综述
“子非鱼,焉知鱼之乐”
本文采用编译器:jupyter
逻辑回归方法是从线性回归方法发展过来的,通常解决的是分类问题,读者或许有这样一个疑问:既然是回归算法又么解决分类问题的呢?
道理其实很简单,在我们求出线性回归系数a,b之后,对于每一个输入的x值,模型都可以输出对应的y值,如果把输出值y限制在0到1的范围内,那么这个y就非常的像一个概率p,我们只用规定概率的不同取值范围对应不同的标记值,就可以把一个回归问题转化成分类问题。
这个转化过程就是介绍的重点,如图。
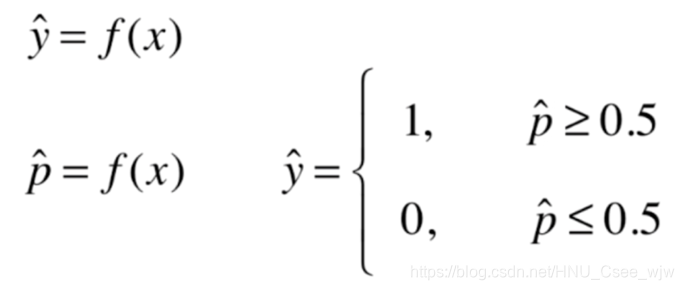
在回归问题中,输出的y取值范围为 负无穷到正无穷
![]()
回归问题要求输出结果值域为[0, 1],故做如下变换:

定义Sigmoid函数:
扫描二维码关注公众号,回复:
5721933 查看本文章

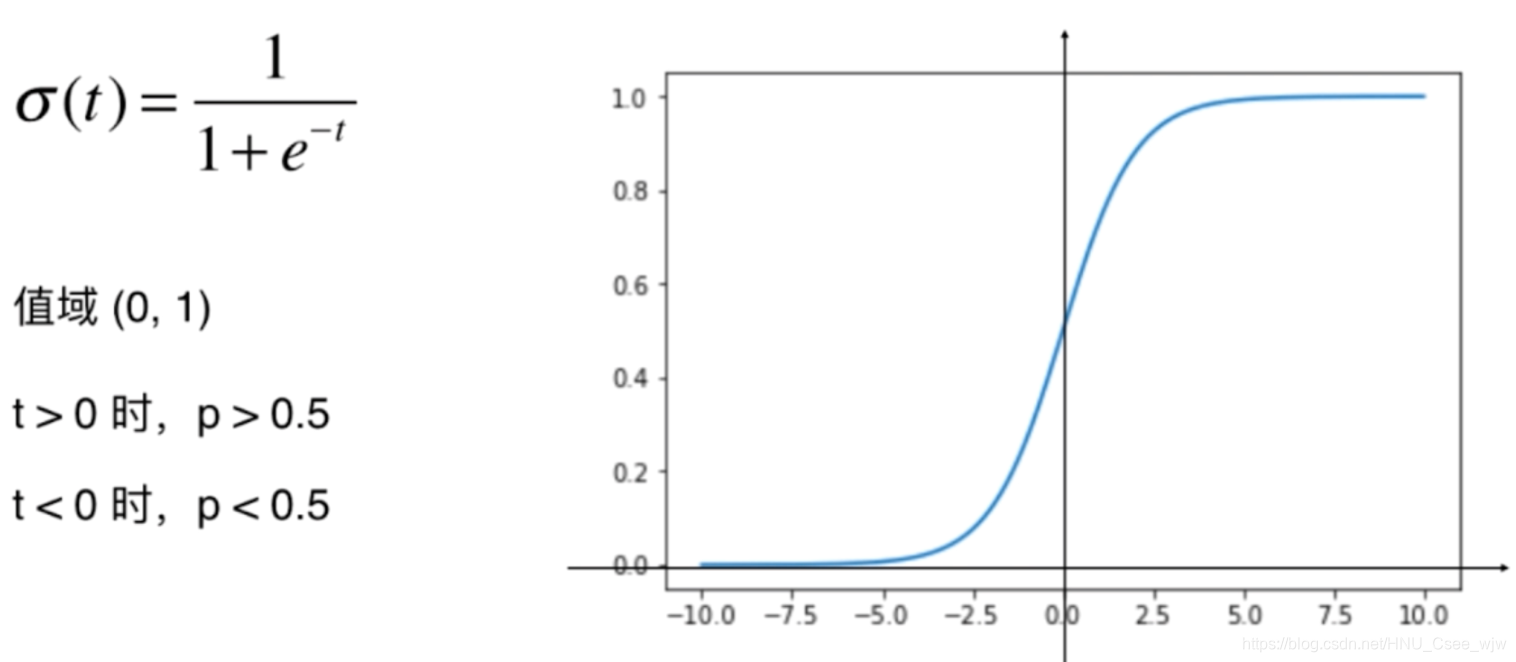
01 Sigmoid函数
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(t):
return 1 / (1 + np.exp(-t))
x = np.linspace(-10, 10, 500)
y = sigmoid(x)
plt.plot(x, y)
plt.show()
由上面的分析可得:

于是逻辑回归问题就可以转化成:对于给定的样本数据集X,y,找到参数使得可以最大程度获得样本数据集X对应的分类输出y
首先还是思考如何表示损失的函数:




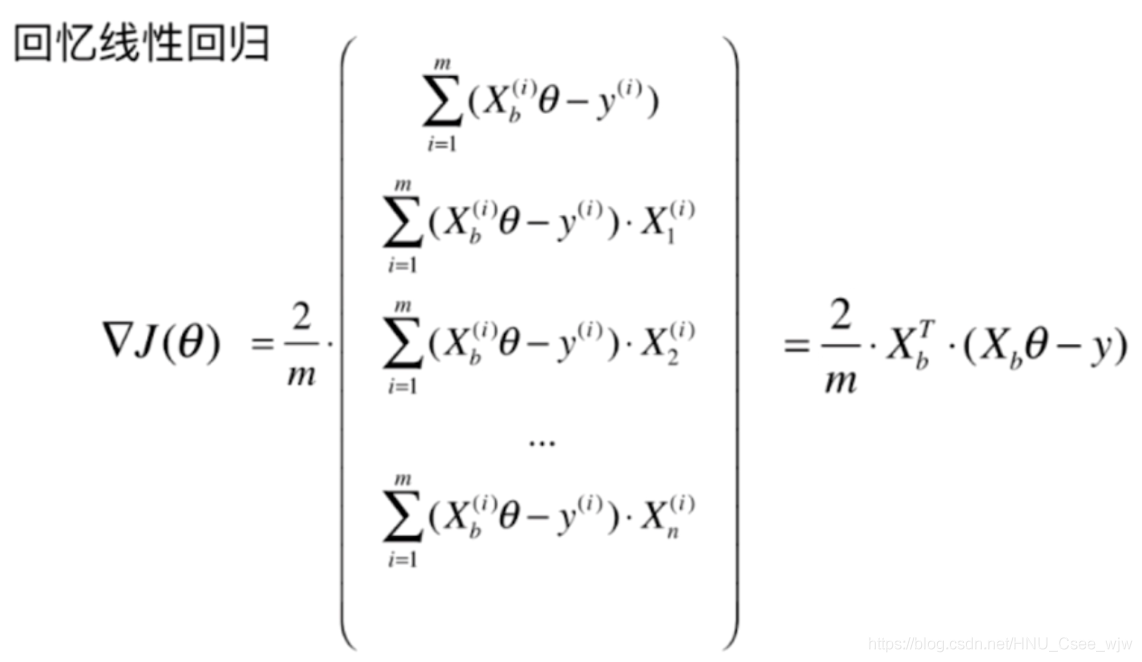
没有公式解,只能用梯度下降法求解,过程如下(可跳过直接查看结果):
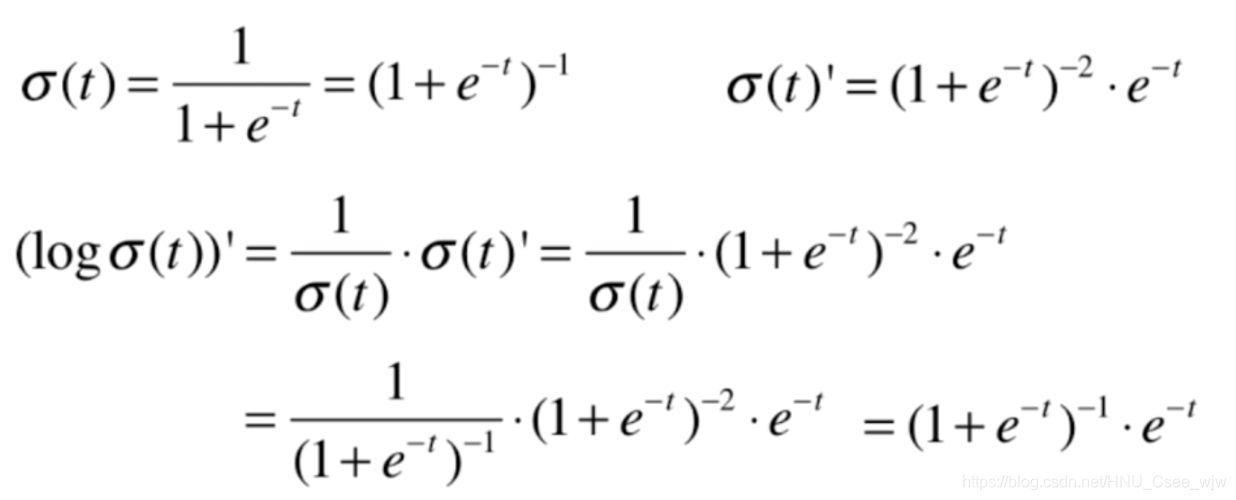
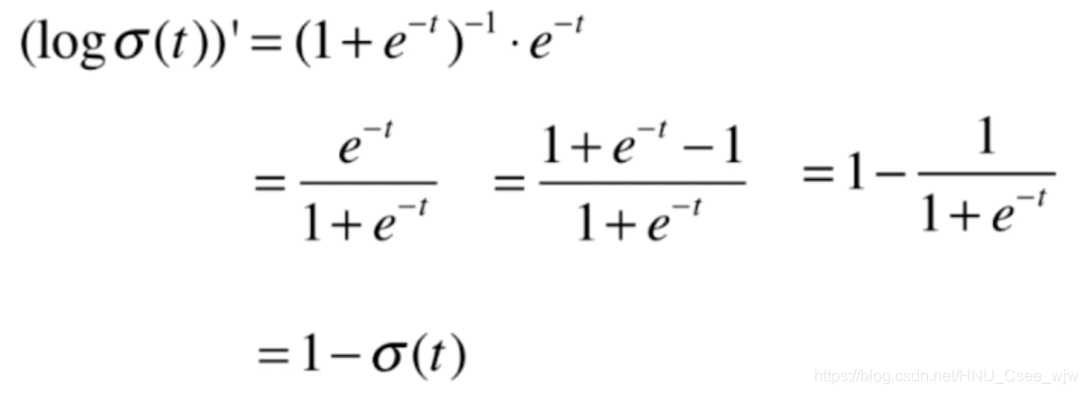
前半部分:
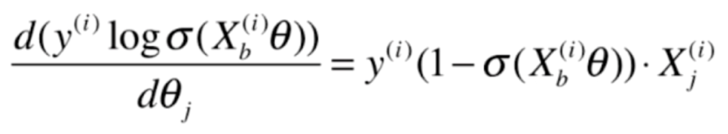

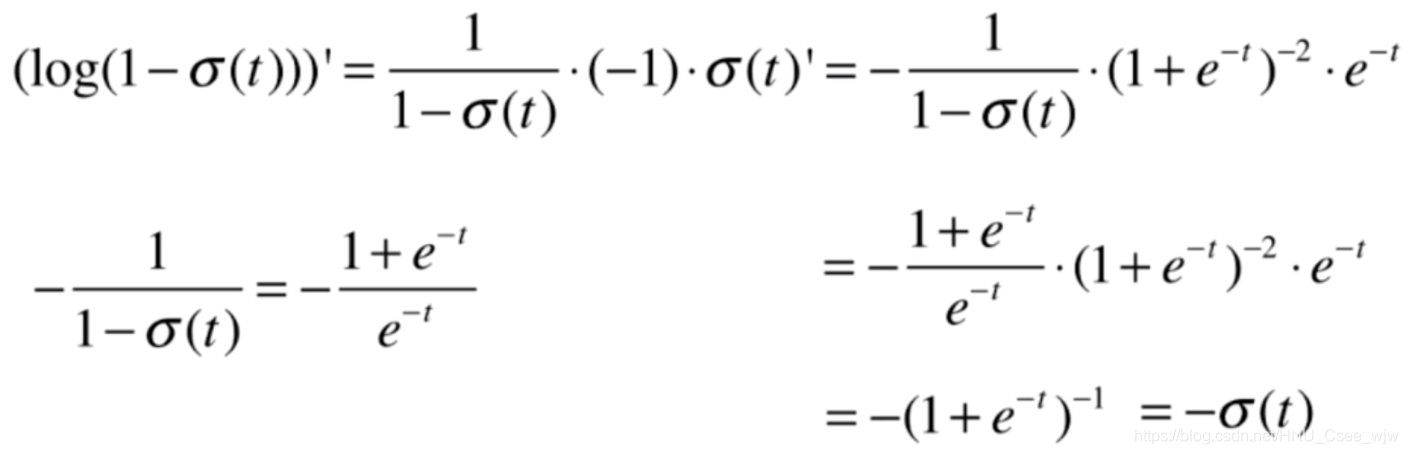
后半部分:
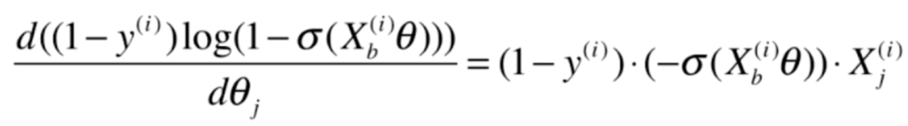
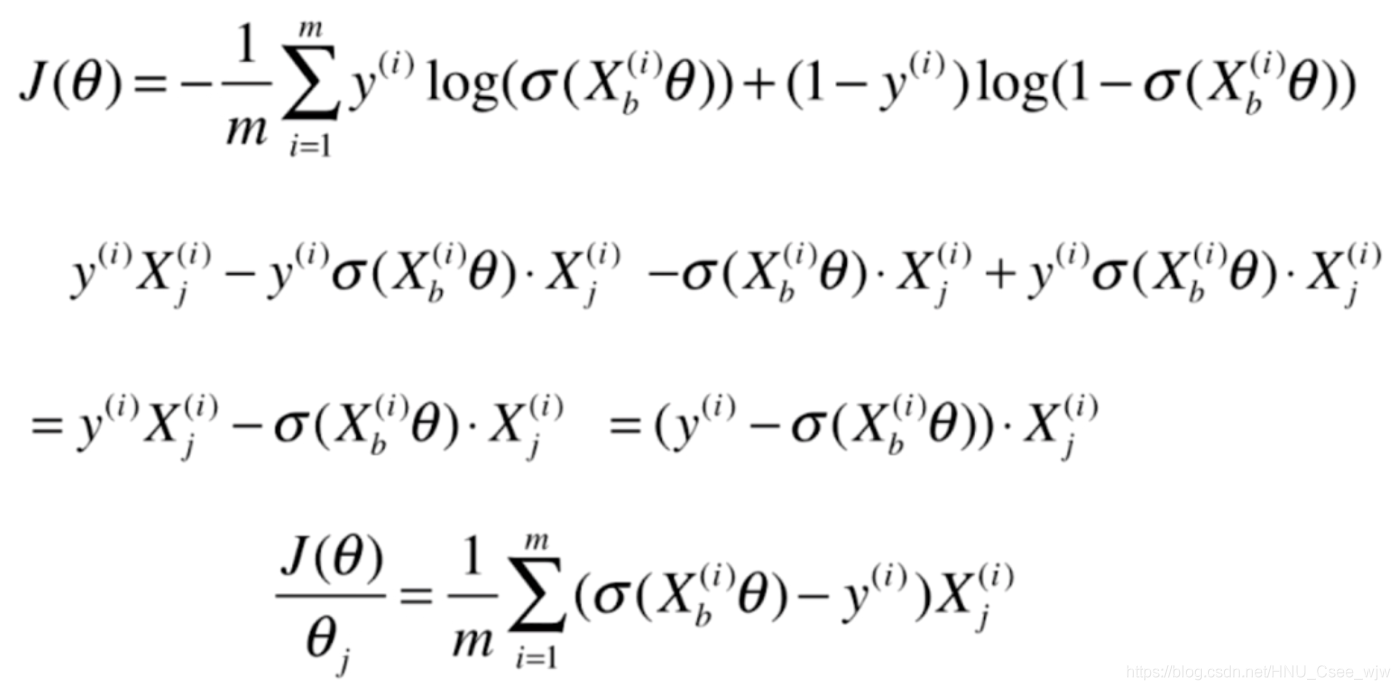
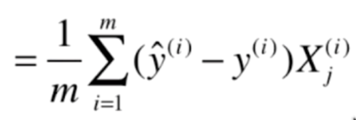
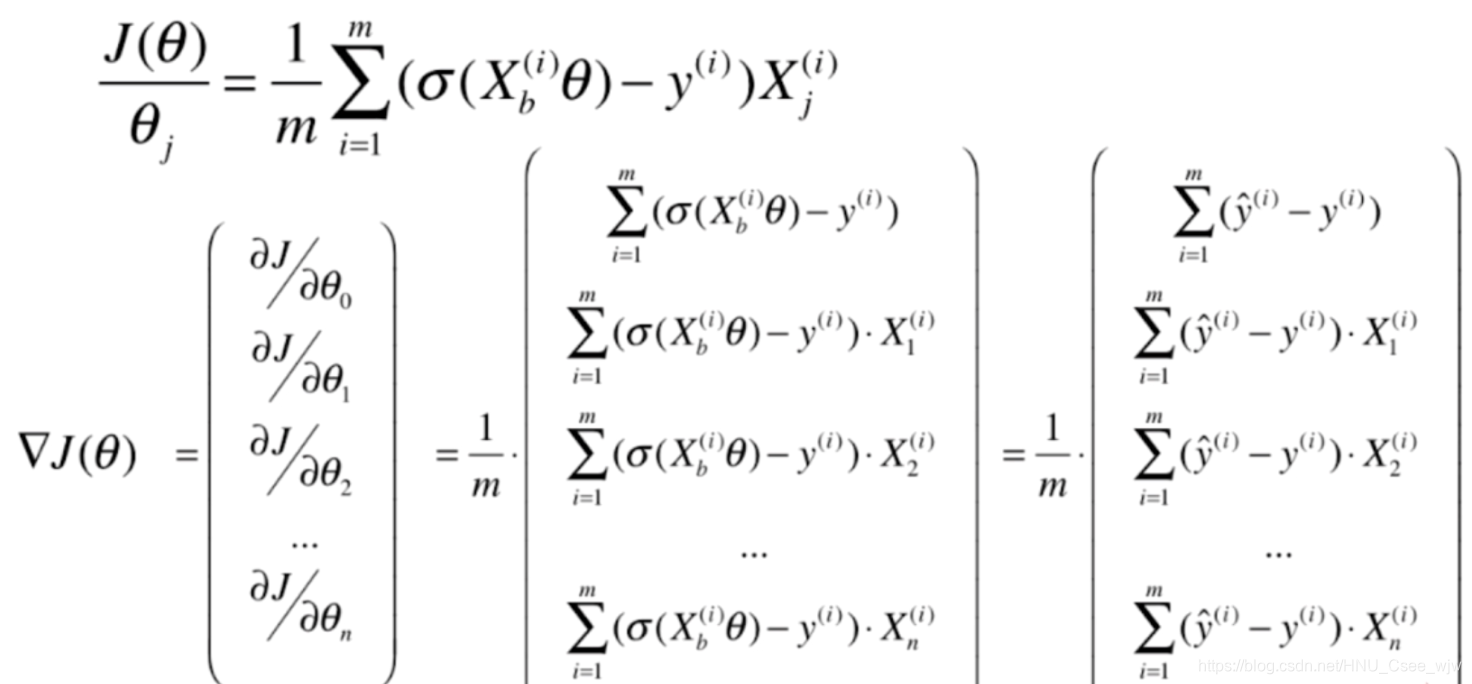

02 实现逻辑回归
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 逻辑回归解决的是二分类问题,所以只取两个类别
X = X[y<2, :2]
y = y[y<2]
X.shape
# Out[8]:
# (100, 2)
y.shape
# Out[9]:
# (100,)
plt.scatter(X[y==0,0],X[y==0,1],color='red')
plt.scatter(X[y==1,0],X[y==1,1],color='blue')
plt.show()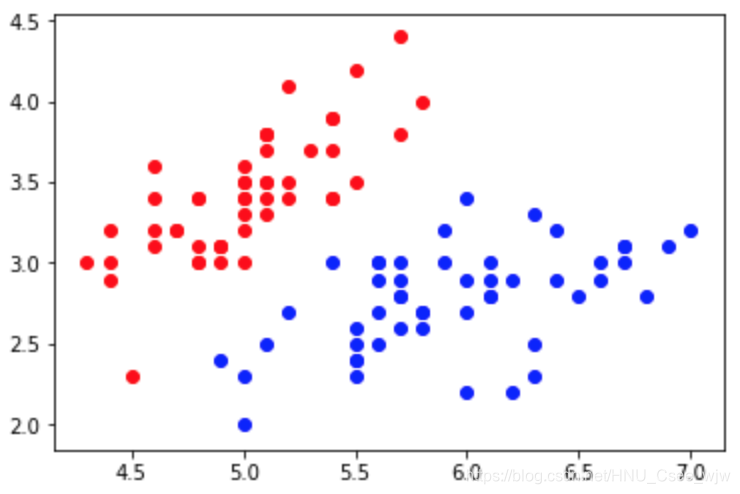
使用逻辑回归
from playML.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, seed=666)
from playML.LogisticRegression import LogisticRegression
log_reg = LogisticRegression()
log_reg.fit(X_train, y_train)
# Out[12]:
# LinearRegression()
log_reg.score(X_test, y_test)
# Out[14]:
# 1.0
log_reg.predict_proba(X_test)
"""
Out[15]:
array([ 0.92972035, 0.98664939, 0.14852024, 0.17601199, 0.0369836 ,
0.0186637 , 0.04936918, 0.99669244, 0.97993941, 0.74524655,
0.04473194, 0.00339285, 0.26131273, 0.0369836 , 0.84192923,
0.79892262, 0.82890209, 0.32358166, 0.06535323, 0.20735334])
"""
y_test # 概率大于0.5则判决为1,否则为0
# Out[16]:
# array([1, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0])
log_reg.predict(X_test)
# Out[17]:
# array([1, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0])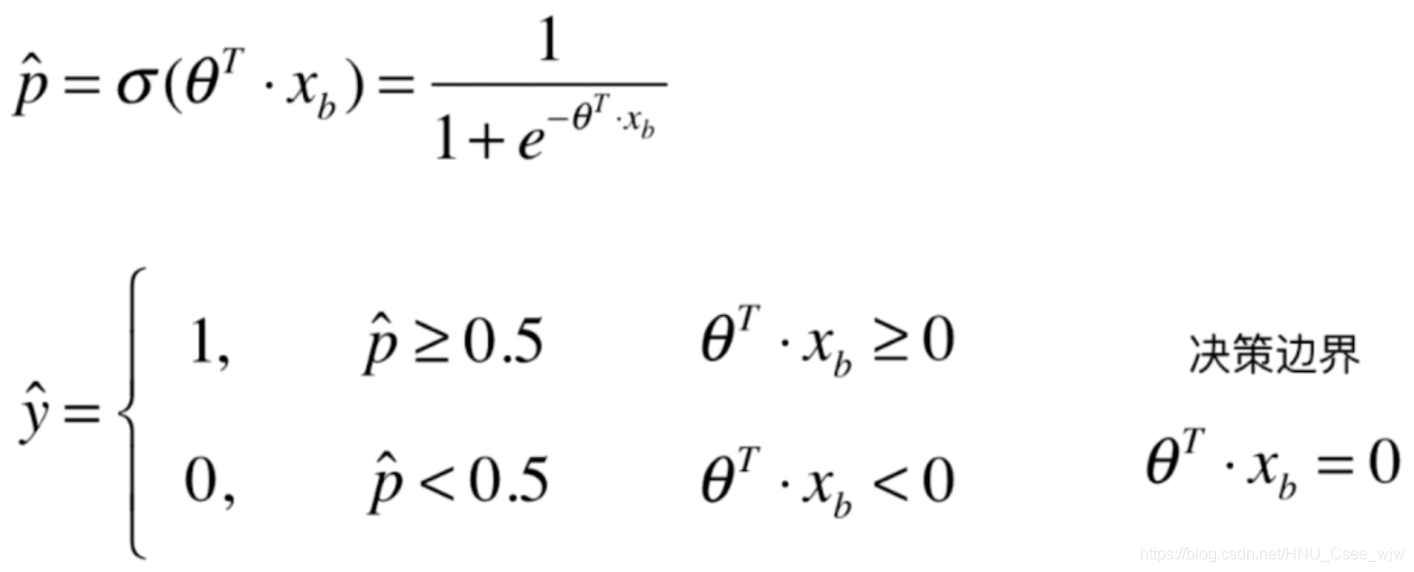

03 决策边界
# 根据模型计算由x1得到的x2
def x2(x1):
return (-log_reg.coef_[0] * x1 - log_reg.intercept_) / log_reg.coef_[1]
# 计算决策边界
x1_plot = np.linspace(4, 8, 100)
x2_plot = x2(x1_plot)
# 可以观察到有一个点分类错误,但当我们用测试数据集对模型测试时得分是1,所以该点在训练数据集中
plt.scatter(X[y==0,0],X[y==0,1],color='red')
plt.scatter(X[y==1,0],X[y==1,1],color='blue')
plt.plot(x1_plot, x2_plot)
plt.show()
plt.scatter(X_test[y_test==0,0],X_test[y_test==0,1],color='red')
plt.scatter(X_test[y_test==1,0],X_test[y_test==1,1],color='blue')
plt.plot(x1_plot, x2_plot)
plt.show()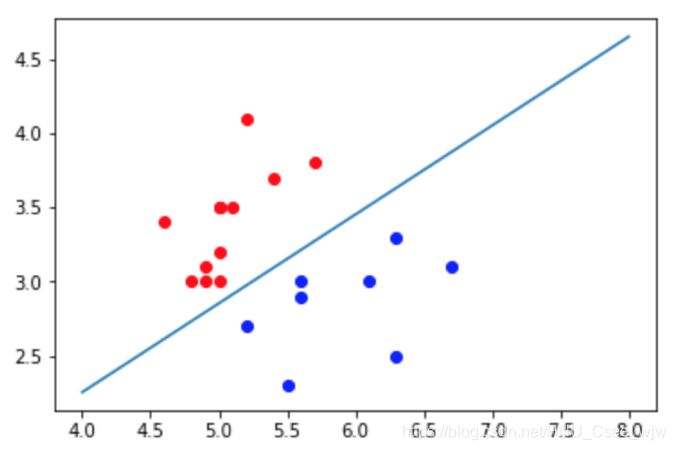
def plot_decision_boundary(model, axis):
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1,1),
np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1,1)
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A', '#FFF59D','#90CAF9'])
plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap)
plot_decision_boundary(log_reg, axis=[4, 7.5, 1.5, 4.5])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()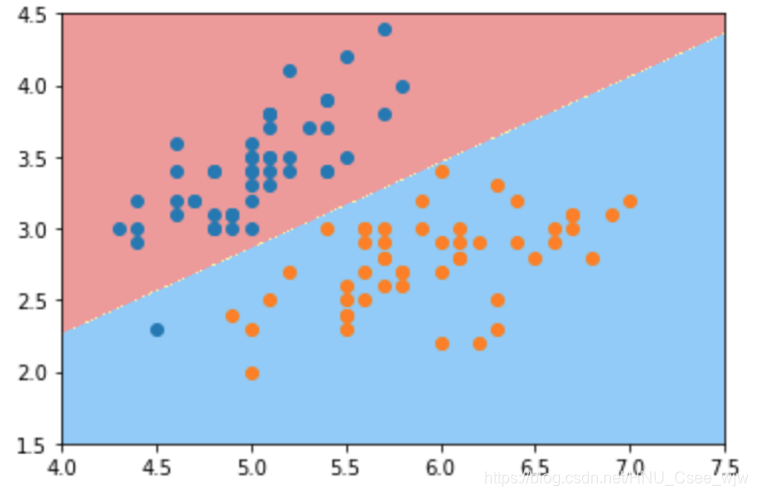
kNN的决策边界
from sklearn.neighbors import KNeighborsClassifier
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train, y_train)
"""
Out[21]:
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=5, p=2,
weights='uniform')
"""
knn_clf.score(X_test, y_test)
# Out[22]:
# 1.0
plot_decision_boundary(knn_clf, axis=[4, 7.5, 1.5, 4.5])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()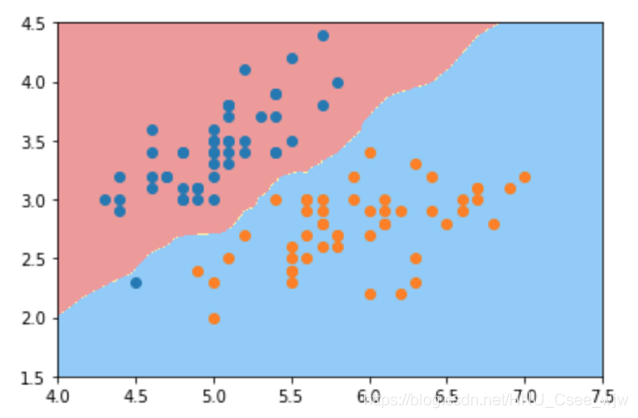
# 对有三个类别的数据进行分类,为了方便可视化取前两个特征
knn_clf_all = KNeighborsClassifier()
knn_clf_all.fit(iris.data[:,:2], iris.target)
"""
Out[24]:
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=5, p=2,
weights='uniform')
"""
plot_decision_boundary(knn_clf_all, axis=[4, 8, 1.5, 4.5])
plt.scatter(iris.data[iris.target==0,0],iris.data[iris.target==0,1])
plt.scatter(iris.data[iris.target==1,0],iris.data[iris.target==1,1])
plt.scatter(iris.data[iris.target==2,0],iris.data[iris.target==2,1])
plt.show()
# n_neighbors越小,边界越不规整
knn_clf_all = KNeighborsClassifier(n_neighbors=50)
knn_clf_all.fit(iris.data[:,:2], iris.target)
"""
Out[26]:
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=50, p=2,
weights='uniform')
"""
plot_decision_boundary(knn_clf_all, axis=[4, 8, 1.5, 4.5])
plt.scatter(iris.data[iris.target==0,0],iris.data[iris.target==0,1])
plt.scatter(iris.data[iris.target==1,0],iris.data[iris.target==1,1])
plt.scatter(iris.data[iris.target==2,0],iris.data[iris.target==2,1])
plt.show()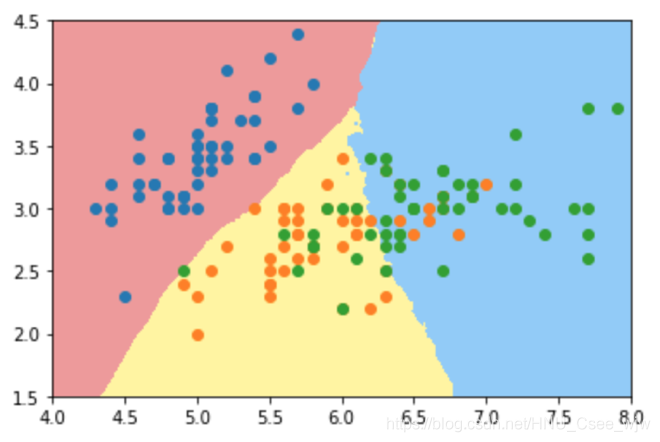
04 逻辑回归中添加多项式特征
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(666)
# 生成有两个特征的X
X = np.random.normal(0, 1, size=(200, 2))
# 特征y类似一个圆,半径小于1.5时置为1
y = np.array(X[:,0]**2 + X[:,1]**2 < 1.5, dtype='int')
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()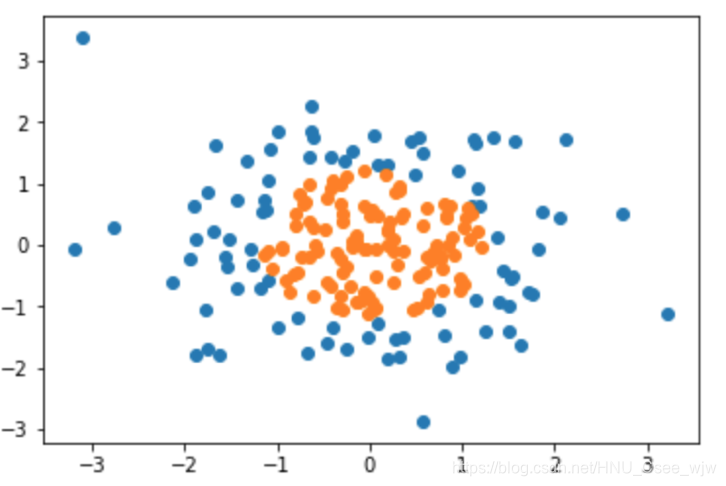
使用逻辑回归
from playML.LogisticRegression import LogisticRegression
log_reg = LogisticRegression()
log_reg.fit(X, y)
# Out[5]:
# LinearRegression()
log_reg.score(X, y)
# 分类准确度较低
# Out[6]:
# 0.60499999999999998
def plot_decision_boundary(model, axis):
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1,1),
np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1,1)
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A', '#FFF59D','#90CAF9'])
plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap)
# 图示较低的分类准确度
plot_decision_boundary(log_reg, axis=[-4, 4, -4, 4])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()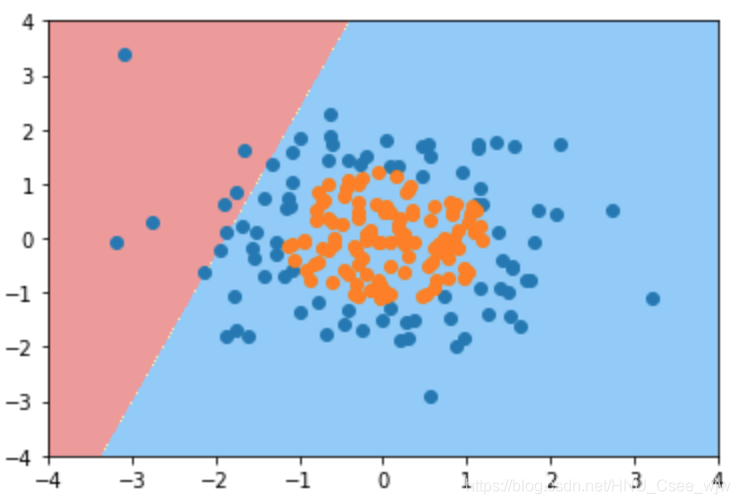
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.preprocessing import StandardScaler
# 1.添加多项式项 2.归一化 3.逻辑回归(自己实现的类,符合“构造函数,fit,predict,score”等标准)
def PolynomialLogisticRegression(degree):
return Pipeline([
('poly', PolynomialFeatures(degree=degree)),
('std_scaler', StandardScaler()),
('log_reg', LogisticRegression())
])
poly_log_reg = PolynomialLogisticRegression(degree=2)
poly_log_reg.fit(X, y)
"""
Out[10]:
Pipeline(memory=None,
steps=[('poly', PolynomialFeatures(degree=2, include_bias=True, interaction_only=False)), ('std_scaler', StandardScaler(copy=True, with_mean=True, with_std=True)), ('log_reg', LinearRegression())])
"""
poly_log_reg.score(X, y)
# Out[11]:
# 0.94999999999999996
plot_decision_boundary(poly_log_reg, axis=[-4, 4, -4, 4])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()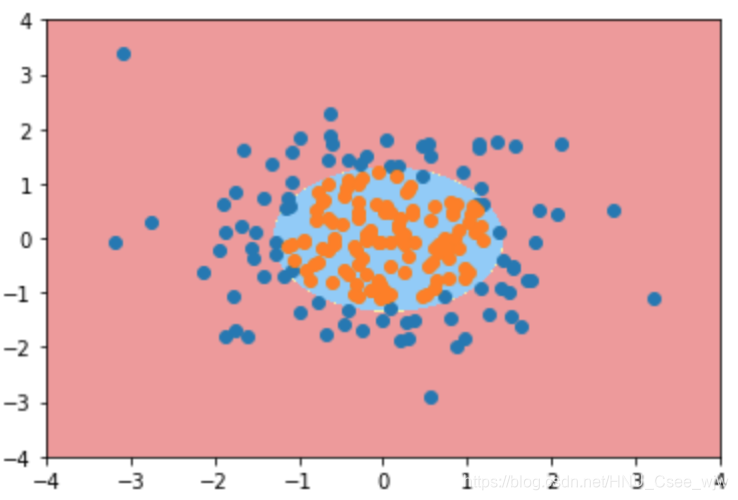
# 过拟合
poly_log_reg2 = PolynomialLogisticRegression(degree=20)
poly_log_reg2.fit(X, y)
"""
Out[14]:
Pipeline(memory=None,
steps=[('poly', PolynomialFeatures(degree=20, include_bias=True, interaction_only=False)), ('std_scaler', StandardScaler(copy=True, with_mean=True, with_std=True)), ('log_reg', LinearRegression())])
"""
plot_decision_boundary(poly_log_reg2, axis=[-4, 4, -4, 4])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()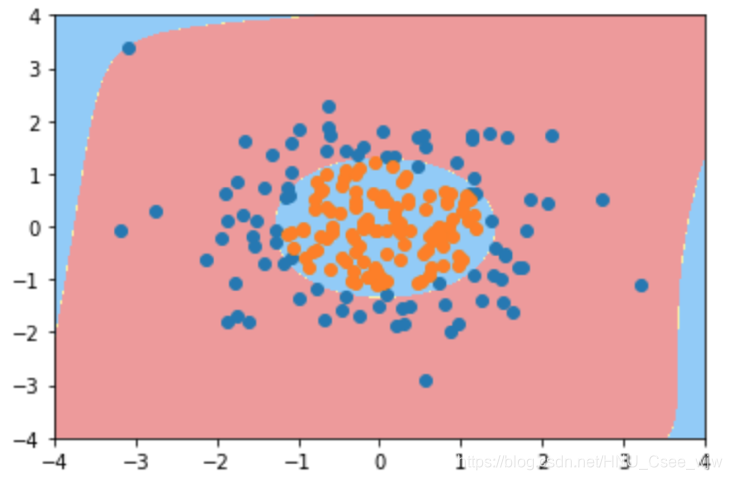
在逻辑回归中使用正则化的方法如下:
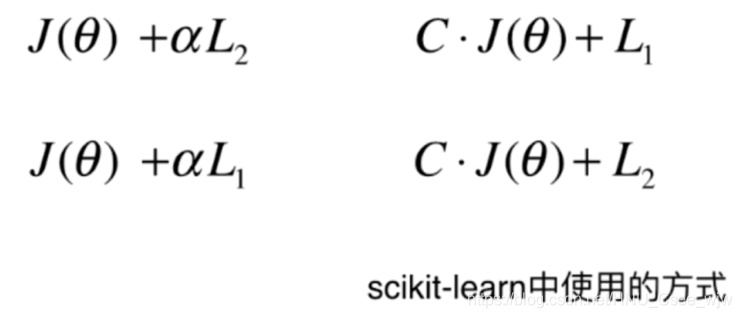
05 scikit-learn中的逻辑回归、使用正则化
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(666)
X = np.random.normal(0, 1, size=(200, 2))
y = np.array(X[:,0]**2 + X[:,1] < 1.5, dtype='int')
for _ in range(20):
y[np.random.randint(200)] = 1
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()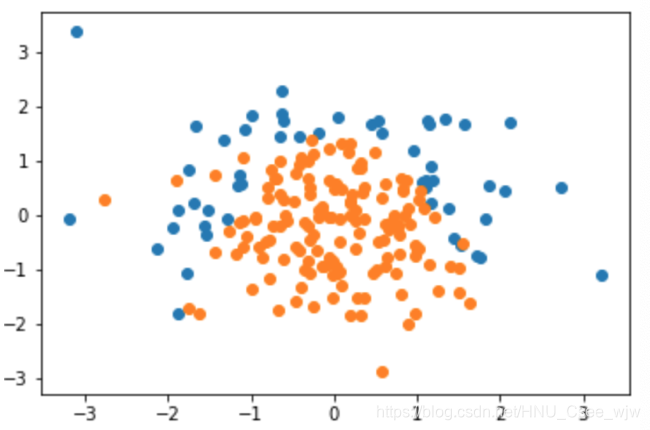
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666) 使用scikit-learn中的逻辑回归
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()
log_reg.fit(X_train, y_train)
"""
Out[4]:
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False)
"""
log_reg.score(X_train, y_train)
# Out[5]:
# 0.79333333333333333
def plot_decision_boundary(model, axis):
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1,1),
np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1,1)
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A', '#FFF59D','#90CAF9'])
plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap)
plot_decision_boundary(log_reg, axis=[-4, 4, -4, 4])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()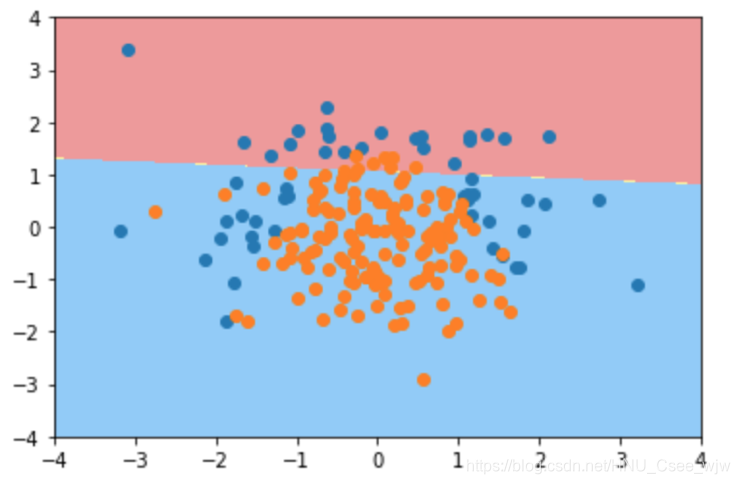
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.preprocessing import StandardScaler
# 1.添加多项式项 2.归一化 3.逻辑回归(自己实现的类,符合“构造函数,fit,predict,score”等标准)
def PolynomialLogisticRegression(degree):
return Pipeline([
('poly', PolynomialFeatures(degree=degree)),
('std_scaler', StandardScaler()),
('log_reg', LogisticRegression())
])
poly_log_reg = PolynomialLogisticRegression(degree=2)
poly_log_reg.fit(X_train, y_train)
"""
Out[9]:
Pipeline(memory=None,
steps=[('poly', PolynomialFeatures(degree=2, include_bias=True, interaction_only=False)), ('std_scaler', StandardScaler(copy=True, with_mean=True, with_std=True)), ('log_reg', LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False))])
"""
poly_log_reg.score(X_train, y_train)
# Out[10]:
# 0.91333333333333333
# 泛化能力
poly_log_reg.score(X_test, y_test)
# Out[11]:
# 0.93999999999999995
plot_decision_boundary(poly_log_reg, axis=[-4, 4, -4, 4])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()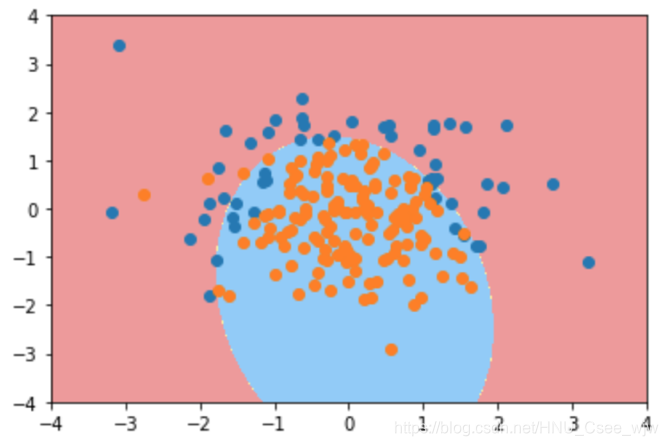
poly_log_reg2 = PolynomialLogisticRegression(degree=20)
poly_log_reg2.fit(X_train, y_train)
"""
Out[13]:
Pipeline(memory=None,
steps=[('poly', PolynomialFeatures(degree=20, include_bias=True, interaction_only=False)), ('std_scaler', StandardScaler(copy=True, with_mean=True, with_std=True)), ('log_reg', LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False))])
"""
poly_log_reg2.score(X_train, y_train)
# Out[14]:
# 0.93999999999999995
# 泛化能力,可以看出有一定的过拟合
poly_log_reg2.score(X_test, y_test)
# Out[15]:
# 0.92000000000000004
plot_decision_boundary(poly_log_reg2, axis=[-4, 4, -4, 4])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()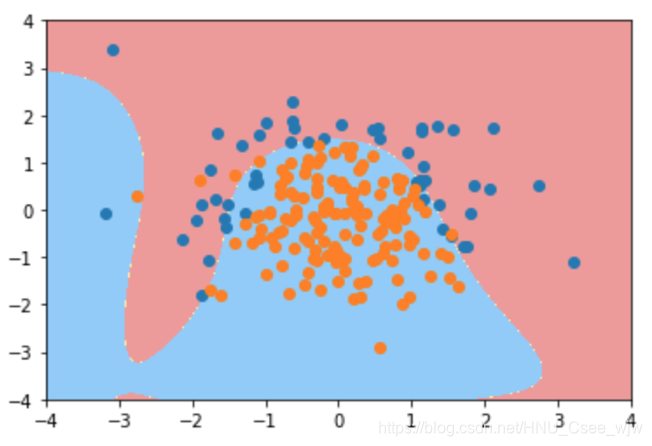
# 重新定义管道,传入正则项系数C
def PolynomialLogisticRegression(degree, C):
return Pipeline([
('poly', PolynomialFeatures(degree=degree)),
('std_scaler', StandardScaler()),
('log_reg', LogisticRegression(C=C))
])
poly_log_reg3 = PolynomialLogisticRegression(degree=20, C=0.1)
poly_log_reg3.fit(X_train, y_train)
"""
Out[18]:
Pipeline(memory=None,
steps=[('poly', PolynomialFeatures(degree=20, include_bias=True, interaction_only=False)), ('std_scaler', StandardScaler(copy=True, with_mean=True, with_std=True)), ('log_reg', LogisticRegression(C=0.1, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False))])
"""
poly_log_reg3.score(X_train, y_train)
# Out[19]:
# 0.85333333333333339
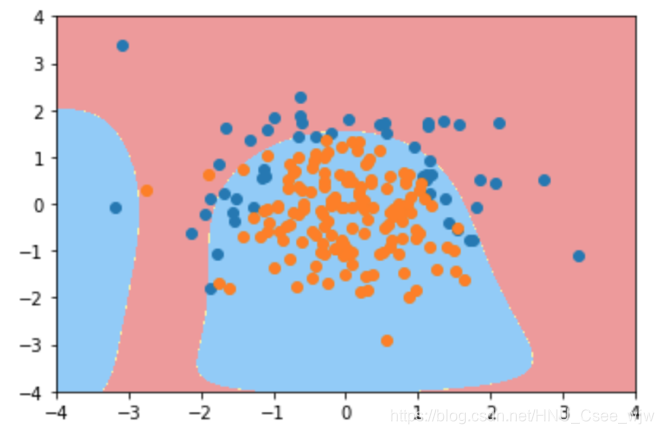
poly_log_reg3.score(X_test, y_test)
# Out[20]:
# 0.92000000000000004
plot_decision_boundary(poly_log_reg3, axis=[-4, 4, -4, 4])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()
加入正则项后更趋向于degree=2时的情况
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.preprocessing import StandardScaler
# 重新定义管道,传入正则项系数C,penalty
def PolynomialLogisticRegression(degree, C, penalty='12'):
return Pipeline([
('poly', PolynomialFeatures(degree=degree)),
('std_scaler', StandardScaler()),
('log_reg', LogisticRegression(C=C))
])
poly_log_reg4 = PolynomialLogisticRegression(degree=20, C=0.1, penalty='l1') # 使用L1正则项
poly_log_reg4.fit(X_train, y_train)
"""
Out[23]:
Pipeline(memory=None,
steps=[('poly', PolynomialFeatures(degree=20, include_bias=True, interaction_only=False)), ('std_scaler', StandardScaler(copy=True, with_mean=True, with_std=True)), ('log_reg', LogisticRegression(C=0.1, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False))])
"""
poly_log_reg4.score(X_train, y_train)
# Out[24]:
# 0.85333333333333339
poly_log_reg4.score(X_test, y_test)
# Out[25]:
# 0.92000000000000004
plot_decision_boundary(poly_log_reg4, axis=[-4, 4, -4, 4])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()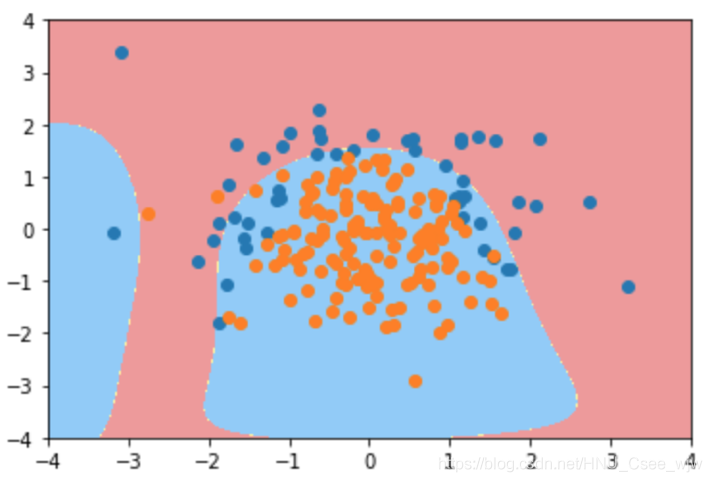
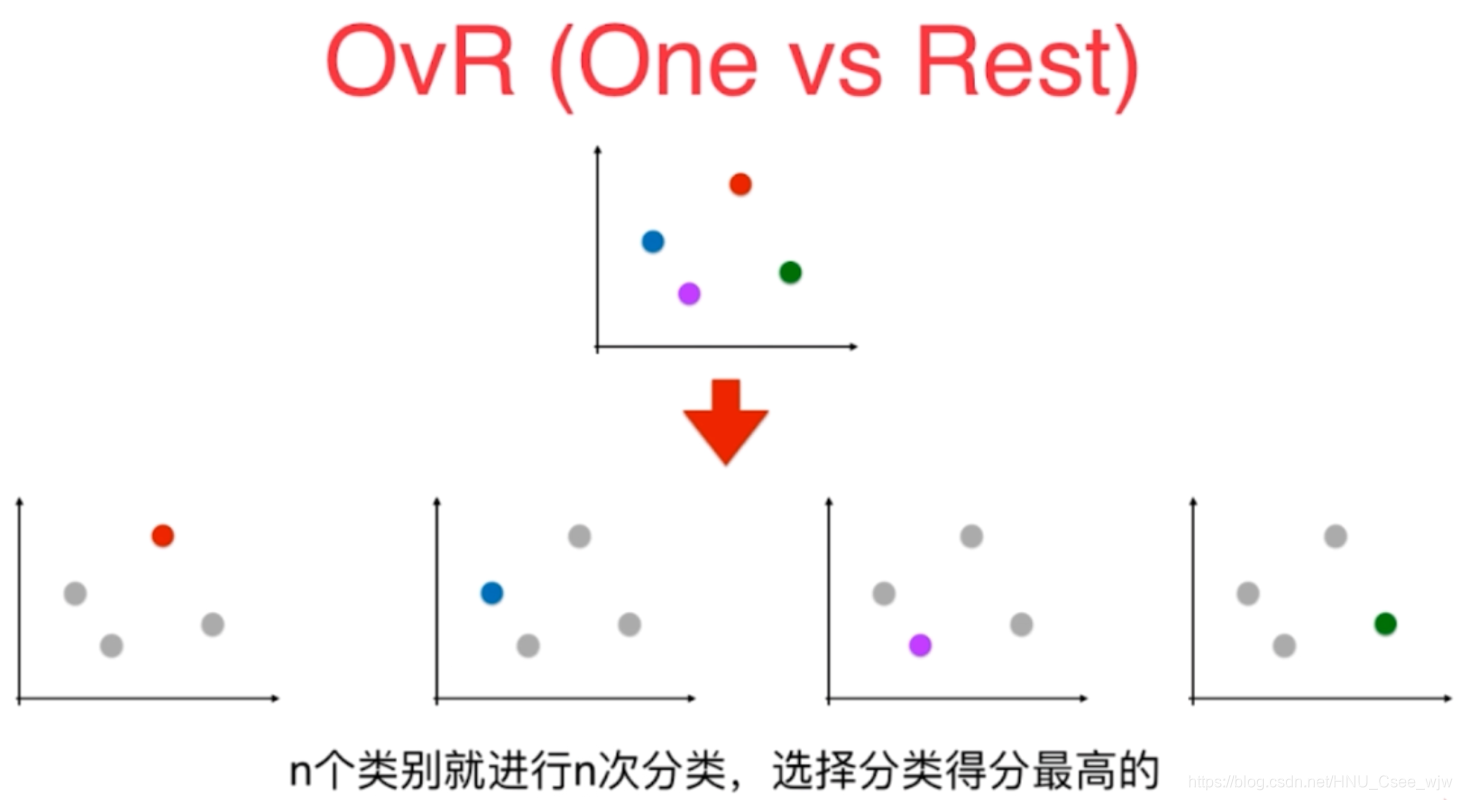
以上所讨论的逻辑回归只适用于解决二分类问题,这显然是不符合现实所需要的,所以为了使其可以解决多分类问题,发明了OvR与OvO算法,二者实现原理不同。
OvR:每次选取一个类别与其他所有类别进行二分类任务
OvO:每次挑出两个类别进行二分类任务
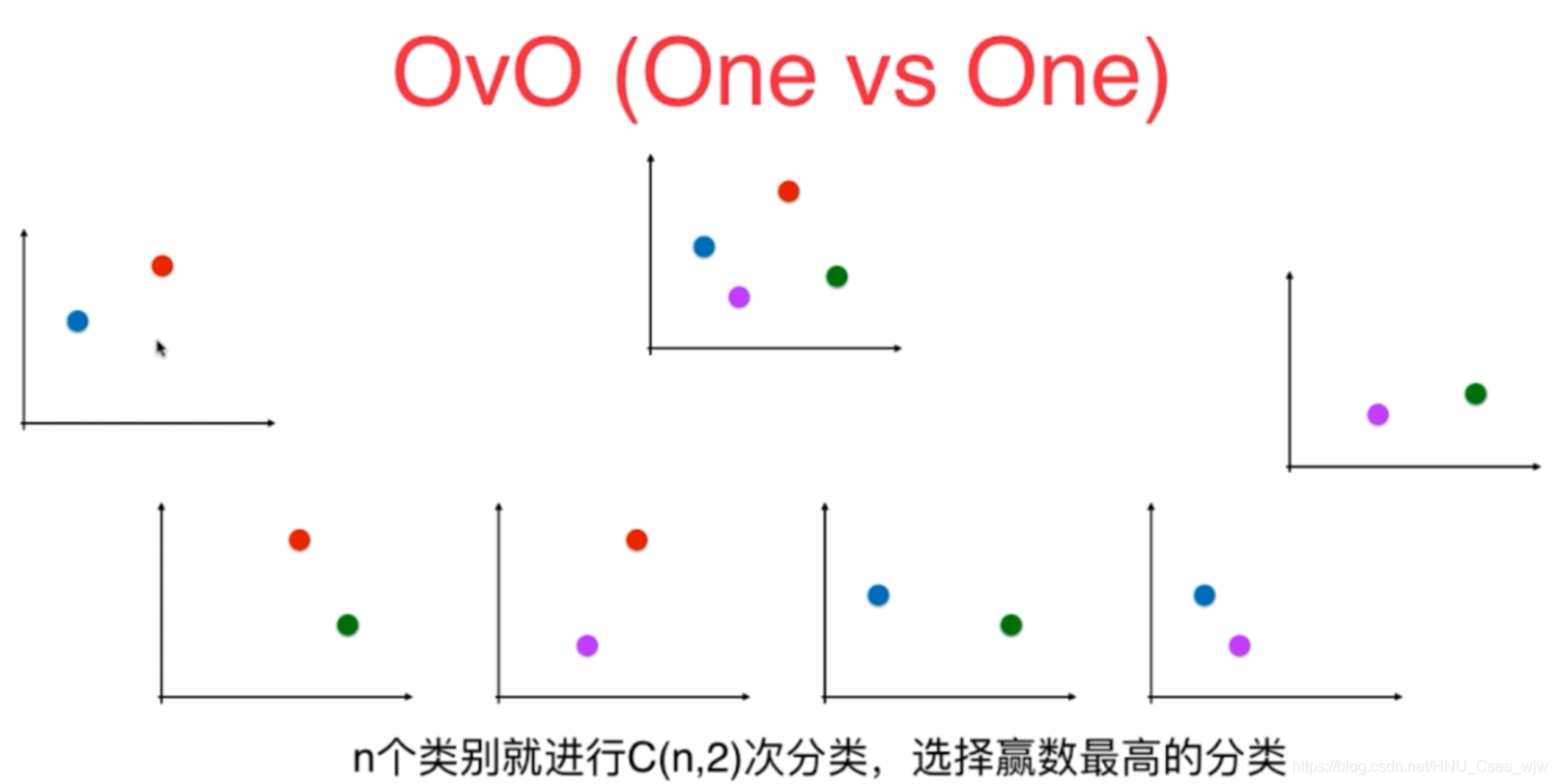
OvO耗时更久,结果更准确。
06 OvR和OvO
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data[:,:2]
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()
log_reg.fit(X_train, y_train)
"""
Out[3]:
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False)
"""
log_reg.score(X_test, y_test)
# Out[4]:
# 0.65789473684210531
def plot_decision_boundary(model, axis):
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1,1),
np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1,1)
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A', '#FFF59D','#90CAF9'])
plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap)
plot_decision_boundary(log_reg, axis=[4, 8.5, 1.5, 4.5])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.scatter(X[y==2,0], X[y==2,1])
plt.show()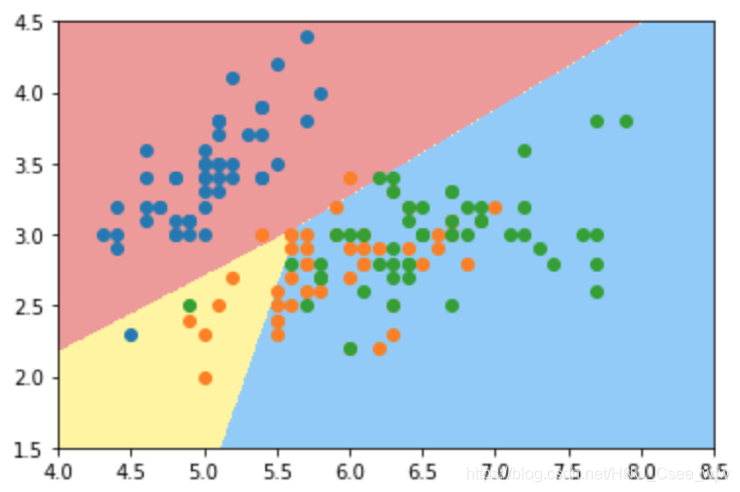
# 使用OvO,注意更换计算方式'newton-cg'
log_reg2 = LogisticRegression(multi_class='multinomial', solver='newton-cg')
log_reg2.fit(X_train, y_train)
log_reg2.score(X_test, y_test)
# Out[8]:
# 0.78947368421052633
plot_decision_boundary(log_reg2, axis=[4, 8.5, 1.5, 4.5])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.scatter(X[y==2,0], X[y==2,1])
plt.show()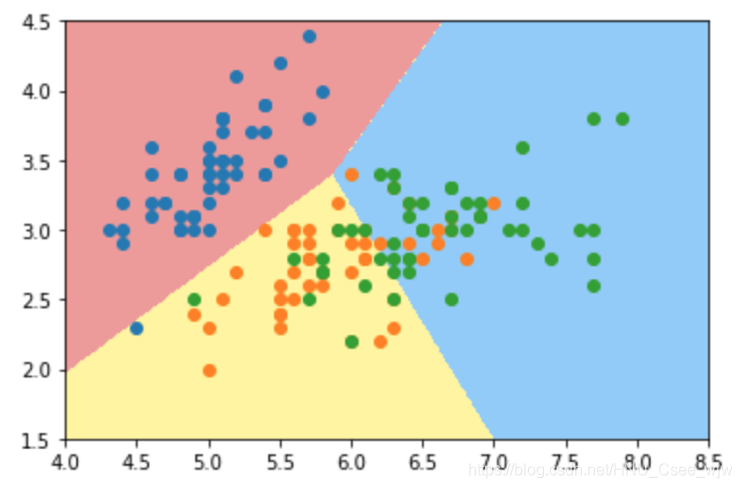
使用所有数据
X = iris.data
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
log_reg = LogisticRegression()
log_reg.fit(X_train, y_train)
log_reg.score(X_test, y_test)
# Out[11]:
# 0.94736842105263153
log_reg2 = LogisticRegression(multi_class='multinomial', solver='newton-cg')
log_reg2.fit(X_train, y_train)
log_reg2.score(X_test, y_test)
# Out[12]:
# 1.0OvO and OvR
from sklearn.multiclass import OneVsRestClassifier
# 传入二分类器
ovr = OneVsRestClassifier(log_reg)
ovr.fit(X_train, y_train)
ovr.score(X_test, y_test)
# Out[13]:
# 0.94736842105263153
from sklearn.multiclass import OneVsOneClassifier
ovo = OneVsOneClassifier(log_reg)
ovo.fit(X_train, y_train)
ovo.score(X_test, y_test)
# Out[14]:
# 1.0