自编码器AutoEncoder是一种尽可能复现输入信号的神经网络。为了实现这种复现,自动编码器就必须捕捉可以代表输入数据的最重要的因素,就像PCA那样,找到可以代表原信息的主要成分。
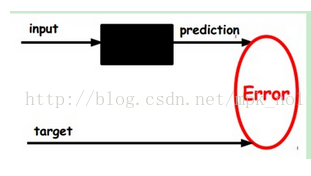
神经网络,例如多层感知机中,输入经过隐层变换之后,得到一个输出,然后计算与target(或label)之间的差异去改变前面各层的参数,直到收敛,这个过程就是著名的BP网络思想,如上图所示。但是自动编码器与之不同的是,我们没有target,那么怎么训练呢?
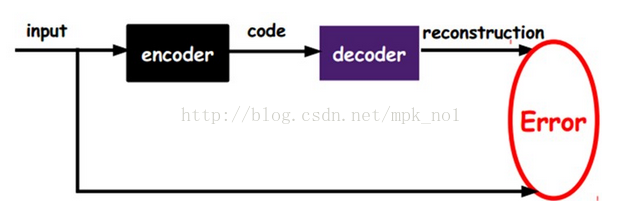
如上图所示,自动编码器AutoEncoder中将输入input输入一个编码器encoder,得到一个中间的向量表示code,这个code也就是输入的一个表示,那我们怎么知道code表示的就是input呢?我们将code输入到解码器decoder中,得到一个输出,如果这个输出与输入input很像的话,那我们就可以相信这个中间向量code跟输入是存在某种关系的,也就是存在某种映射,那么这个中间向量code就可以作为输入的一个特征向量。我们通过调整encoder和decoder的参数,使得输入和最后的输出之间的误差最小,这时候code就是输入input的一个表示。
将自动编码器应用到有监督的分类任务:
当然,上面的训练过程是无监督的,因为输入和最终的target都是输入input,我们可以通过训练来得到输入的一个向量表示。如果想要将AutoEncoder应用到有监督的分类任务中,则可以采用下面的结构:
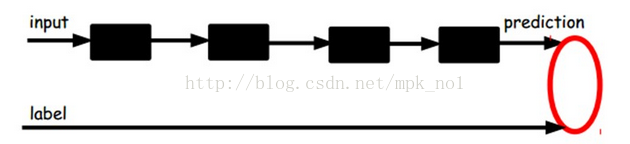
输入input可以经过多层encoder-decoder得到向量表示,然后可以在最后一层添加一个分类器,例如逻辑回归、SVM、随机森林,或者神经网络中的softmax。通过有标签的样本可以训练调整整个网络中的参数,AutoEncoder过程可以通过有监督的训练过程调整参数,也可以不调整。
稀疏自动编码器Sparse AutoEncoder:
通过在AutoEncoder的基础上加上L1正则化(L1主要用来约束每一层中的结点中大部分都为0,只有少数不为0),就得到了稀疏自动编码器。
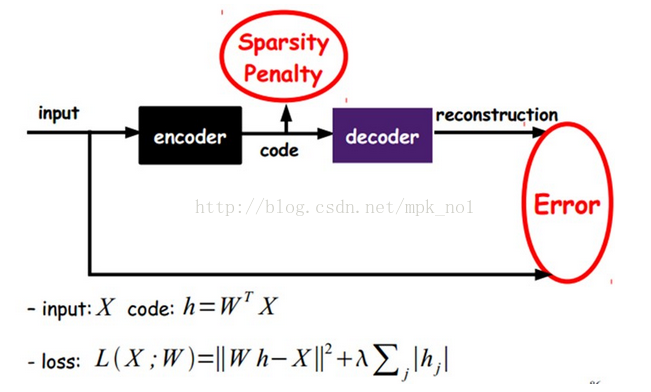
如上图所示,稀疏AE就是限制每次得到的表达code尽量稀疏。这往往可以得到更有效的表达。
KATE: K-Competitive Autoencoder for Text(一种改进的自动编码器应用,得到文本的向量表示 KDD2017)
KATE: K-Competitive Autoencoder for Text是KDD2017的一篇paper,文章利用了一种改进的AutoEncoder来得到文档或句子的向量表示。
训练过程如下所示:

与AE不同的是第3步,这里对得到的中间code进行了一个K-Competitive的操作,其思想是,Encoder得到中间向量code的过程中,神经元之间的权重是不一样的,有些神经元重要,有些神经元不重要,所以作者让这些神经元进行竞争来学习得到输入的一个模板表达,其中,选择经过激活函数得到z中最具竞争力的k个神经元(神经元的取值绝对值最大的k个)作为胜利者,其余的作为失败者,胜利者中又分为positive胜利者和Negative胜利者,pos 胜利者得到取值为正的失败者神经元的能量,neg胜利者得到取值为负的失败者神经元的能量,如下图所示:
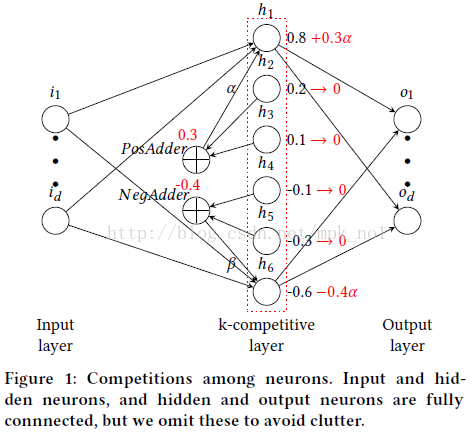
这样就对神经元的能量进行了再分配,使得重要的神经元得到了加强,不重要的神经元失活。
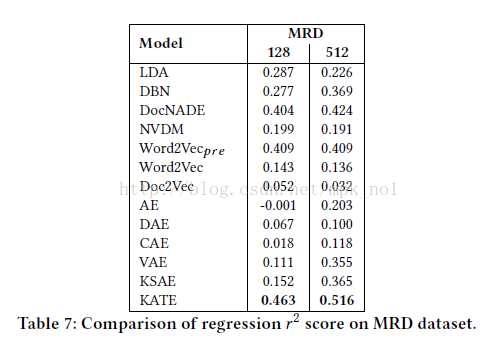
作者论文中的实验表示,用KATE得到的文档向量表示比用LDA、doc2vec、AE等方法得到的效果更好:
KATE的GitHub地址为:https://github.com/hugochan/KATE
从我自己的使用效果来看,KATE得到文档或句子向量的效果确实还不错,至少比doc2vec要好一些,其他方法得到的文档或句子向量的效果怎么样由于我没有实现过,所以不做评论。