文章目录
自动编码器 原理+作业
1. 简介
自动编码器是一种无监督的神经网络模型,它可以学习到输入数据的隐含特征,这称为编码(coding),同时用学习到的新特征可以重构出原始输入数据,称之为解码(decoding)。从直观上来看,自动编码器可以用于特征降维,类似主成分分析PCA,但是其相比PCA其性能更强,这是由于神经网络模型可以提取更有效的新特征。除了进行特征降维,自动编码器学习到的新特征可以送入有监督学习模型中,所以自动编码器可以起到特征提取器的作用。作为无监督学习模型,自动编码器还可以用于生成与训练样本不同的新数据,这样自动编码器(变分自动编码器,Variational Autoencoders)就是生成式模型。
1.1 概念
自动编码器是神经网络的一种,经过训练后能尝试将输入复制到输出,换句话说,就是使输出的内容和输入的内容一样。
自动编码器内部有一个隐含层 h h h,可以产生编码来表示输入。
该网络可以看作由两部分组成:一个编码器 h = f ( x ) h=f(x) h=f(x)和一个生成重构的解码器 r = g ( h ) r=g(h) r=g(h)。最后使得 x x x约等于 g ( f ( x ) ) g(f(x)) g(f(x))。可不可以通过设计网络使得 x = g ( f ( x ) ) x=g(f(x)) x=g(f(x)),
理论上可以的,但通常不会这么做。自动编码器应该设计成不能学会完美地复制,通过强加一些约束,使自动
编码器只能近似地复制,因些它能学习到数据的有用特性。
1.2 应用
目前自编码器的应用主要有两个方面,第一是数据去噪,第二是为进行可视化而降维。配合适当的维度和稀疏约束,自编码器可以学习到比PCA等技术更有意思的数据投影。
自动编码器是一种数据的压缩算法,
其中数据的压缩和解压缩函数是1)数据相关的,2)有损的,3)从样本中自动学习的。
在大部分提到自动编码器的场合,压缩和解压缩的函数是通过神经网络实现的。
- 1)自动编码器是数据相关的(data-specific 或 data-dependent),这意味着自动编码器只能压缩那些与训练数据类似的数据。自编码器与一般的压缩算法,如MPEG-2,MP3等压缩算法不同,一般的通用算法只假设了数据是“图像”或“声音”,而没有指定是哪种图像或声音。比如,使用人脸训练出来的自动编码器在压缩别的图片,比如树木时性能很差,因为它学习到的特征是与人脸相关的。
- 2)自动编码器是有损的,意思是解压缩的输出与原来的输入相比是退化的,MP3,JPEG等压缩算法也是如此。这与无损压缩算法不同。
- 3)自动编码器是从数据样本中自动学习的,这意味着很容易对指定类的输入训练出一种特定的编码器,而不需要完成任何新工作。
搭建一个自动编码器需要完成下面三样工作:搭建编码器,搭建解码器,设定一个损失函数,用以衡量由于压缩而损失掉的信息。编码器和解码器一般都是参数化的方程,并关于损失函数可导,典型情况是使用神经网络。编码器和解码器的参数可以通过最小化损失函数而优化,例如SGD。
自编码器是一个好的数据压缩算法吗
通常情况下,使用自编码器做数据压缩,性能并不怎么样。以图片压缩为例,想要训练一个能和JPEG性能相提并论的自编码器非常困难,并且要达到这个性能,你还必须要把图片的类型限定在很小的一个范围内(例如JPEG不怎么行的某类图片)。自编码器依赖于数据的特性使得它在面对真实数据的压缩上并不可行,你只能在指定类型的数据上获得还可以的效果,但谁知道未来会有啥新需求?
2. 常见的自编码器
学习完自编码器的一般形式——堆叠自编码器后,我们可能会有一个问题:code维度到底如何确定?为什么稀疏的特征比较好?或者更准确来讲,code怎么才能称得上是对input的一个好的表达?
事实上,这个答案并不唯一,也正是从不同的角度去思考这个问题,导致了自编码器的各种变种形式出现。目前常见的几种模型总结如下:

2.1 自动编码器原理
自动编码器的基本结构如图1所示,包括编码和解码两个过程:
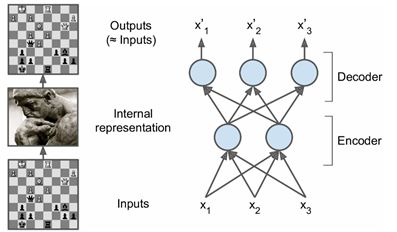
自动编码器是将输入 x x x进入编码,得到新的特征 y y y,并且希望原始的输入 x x x能够从新的特征 y y y重构出来。编码过程如下
y = f ( W x + b ) y=f(Wx+b) y=f(Wx+b)
可以看到,和神经网络结构一样,其编码就是线性组合之后加上非线性的激活函数。如果没有非线性的包装,那么自动编码器就和普通的PCA没有本质区别了。利用新的特征 y y y,可以对输入 x x x重构,即解码过程
x ′ = f ( W ′ x + b ′ ) x^\prime=f(W^\prime x+b^\prime) x′=f(W′x+b′)
我们希望重构出的 x ′ x^\prime x′和尽可能一致,可以采用最小化负对数似然的损失函数来训练这个模型
L = − l o g P ( x ∣ x ′ ) L=-logP(x|x^\prime) L=−logP(x∣x′)
对于高斯分布的数据,采用均方误差就好,而对于伯努利分布可以采用交叉熵,这个是可以根据似然函数推导出来的。一般情况下,我们会对自动编码器加上一些限制,常用的是使 W ′ = W T W^\prime=W^T W′=WT,这称为绑定权重(tied weights),本文所有的自动编码器都加上这个限制。有时候,我们还会给自动编码器加上更多的约束条件,去噪自动编码器以及稀疏自动编码器就属于这种情况,因为大部分时候单纯地重构原始输入并没有什么意义,我们希望自动编码器在近似重构原始输入的情况下能够捕捉到原始输入更有价值的信息。
2.2 稀疏自编码器
当然,我们还可以继续加上一些约束条件得到新的Deep Learning方法,如:如果在AutoEncoder的基础上加上L1的Regularity限制(L1主要是约束每一层中的节点中大部分都要为0,只有少数不为0,这就是Sparse名字的来源),我们就可以得到Sparse AutoEncoder法。
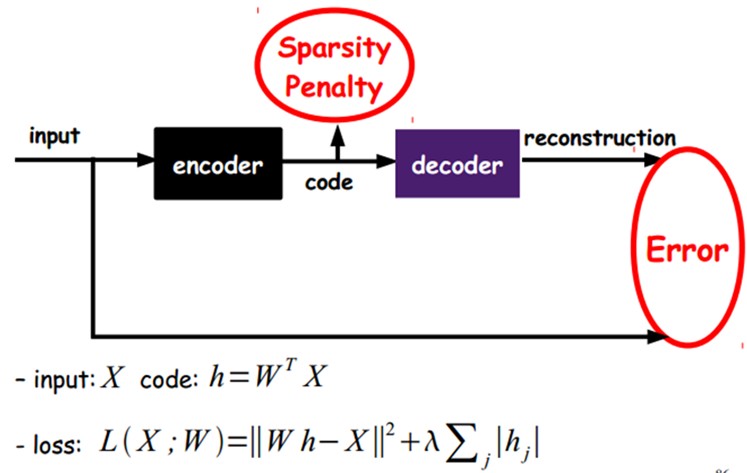
如上图,其实就是限制每次得到的表达code尽量稀疏。因为稀疏的表达往往比其他的表达要有效(人脑好像也是这样的,某个输入只是刺激某些神经元,其他的大部分的神经元是受到抑制的)。
Sparse autoencoder的一个网络结构图如下所示:
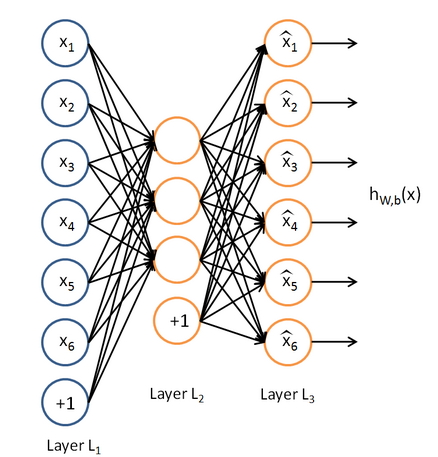
损失函数的求法:
无稀疏约束时网络的损失函数表达式如下:
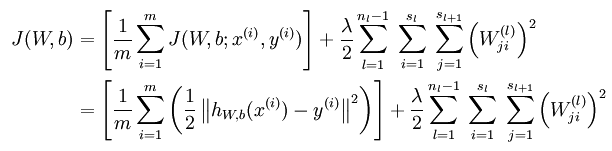
稀疏编码是对网络的隐含层的输出有了约束,即隐含层节点输出的平均值应尽量为0,这样的话,大部分的隐含层节点都处于非activite状态。因此,此时的sparse autoencoder损失函数表达式为:

后面那项为KL距离,其表达式如下:
K L ( ρ ∣ ∣ ρ ^ j ) = ρ log ρ ρ ^ j + ( 1 − ρ ) log 1 − ρ 1 − ρ j ^ KL(\rho|| \hat{\rho}_j)=\rho \log{\frac{\rho}{\hat{\rho}_j}}+(1-\rho)\log{\frac{1-\rho}{1-\hat{\rho_j}}} KL(ρ∣∣ρ^j)=ρlogρ^jρ+(1−ρ)log1−ρj^1−ρ
隐含层节点输出平均值求法如下:
ρ j ^ = 1 m ∑ i = 1 m a j ( 2 ) x ( i ) \hat{\rho_j}=\frac{1}{m}\sum_{i=1}^ma_j^{(2)}x^{(i)} ρj^=m1i=1∑maj(2)x(i)
其中的参数一般取很小,比如说0.05,也就是小概率发生事件的概率。这说明要求隐含层的每一个节点的输出均值接近0.05(其实就是接近0,因为网络中activite函数为sigmoid函数),这样就达到稀疏的目的了。KL距离在这里表示的是两个向量之间的差异值。从约束函数表达式中可以看出,差异越大则”惩罚越大”,因此最终的隐含层节点的输出会接近0.05。
2.3 堆栈自动编码器
前面我们讲了自动编码器的原理,不过所展示的自动编码器只是简答的含有一层,其实可以采用更深层的架构,这就是堆栈自动编码器或者深度自动编码器,本质上就是增加中间特征层数。这里我们以MNIST数据为例来说明自动编码器,建立两个隐含层的自动编码器,如图2所示:
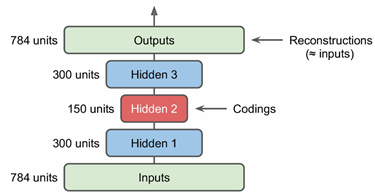
对于MNIST来说,其输入是28*28=784维度的特征,这里使用了两个隐含层其维度分别为300和150,可以看到是不断降低特征的维度了。得到的最终编码为150维度的特征,使用这个特征进行反向重构得到重建的特征,我们希望重建特征和原始特征尽量相同。由于MNIST是0,1量,可以采用交叉熵作
为损失函数,TF的代码核心代码如下:
n_inputs = 28*28
n_hidden1 = 300
n_hidden2 = 150
# 定义输入占位符:不需要y
X = tf.placeholder(tf.float32, [None, n_inputs])
# 定义训练参数
initializer = tf.contrib.layers.variance_scaling_initializer()
W1 = tf.Variable(initializer([n_inputs, n_hidden1]), name="W1")
b1 = tf.Variable(tf.zeros([n_hidden1,]), name="b1")
W2 = tf.Variable(initializer([n_hidden1, n_hidden2]), name="W2")
b2 = tf.Variable(tf.zeros([n_hidden2,]), name="b2")
W3 = tf.transpose(W2, name="W3")
b3 = tf.Variable(tf.zeros([n_hidden1,]), name="b3")
W4 = tf.transpose(W1, name="W4")
b4 = tf.Variable(tf.zeros([n_inputs,]), name="b4")
# 构建模型
h1 = tf.nn.sigmoid(tf.nn.xw_plus_b(X, W1, b1))
h2 = tf.nn.sigmoid(tf.nn.xw_plus_b(h1, W2, b2))
h3 = tf.nn.sigmoid(tf.nn.xw_plus_b(h2, W3, b3))
outputs = tf.nn.sigmoid(tf.nn.xw_plus_b(h3, W4, b4))
# 定义loss
loss = -tf.reduce_mean(tf.reduce_sum(X * tf.log(outputs) +
(1 - X) * tf.log(1 - outputs), axis=1))
train_op = tf.train.AdamOptimizer(1e-02).minimize(loss)
当训练这个模型后,你可以将原始MNIST的数字手写体与重构出的手写体做个比较,如图3所示,上面是原始图片,而下面是重构图片,基本上没有差别了。尽管我们将维度从784降低到了150,得到的新特征还是抓取了原始特征的核心信息。

有一点,上面的训练过程是一下子训练完成的,其实对于堆栈编码器来说,有时候会采用逐层训练方式。直白点就是一层一层地训练:先训练X->h1的编码,使h1->X的重构误差最小化;之后再训练h1->h2的编码,使h2->h1的重构误差最小化。其实现代码如下:
# 构建模型
h1 = tf.nn.sigmoid(tf.nn.xw_plus_b(X, W1, b1))
h1_recon = tf.nn.sigmoid(tf.nn.xw_plus_b(h1, W4, b4))
h2 = tf.nn.sigmoid(tf.nn.xw_plus_b(h1, W2, b2))
h2_recon = tf.nn.sigmoid(tf.nn.xw_plus_b(h2, W3, b3))
outputs = tf.nn.sigmoid(tf.nn.xw_plus_b(h2_recon, W4, b4))
learning_rate = 1e-02
# X->h1
with tf.name_scope("layer1"):
layer1_loss = -tf.reduce_mean(tf.reduce_sum(X * tf.log(h1_recon) +
(1-X) * tf.log(1-h1_recon), axis=1))
layer1_train_op = tf.train.AdamOptimizer(learning_rate).minimize(layer1_loss,
var_list=[W1, b1, b4])
# h1->h2
with tf.name_scope("layer2"):
layer2_loss = -tf.reduce_mean(tf.reduce_sum(h1 * tf.log(h2_recon) +
(1 - h1) * tf.log(1 - h2_recon), axis=1))
layer2_train_op = tf.train.AdamOptimizer(learning_rate).minimize(layer2_loss,
var_list=[W2, b2, b3])
分层训练之后,最终得到如图4所示的对比结果,结果还是不错的。
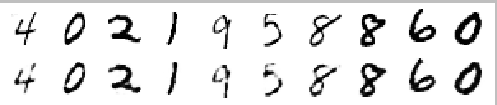
2.4 降噪自编码器(DAE)
当采用无监督的方法分层预训练深度网络的权值时,为了学习到较鲁棒的特征,可以在网络的可视层(即数据的输入层)引入随机噪声,这种方法称为Denoise Autoencoder(简称dAE),由Bengio在08年提出,见其文章Extracting and composing robust features with denoising autoencoders.
使用dAE时,可以用被破坏的输入数据重构出原始的数据(指没被破坏的数据),所以它训练出来的特征会更鲁棒。本篇博文主要是根据Benigio的那篇文章简单介绍下dAE,然后通过2个简单的实验来说明实际编程中该怎样应用dAE。这2个实验都是网络上现成的工具稍加改变而成,其中一个就是matlab的Deep Learning toolbox,见https://github.com/rasmusbergpalm/DeepLearnToolbox,另一个是与python相关的theano,参考:http://deeplearning.net/tutorial/dA.html.
2.5 收缩自动编码器(CAE)
Contractive autoencoder是autoencoder的一个变种,其实就是在autoencoder上加入了一个规则项,它简称CAE(对应中文翻译为?)。通常情况下,对权值进行惩罚后的autoencoder数学表达形式为:
小结
自动编码器应该是最通俗易懂的无监督神经网络模型,这里我们介绍了其基本原理及堆栈自动编码器。后序会介绍更多的自动编码器模型。
3. 作业
1.编写一个单层自编码器,语言不限;
2.使用数据集Mnist(手写体数字)测试自编码器;
3.利用自编码器选择出一个特征子集;
4.可以利用特征子集重建图像(感兴趣的可以自己尝试);
import torch
from torch import nn, optim
from torch.utils.data import DataLoader
import os
import matplotlib.pyplot as plt
import torchvision
import numpy as np
def get_dataloader(mode):
"""
获取数据集加载
:param mode:
:return:
"""
# 准备数据迭代器
# 这里我已经下载好了,所以是否需要下载写的是false
# 准备数据集,其中0.1307,0.3081为MNIST数据的均值和标准差,这样操作能够对其进行标准化
# 因为MNIST只有一个通道(黑白图片),所以元组中只有一个值
dataset = torchvision.datasets.MNIST('./mini',
train=mode,
download=False,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
]))
return DataLoader(dataset, batch_size=64, shuffle=True)
def show_image(x, label):
"""
展示特征图
:param x:
:return:
"""
print("开始绘图")
fig, axes = plt.subplots(8, 8, figsize=(8, 4), subplot_kw={
"xticks": [], "yticks": []})
plt.suptitle(label)
for i, ax in enumerate(axes.flat):
temp = x[i, 0].detach().numpy()
temp = temp.reshape(28, 28)
temp = temp.clip(0, 255)
ax.imshow(np.rint(temp).astype('uint8'), cmap="gray")
# np.rint()是根据四舍五入取整,因为图片的值是整形的,矩阵求出的值是浮点型
plt.axis('on') # 关掉坐标轴为 off
plt.show()
class autoencoder(nn.Module):
def __init__(self):
super(autoencoder, self).__init__()
# 定义Encoder
self.encoder = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=(3, 3), stride=(3, 3), padding=1), # (b, 16, 10, 10)
nn.ReLU(True),
nn.MaxPool2d(2, stride=2), # (b, 16, 5, 5)
nn.Conv2d(16, 8, kernel_size=(3, 3), stride=(2, 2), padding=1), # (b, 8, 3, 3)
nn.ReLU(True),
nn.MaxPool2d(2, stride=1) # (b, 8, 2, 2)
)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(8, 16, kernel_size=(3, 3), stride=(2, 2)), # (b, 16, 5, 5)
nn.ReLU(True),
nn.ConvTranspose2d(16, 8, kernel_size=(5, 5), stride=(3, 3), padding=(1, 1)), # (b, 8, 15, 15)
nn.ReLU(True),
nn.ConvTranspose2d(8, 1, kernel_size=(2, 2), stride=(2, 2), padding=(1, 1)), # (b, 1, 28, 28)
nn.Tanh()
)
# 定义网路的前向传播路径
def forward(self, x):
encoder = self.encoder(x)
decoder = self.decoder(encoder)
return decoder
# 定义模型
model = autoencoder()
# 定义优化器
optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-5)
# 定义损失函数,均值误差
loss_func = nn.MSELoss()
train_dataloader = get_dataloader(mode=True)
if not os.path.exists("./model"):
os.makedirs("model")
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
print("开始训练")
for epoch in range(10):
all_loss = []
for idx, (raw_image, labels) in enumerate(train_dataloader):
# 进行归一化处理
image = raw_image
output = model(image)
loss = loss_func(output, image) # 自编码器的训练中,样本的特征向量既是输入,也是标签
optimizer.zero_grad() # 清楚梯度信息
loss.backward() # 计算梯度
optimizer.step() # 更新参数
all_loss.append(loss.item()) # 添加损失信息
if idx % 200 == 0:
print("训练epoch{}\t{}/{}\t 损失值为{}".format(epoch, idx, len(train_dataloader), loss.item()))
# 保存模型
torch.save(model.state_dict(), r'./model/autoencoder_cnn.pkl')
if idx % 400 == 0:
show_image(raw_image, "原始图像" + str(idx))
show_image(output, "encoder图像为" + str(idx))
plt.figure()
plt.plot(range(len(all_loss)), all_loss)
plt.show()
print("训练结束,开始测试")
test_dataloader = get_dataloader(False)
# 使用的是测试集数据
for idx, (images, labels) in enumerate(test_dataloader):
output = model(images)
show_image(images, "原始图像" + str(idx))
show_image(output, "encoder图像" + str(idx))
if idx == 2:
break
原图

还原后图片信息

线性自编码器
import torch
from torch import nn, optim
from torch.autograd import Variable
from torchvision import transforms, datasets
from torch.utils.data import DataLoader
from torchvision.utils import save_image
import os
import matplotlib.pyplot as plt
import torchvision
from torchvision.utils import make_grid
import numpy as np
def get_dataloader(mode):
"""
获取数据集加载
:param mode:
:return:
"""
# 准备数据迭代器
# 这里我已经下载好了,所以是否需要下载写的是false
# 准备数据集,其中0.1307,0.3081为MNIST数据的均值和标准差,这样操作能够对其进行标准化
# 因为MNIST只有一个通道(黑白图片),所以元组中只有一个值
dataset = torchvision.datasets.MNIST('./mini',
train=mode,
download=False,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
]))
return DataLoader(dataset, batch_size=64, shuffle=True)
def show_image(x, label):
"""
展示特征图
:param x:
:return:
"""
print("开始绘图")
fig, axes = plt.subplots(8, 8, figsize=(8, 4), subplot_kw={
"xticks": [], "yticks": []})
plt.suptitle(label)
for i, ax in enumerate(axes.flat):
temp = x[i, 0].numpy()
temp = temp.reshape(28, 28)
temp = temp.clip(0, 255)
ax.imshow(np.rint(temp).astype('uint8'), cmap="gray")
# np.rint()是根据四舍五入取整,因为图片的值是整形的,矩阵求出的值是浮点型
plt.axis('on') # 关掉坐标轴为 off
plt.show()
def out_image(x, label):
fig, axes = plt.subplots(8, 8, figsize=(8, 4), subplot_kw={
"xticks": [], "yticks": []})
plt.suptitle(label)
for i, ax in enumerate(axes.flat):
temp = x[i].detach().numpy()
temp = temp.reshape(28, 28)
temp = temp.clip(0, 255)
ax.imshow(np.rint(temp).astype('uint8'), cmap="gray")
# np.rint()是根据四舍五入取整,因为图片的值是整形的,矩阵求出的值是浮点型
plt.axis('on') # 关掉坐标轴为 off
plt.show()
class autoencoder(nn.Module):
def __init__(self):
super(autoencoder, self).__init__()
# 定义Encoder
self.Encoder = nn.Sequential(
nn.Linear(784, 512),
nn.Tanh(),
nn.Linear(512, 256),
nn.Tanh(),
nn.Linear(256, 128),
nn.Tanh(),
nn.Linear(128, 3),
nn.Tanh()
)
# 定义Decoder
self.Decoder = nn.Sequential(
nn.Linear(3, 128),
nn.Tanh(),
nn.Linear(128, 256),
nn.Tanh(),
nn.Linear(256, 512),
nn.Tanh(),
nn.Linear(512, 784),
nn.Sigmoid()
)
# 定义网路的前向传播路径
def forward(self, x):
encoder = self.Encoder(x)
decoder = self.Decoder(encoder)
return decoder
# 定义模型
model = autoencoder()
# 定义优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 定义损失函数
loss_func = nn.MSELoss()
train_dataloader = get_dataloader(mode=True)
if not os.path.exists("./model"):
os.makedirs("model")
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
print("开始训练")
epoches = 40
for epoch in range(epoches):
all_loss = []
# 这里进行学习率更新
if epoch in [epoches * 0.25, epoches * 0.5]:
for param_group in optimizer.param_groups:
param_group['lr'] *= 0.1
for idx, (raw_image, labels) in enumerate(train_dataloader):
# image的shape为[64,1,28,28]->[64,784]
images = raw_image.reshape(raw_image.shape[0], -1)
output = model(images)
loss = loss_func(output, images) # 自编码器的训练中,样本的特征向量既是输入,也是标签
optimizer.zero_grad() # 清楚梯度信息
loss.backward() # 计算梯度
optimizer.step() # 更新参数
all_loss.append(loss.item()) # 添加损失信息
if idx % 20 == 0:
print("训练epoch{}\t{}/{}\t 损失值为{}".format(epoch, idx, len(train_dataloader), loss.item()))
# 保存模型
torch.save(model.state_dict(), r'./model/autoencoder.pkl')
if idx % 400 == 0:
show_image(raw_image, "原始图像" + str(idx))
out_image(output, "encoder图像为" + str(idx))
plt.figure()
plt.plot(range(len(all_loss)), all_loss)
plt.show()
print("训练结束,开始测试")
test_dataloader = get_dataloader(False)
# 使用的是测试集数据
for idx, (images, labels) in enumerate(test_dataloader):
output = model(images)
show_image(images, "原始图像" + str(idx))
out_image(output, "encoder图像为" + str(idx))
if idx == 2:
break

还原后
