在了解降噪自动编码器之前,我们先了解一下自动编码器。
自动编码器(Autoencoder):
自动编码器和PCA等方法都属于降维方法。PCA降维方法有着一定局限性,主要是只对线性可分的数据降维效果较好。这种情况下,人们希望提出一种新的简单的、自动的、可以对非线性可分数据进行的特征提取方法。于是人们提出了自动编码器技术来提取特征。
自动编码器(Auto-encoder)属于非监督学习(或者叫自监督学习),它不需要对训练样本进行标记,或者说标记就是训练样本本身。
自动编码器(Auto-encoder)由三层网络组成,其中输入层神经元数量与输出层神经元数量相等,中间层神经元数量少于输入层和输出层。在网络训练期间,对每个训练样本,经过网络会在输出层产生一个新的信号,网络学习的目的就是使输出信号与输入信号尽量相似。
从结构上划分时,自动编码器(Auto-encoder)可以划分成两部分,输入层和中间层可以看成是对信号进行压缩的结构部分;中间层和输出层可以看成是对压缩的信号进行还原的部分。
如下图,其中x是原始的输入数据,y是隐藏层输出数据,z是输出层输出的数据。
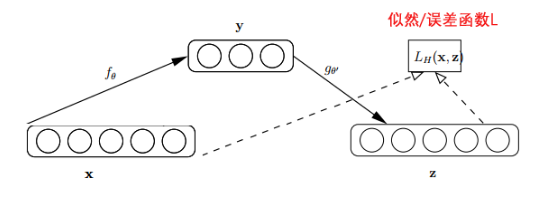
最开始的自动编码器的编码部分和解码部分是分开的,编码器和解码器各有一组w和b,但是后来vincent在2010年的论文:
Extracting and composing robust features with denoising autoencoders中证明,只需要一组w就可以了,即解码器的![]()
编码器部分:
假设我们输入一个n维的信号x(x∈[0,1]),经过输入层到达中间层,信号变为y,可以用如下公式表示:

其中s是sigmoid激活函数。W是输入层到中间层的权值,b为中间层的bias。
解码器部分:
编码器的输出y数据输入到n个神经元的输出层,信号变为z,可以用如下公式表示:
![]()
其中s是sigmoid激活函数。W′是中间层到输出层的权值,b′为输出层的bias。z被当作是x的预测。
通常情况下,权重矩阵W′被限制为权重矩阵W的转置:![]()
我们训练这个模型的过程就是利用反向传播算法更新w、b和b',使得最终输出的z与原始输入的信号x尽量接近。
误差(损失函数)计算方法:
可以使用典型的平方误差(squared error):
![]()
如果输入的数据为位向量或者是位概率向量,可以使用交叉熵方法:

自编码器是一个很好的有损压缩方法。
我们希望中间层输出数据y能够很好地提取出输入数据x的主要特征。这一点与PCA的目的一致,即获取数据的主成分。
当我们将输入层与中间层之间的函数s变为线性函数(即没有激活函数),将最终输出层信号z与原始输入信号x的误差设为平方误差时,这个问题就变成了一个PCA主成份分析问题。假设中间层有k个节点,就变成由输入信号xx的前k个主成份项,来近似表示原始输入信号。
因为y可以视为x的有损压缩形式,通过我们的优化算法,可以对训练样本产生很好的压缩效果,同时在测试样本集上有很好的表现,但是我们并不能保证网络可以所有样本都有好的压缩效果。
降噪自动编码器(Denoising Autoencoder):
在神经网络模型训练阶段开始前,通过Autoencoder对模型进行预训练可确定编码器WW的初始参数值。然而,受模型复杂度、训练集数据量以及数据噪音等问题的影响,通过Autoencoder得到的初始模型往往存在过拟合的风险。
Denoising Autoencoder(降噪自动编码器)就是在Autoencoder的基础之上,为了防止过拟合问题而对输入的数据(网络的输入层)加入噪音,使学习得到的编码器W具有较强的鲁棒性,从而增强模型的泛化能力。
怎么才能使特征具有较强的鲁棒性呢?就是以一定概率分布(通常使用二项分布)去擦除原始input矩阵,即每个值都随机置0, 这样看起来部分数据的部分特征丢失了。
降噪自动编码器具体内容可参考其论文:Extracting and Composing Robust Features
论文中对于降噪编码器的结构定义如下:
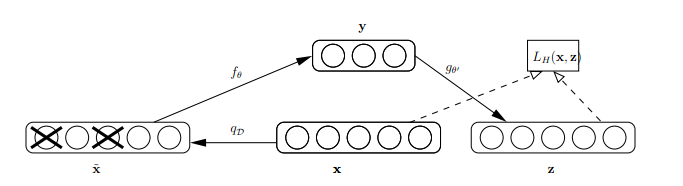
其中x是原始的输入数据,Denoising Auto-encoder把输入层节点的某些值置为0,从而得到含有噪音的输入数据![]() 。这和dropout类似,不同的是dropout是隐含层中的神经元置为0。
。这和dropout类似,不同的是dropout是隐含层中的神经元置为0。
然后用含有噪音的输入数据![]() 数据x'去计算y,计算z,并将z与原始x做误差迭代,这样,神经网络就学习了这个破损(原文叫Corruputed)的数据。
数据x'去计算y,计算z,并将z与原始x做误差迭代,这样,神经网络就学习了这个破损(原文叫Corruputed)的数据。
为什么要学习破损的数据?
1、通过与非破损数据训练的对比,破损数据训练出来的Weight噪声比较小。因为擦除的时候不小心把输入噪声给擦除掉了。
如下图:
左图是原始数据,右图是经过神经网络得到的z数据。

2、破损的数据去掉了一些噪声,这使得训练得到的数据不易过拟合,这样模型在面对测试数据时泛化能力增强了,表现出来就是测试数据的loss比较接近训练数据的loss。也就是说,我们的模型的鲁棒性增强了。
降噪自动编码器代码实现举例:
我们还是以mnist数据集为例。
注意:
如果编码器网络的权重初始化的太小,那信号将会在层间传递时逐渐缩小而难以产生作用;如果权重初始化的太大,那信号将在每层间传递时逐渐放大最终导致发散。因此我们会用到一种参数初始化方法:Xavier Initialization。
Xavier Initialization:
该初始化方法会根据某一层网络的输入输出的节点数量自动调整最合适的随机分布。让初始化权重不大不小,正好合适。从数学角度讲,就是让权重满足0均值,方差为![]() 。随机分布的形式可以是均匀分布或者高斯分布。
。随机分布的形式可以是均匀分布或者高斯分布。
如:
# Xavier均匀初始化,num_in是输入节点的数量,num_out是输出节点的数量。
def xavier_init(num_in, num_out, constant=1):
low = -constant * np.sqrt(6.0 / (num_in + num_out))
high = constant * np.sqrt(6.0 / (num_in + num_out))
# tf.random_uniform()返回num_in*num_out的矩阵,矩阵值产生于low和high之间,产生的值是均匀分布的。
return tf.random_uniform((num_in, num_out), minval=low, maxval=high, dtype=tf.float32)上面代码通过tf.random_uniform创建了一个均匀分布,区间为:
![]()
该均匀分布的方差:
![]()
上面就是一个标准均匀分布的Xavier初始化实现。
我们建立一个输入层,一个隐藏层,一个输出层。
输入层每张图片784个维度,隐藏层输出每张图片200个维度,输出层每张图片784个维度。
隐藏层有权重w和b,输出层有权重wT和b',其中wT是w的转置矩阵。
损失函数选择平方和的均值,优化器选择Adam算法。
模型训练到loss小于0.003或迭代超过10000次后停止,然后测试一组数据,看看图片的还原度。
自编码器的代码实现和下面几乎完全一样,唯一的区别是自编码器直接输入x原始数据,不需要给x数据加噪声。
完整代码如下:
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
import os
from tensorflow.examples.tutorials.mnist import input_data
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
# 还是用mnist数据集来做例子
mnist = input_data.read_data_sets("MNIST_data", one_hot=False)
# mnist输入数据的维度
input_dim = 784
# 隐藏层神经元数量
num_hidden = 200
batch_size = 128
test_size = 128
# 定义X占位符,用来接收输入数据
X = tf.placeholder(tf.float32, [None, input_dim])
# scale为噪声水平
scale_value = 0.01
x_input = X + scale_value * tf.random_normal((input_dim,))
# Xavier均匀初始化,num_in是这层输入节点的数量,num_out是这层输出节点的数量。
w_init_max = 1.0 * np.sqrt(6.0 / (input_dim + num_hidden))
# W_init的shape=[784,1024]
w_init = tf.random_uniform(shape=[input_dim, num_hidden], minval=-w_init_max, maxval=w_init_max)
# 编码器w和b权重
w_e = tf.Variable(w_init, name='w_encoder')
b_e = tf.Variable(tf.zeros([num_hidden]), name='b_encoder')
# 解码器w和b权重,解码器的w是编码器w的转置
w_d = tf.transpose(w_e, name='w_decoder')
b_d = tf.Variable(tf.zeros([input_dim]), name='b_decoder')
# 定义自动编码器模型
# 输入x的shape=[batch_size,784],w_encoder的shape=[784,1024],w_decoder的shape=[1024,784]
def model(x, w_encoder, b_encoder, w_decoder, b_decoder):
y = tf.nn.sigmoid(tf.add(tf.matmul(x, w_encoder), b_encoder))
z = tf.nn.sigmoid(tf.add(tf.matmul(y, w_decoder), b_decoder))
return z
# 得到预测值
X_pred = model(x_input, w_e, b_e, w_d, b_d)
# 定义损失函数为平方和均值,并且加入L2正则化项,这样要快很多
# 注意计算的是原始数据x与pred之间的误差,而不是加了噪声以后的数据x_input
cost = tf.reduce_mean(tf.square(X - X_pred))
train_op = tf.train.AdamOptimizer(0.01).minimize(cost)
saver = tf.train.Saver()
# 创建保存模型的路径
if not os.path.exists("./save_model/"):
os.mkdir("./save_model")
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
if os.path.exists("./save_model/checkpoint"):
# 判断模型是否存在,如果存在则从模型中恢复变量
saver.restore(sess, tf.train.latest_checkpoint('./save_model/'))
step = 0
while True:
batch_train_x_data, batch_train_y_data = mnist.train.next_batch(batch_size)
loss, _ = sess.run([cost, train_op], feed_dict={X: batch_train_x_data})
if step % 50 == 0:
print("iteration:{:>06d} loss:{}".format(step, loss))
saver.save(sess, "./save_model/train_model", global_step=step)
if loss < 0.003:
break
if step > 10000:
break
step += 1
print("Training finished!")
# 训练好模型后,我们用模型来编码压缩后再解码,看看和原图相比的效果
test_x_data, test_y_data = mnist.test.next_batch(test_size)
test_x_decode = sess.run(X_pred, feed_dict={X: test_x_data})
# 将解码后的图片与原始图片做比较,这里只比较10张
# 把图像的幕布分成2行10列,figsize=(10, 2), dpi=100即创建一张1000X200像素的图
f, a = plt.subplots(2, 10, figsize=(10, 2), dpi=100)
for i in range(10):
a[0][i].imshow(np.reshape(test_x_data[i], (28, 28)), cmap=plt.get_cmap('gray'))
a[1][i].imshow(np.reshape(test_x_decode[i], (28, 28)), cmap=plt.get_cmap('gray'))
plt.show()
plt.close()运行结果如下:
当迭代7700次时,loss值已低于0.003。
此时我们用一组测试图像的原始图像和解码出来的图像作对比:

可以看到解码出来的图像的还原度已经很高了,而我们在隐藏层一张图片的输出维度只有200,也就是说,我们用200个特征基本上就可以全部代表一张图片输入的784个特征。
这是为什么呢?
我们可以参考我们日常生活中压缩图片的过程。一张高清1920X1080的图片压缩成800X600时,我们仍然能够分辨中图片中的人物或者建筑之类的对象,因为高分辨率的图片在描绘物体的轮廓时能够描绘的更加精确,但在低分辨率的图片中我们也仍然能分辨出物体的轮廓,这就是自动编码器降维时的依据。
模型在识别时主要识别的是图片中所有像素点之间的数值关系(这个关系很难精确地用数学函数来描述,但确实有关联,比如上图表示字体的部分的像素总是更白一些,而表示背景的部分的像素点更黑一些),只要我们降维后得到的特征仍然可以较为准确地描述这种关系,那么我们就可以说我们用200个特征值较为准确地提取了这张图片的特征,我们在还原时就能还原出较为接近原始图片的图片。
降噪自动编码器的实际应用:
我们可以训练好降噪自动编码器后,输入原始数据x得到该模型中隐藏层的输出y数据,然后将y数据代替原本的原始数据x输入其后的深度学习网络。这样降噪自动编码器就相当于一个降维、提起特征的结构。