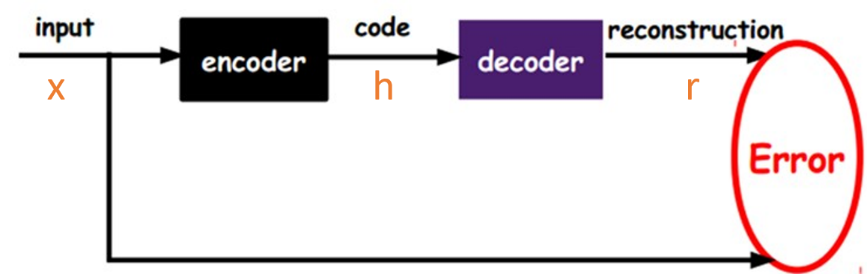
自动编码器包括编码器和解码器。编码器对编码,解码器解码,作用跟主成分分析PCA类似,效果更好。编码器可以将高维度降到一维或其他维度。解码器进行解码,载跟原始数据对比计算损失函数。
实际我们只使用到编码器的输出,也就是降维后的特征,然后送入监督学习训练模型。
下面的代码是用编码器将fashion-mnsit降到一维,然后在感知机上训练分类模型。
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import transforms, datasets
np.random.seed(123)
torch.manual_seed(123)
LR = 0.0001
#编码器输出潜在向量的长度
HIDDEN_SIZE = 128
epochs = 20
#如果有gpu,就调用gpu
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
train_dataset = datasets.FashionMNIST('./data/', True, transforms.ToTensor(), download=False)
test_dataset = datasets.FashionMNIST('./data/', False, transforms.ToTensor())
train_loader = DataLoader(train_dataset, 256, True)
test_loader = DataLoader(test_dataset, 256, False)
#定义感知机,用于分类
num_inputs, num_outputs, num_hiddens = HIDDEN_SIZE, 10, 256
mlp = nn.Sequential(
nn.Linear(num_inputs, num_hiddens),
nn.ReLU(),
nn.Linear(num_hiddens, num_outputs),
).to(device)
#定义自编码器AE
class AutoEncoder(nn.Module):
def __init__(self):
super(AutoEncoder, self).__init__()
self.en_conv = nn.Sequential(
nn.Conv2d(1, 16, 4, 2, 1),
nn.BatchNorm2d(16),
nn.Tanh(),
nn.Conv2d(16, 32, 4, 2, 1),
nn.BatchNorm2d(32),
nn.Tanh(),
nn.Conv2d(32, 16, 3, 1, 1),
nn.BatchNorm2d(16),
nn.Tanh()
)
self.en_fc = nn.Linear(16*7*7, HIDDEN_SIZE)
self.de_fc = nn.Linear(HIDDEN_SIZE, 16*7*7)
self.de_conv = nn.Sequential(
nn.ConvTranspose2d(16, 16, 4, 2, 1),
nn.BatchNorm2d(16),
nn.Tanh(),
nn.ConvTranspose2d(16, 1, 4, 2, 1),
nn.Sigmoid()
)
def forward(self, x):
en = self.en_conv(x)
code = self.en_fc(en.view(en.size(0), -1))
de = self.de_fc(code)
decoded = self.de_conv(de.view(de.size(0), 16, 7, 7))
return code, decoded
#实例化模型,送到device
net = AutoEncoder().to(device)
#编码器训练
def AutoEncoder_train():
#开启模式
net.train()
#定义自编码器的优化器和损失函数
optimizer = torch.optim.Adam(net.parameters(), lr=LR,weight_decay=5e-6)
loss_f = nn.MSELoss()
#训练
for epoch in range(1, epochs+1):
for step, (data, label) in enumerate(train_loader):
data = data.to(device)
net.zero_grad()
code, decoded = net(data)
loss = loss_f(decoded, data)
loss.backward()
optimizer.step()
print('AutoEncoder epoch [%d/%d] loss:%.4f'%(epoch, epochs, loss))
#开启预测模式,使每次预测结果都是确定性的
net.eval()
#利用编码器得到的特征训练感知机
def train():
#训练自编码器
AutoEncoder_train()
#训练mlp
print('\nmlp training....................\n')
#定义感知机的优化器和损失函数
optimizer = torch.optim.Adam(mlp.parameters(), lr=LR)
loss = torch.nn.CrossEntropyLoss()
#训练mlp
for epoch in range(1, epochs+1):
#启动训练模式
mlp.train()
for step, (data, label) in enumerate(train_loader):
data = data.to(device)
label = label.to(device)
mlp.zero_grad()
#利用编码器输出的向量作为提取特征进行训练模型
code, decoded = net(data)
output = mlp(code)
l = loss(output, label)
l.backward()
optimizer.step()
print('mlp : eoch: [%d/%d], '%(epoch, epochs), end='')
#测试本次epoch后的训练集精度和损失
test(test_loader)
#测试感知机的精度
def test(data_loader):
#开启模型预测模式
mlp.eval()
#定义交叉熵损失函数
loss = torch.nn.CrossEntropyLoss()
acc_sum, n, loss_sum = 0, 0, 0.0
for step, (data, label) in enumerate(data_loader):
data = data.to(device)
label = label.to(device)
code, decoded = net(data)
output = mlp(code)
l = loss(output, label)
#计算预测精度和损失
acc_sum += (output.argmax(dim=1)==label).float().sum().item()
n += label.shape[0]
loss_sum +=l
print('acc:%.2f%% loss:%.4f' %(100*acc_sum/n, loss_sum/(step+1)))
if __name__ == '__main__':
train()
print('模型的测试精度: ', end='')
test(test_loader)
运行结果入下:
