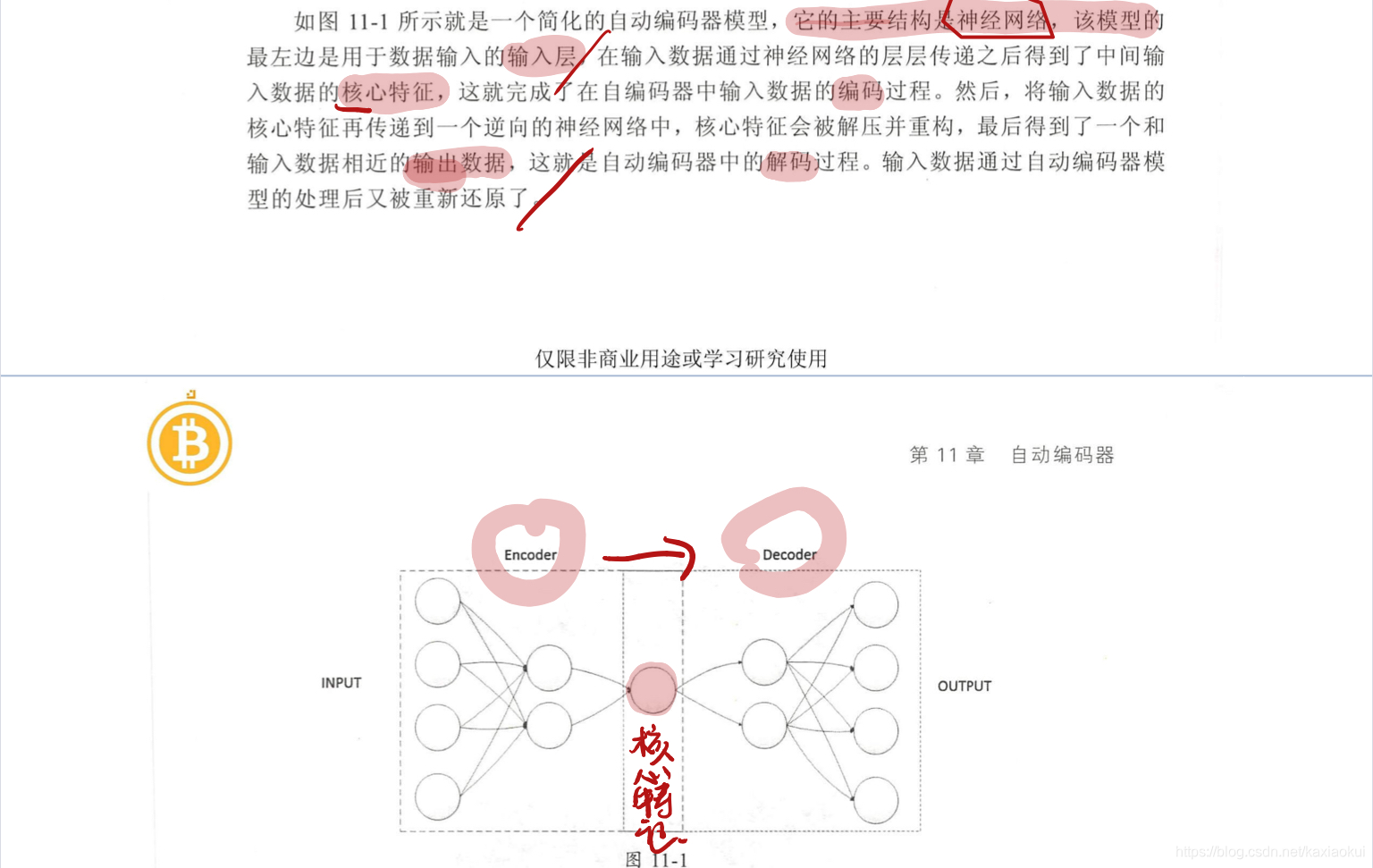
自动编码器原理
自动编码器:无监督学习的神经网络模型
两部分:核心特征提取的编码部分
实现数据重构的解码部分
作用:实现数据的清洗,比如去除噪声数据,或者对数据的关键特征进行放大或增强
实现流程:输入数据----------编码------核心特征------解码------输出
自动编码实战
使用自动编码器实现去除图片马赛克问题:
生成一个带马赛克的图片(给图片加噪声):
主要代码:
# 给图像加噪声 实现打码操作
noisy_images = images_example + 0.5 * np.random.randn(*images_example.shape)
# 这里要加一个* ?? 不然会报元组不能加到整形的错误
noisy_images = np.clip(noisy_images,0.,1.)
# 由于原始的MNSIT的数据集图像的像素范围是(0,1),因此加噪后要转回(0,1)
编码解码代码:
# 搭建网络进行编解码 线性变换的 仅使用线性映射和激活函数作为网络结构的主要部分
class AutoEncoder(torch.nn.Module):
def __init__(self):
super(AutoEncoder, self).__init__()
self.encoder = torch.nn.Sequential(
torch.nn.Linear(28 * 28, 128),
torch.nn.ReLU(),
torch.nn.Linear(128, 64),
torch.nn.ReLU(),
torch.nn.Linear(64, 32),
torch.nn.ReLU())
self.decoder = torch.nn.Sequential(
torch.nn.Linear(32, 64),
torch.nn.ReLU(),
torch.nn.Linear(64, 128),
torch.nn.ReLU(),
torch.nn.Linear(128, 28 * 28))
def forward(self, input):
output = self.encoder(input)
output = self.decoder(output)
return output
model = AutoEncoder()
# print (modle)
全部实现代码
import torch
import torchvision
from torchvision import datasets, transforms
from torch.autograd import Variable
import numpy as np
import matplotlib.pyplot as plt
# 数据预处理
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize(mean = [0.5],std = [0.5])])
# 注意到MNIST数据集的图像是灰度图像,单通道
# 数据读取
dataset_train = datasets.MNIST(root = './data',
transform = transform,
train = True,
download = True)
dataset_test = datasets.MNIST(root = './data',
transform = transform,
train = False)
# 数据载入
train_load = torch.utils.data.DataLoader(dataset = dataset_train,batch_size = 4,shuffle = True)
test_load = torch.utils.data.DataLoader(dataset = dataset_test,batch_size = 4,shuffle = True)
# 数据可视化
images, label = next(iter(train_load))
print(images.shape)
images_example = torchvision.utils.make_grid(images)
images_example = images_example.numpy().transpose(1,2,0)
mean = 0.5
std = 0.5
images_example = images_example * std + mean
plt.imshow(images_example)
plt.show()
# 给图像加噪声 实现打码操作
noisy_images = images_example + 0.5 * np.random.randn(*images_example.shape)
# 这里要加一个* ?? 不然会报元组不能加到整形的错误
noisy_images = np.clip(noisy_images,0.,1.)
# 由于原始的MNSIT的数据集图像的像素范围是(0,1),因此加噪后要转回(0,1)
plt.imshow(noisy_images)
plt.show()
# 搭建网络进行编解码 线性变换的 仅使用线性映射和激活函数作为网络结构的主要部分
class AutoEncoder(torch.nn.Module):
def __init__(self):
super(AutoEncoder, self).__init__()
self.encoder = torch.nn.Sequential(
torch.nn.Linear(28 * 28, 128),
torch.nn.ReLU(),
torch.nn.Linear(128, 64),
torch.nn.ReLU(),
torch.nn.Linear(64, 32),
torch.nn.ReLU())
self.decoder = torch.nn.Sequential(
torch.nn.Linear(32, 64),
torch.nn.ReLU(),
torch.nn.Linear(64, 128),
torch.nn.ReLU(),
torch.nn.Linear(128, 28 * 28))
def forward(self, input):
output = self.encoder(input)
output = self.decoder(output)
return output
model = AutoEncoder()
# print (modle)
# 设置优化器和损失函数
optimizer = torch.optim.Adam(model.parameters())
loss_f = torch.nn.MSELoss()
# 训练网络
epoch_n = 10
for epoch in range(epoch_n):
running_loss = 0.0
print('Epoch {}/{}'.format(epoch, epoch_n))
print('-' * 10)
for data in train_load:
X_train, _ = data
noisy_X_train = X_train + 0.5 * torch.randn(*X_train.shape)
noisy_X_train = torch.clamp(noisy_X_train, 0., 1.)
X_train, noisy_X_train = Variable(X_train.view(-1, 28 * 28)), Variable(
noisy_X_train.view(-1, 28 * 28)) # 将图像转为向量
train_pre = model(noisy_X_train)
loss = loss_f(train_pre, X_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.data.item()
print('Loss is :{:.4f}'.format(running_loss / len(dataset_train)))
# 验证结果如何
data_loader_test = torch.utils.data.DataLoader(dataset = dataset_test,
batch_size = 4,
shuffle = True)
X_test,_ = next(iter(data_loader_test))
img1 = torchvision.utils.make_grid(X_test)
img1 = img1.numpy().transpose(1,2,0)
std = 0.5
mean = 0.5
img1 = img1 * std + mean
noisy_X_test = img1 + 0.5 * np.random.rand(*img1.shape)
noisy_X_test = np.clip(noisy_X_test,0.,1.)
plt.figure()
plt.imshow(noisy_X_test)
img2 = X_test + 0.5 * torch.randn(*X_test.shape)
img2 = torch.clamp(img2,0.,1.)
img2 = Variable(img2.view(-1,28*28))
test_pred = model(img2)
img_test = test_pred.data.view(-1,1,28,28)
img2 = torchvision.utils.make_grid(img_test)
img2 = img2.numpy().transpose(1,2,0)
img2 = img2 * std + mean
img2 = np.clip(img2,0.,1.)
plt.figure()
plt.imshow(img2)
