一、利用scikit-learn提供的函数进行运算
在下面这个示例中,我们会更多的使用仅属于Scikit-Learn中的函数来完成任务。
下面这个例子中的数据源于1936年统计学领域的一代宗师费希尔发表的一篇重要论文。彼时他收集了三种鸢尾花(分别标记为setosa、versicolor和virginica)的花萼和花瓣数据。包括花萼的长度和宽度,以及花瓣的长度和宽度。我们将根据这四个特征(中的两个)来建立Logistic Regression模型从而实现对三种鸢尾花的分类判别任务。
首先我们引入一些必要的头文件,然后读入数据(注意:仅仅使用前两个特征)
import numpy as np
from sklearn import datasets,linear_model #数据集,线性模型
from sklearn.cross_validation import train_test_split #交叉验证
from sklearn.metrics import accuracy_score,classification_report #对结果进行评估
iris = datasets.load_iris() #读入数据集
X = iris.data[:,:2] #获取样本数据
Y = iris.target #获取样本标签
for i in range(5): #打印样本数据,以便于进行查看数据
print(X[i],Y[i])作为演示,我们来提取其中的前5行数据(包括特征和标签),输出如下。前面我们提到数据中共包含三种鸢尾花(分别标记为setosa、versicolor和virginica),所以这里的标签 使用的是0,1和2三个数字来分别表示对应的鸢尾花品种,显然前面5行都属于标签为0的鸢尾花。而且一共有150个样本数据。
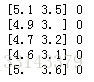
现在我们利用train_test_split函数来对原始数据集进行分类采样,取其中20%作为测试数据集,取其中80%作为训练数据集。
#对样本数据进行分解,以便于后面进行交叉验证
X_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size=0.3,random_state=0)然后,我们便可以利用LogisticRegression函数来训练一个分类器。
#定义线性模型:配置求解器等参数
lgreg = linear_model.LogisticRegression(C=1e5,solver='lbfgs',multi_class="multinomial")
#进行拟合训练
lgreg.fit(X_train,Y_train)-
- For small datasets, ‘liblinear’ is a good choice, whereas ‘sag’ is
-
faster for large ones.
-
- For multiclass problems, only ‘newton-cg’ and ‘lbfgs’ handle
-
multinomial loss; ‘sag’ and ‘liblinear’ are limited toone-versus-rest schemes.
参数multi_class的可选值有2个:‘ovr’, ‘multinomial’。多分类问题既可以使用‘ovr’,也可以使用 ‘multinomial’。但是如果你的选项是 ‘ovr’,那么相当于对每个标签都执行一个二分类处理。Else the loss minimised is the multinomial loss fit acrossthe entire probability distribution. 选项 ‘multinomial’ 则仅适用于将参数solver置为‘lbfgs’时的情况。
然后再利用已经得到的分类器来对测试数据集进行预测、检验。
#利用训练好的模型进行预测
Y_predict = lgreg.predict(X_test)
print("accuracy score:")
print(accuracy_score(Y_test,Y_predict))
print(classification_report(Y_test,Y_predict))
lgreg_proba = lgreg.predict_proba(X_test) #概率预测
lgreg_predict = lgreg.predict(X_test) #分类预测
for i in range(5):
print(lgreg_proba[i])
print("predict label: ",lgreg_predict[i])
print("Correct label: ",Y_test[i])
本例程的全部代码如下:
import numpy as np
from sklearn import datasets,linear_model #数据集,线性模型
from sklearn.cross_validation import train_test_split #交叉验证
from sklearn.metrics import accuracy_score,classification_report #对结果进行评估
iris = datasets.load_iris() #读入数据集
X = iris.data[:,:2] #获取样本数据
Y = iris.target #获取样本标签
for i in range(5): #打印样本数据,以便于进行查看数据
print(X[i],Y[i])
#对样本数据进行分解,以便于后面进行交叉验证
X_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size=0.3,random_state=0)
#定义线性模型:配置求解器等参数
lgreg = linear_model.LogisticRegression(C=1e5,solver='lbfgs',multi_class="multinomial")
#进行拟合训练
lgreg.fit(X_train,Y_train)
#利用训练好的模型进行预测
Y_predict = lgreg.predict(X_test)
print("accuracy score:")
print(accuracy_score(Y_test,Y_predict))
print(classification_report(Y_test,Y_predict))
lgreg_proba = lgreg.predict_proba(X_test) #概率预测
lgreg_predict = lgreg.predict(X_test) #分类预测
for i in range(5):
print(lgreg_proba[i])
print("predict label: ",lgreg_predict[i])
print("Correct label: ",Y_test[i])在Scikit-Learn的资源中,已经提供有一个利用Logistic Regression进行数据分类的示例,链接如下:
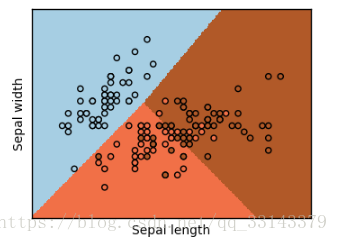
http://scikit-learn.org/stable/auto_examples/linear_model/plot_iris_logistic.html 。这个程序中演示了如何利用matplotlib进行画图。具体代码如下:
%matplotlib inline
print(__doc__)
# Code source: Gaël Varoquaux
# Modified for documentation by Jaques Grobler
# License: BSD 3 clause
import numpy as np
import matplotlib.pyplot as plt
from sklearn import linear_model, datasets
#导入数据
iris = datasets.load_iris()
X = iris.data[:, :2] #仅选取前两种特征
Y = iris.target
h = 0.02 #mesh时的步长
logreg = linear_model.LogisticRegression(C=1e5) #定义LR模型
#利用模型对数据进行拟合
logreg.fit(X, Y)
#图的边界定义
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
# xx记录生成的mesh的点的横坐标值(矩阵形式),yy记录点的纵坐标值(矩阵形式)
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# 先将xx和yy矩阵变成(列)向量,然后对两个向量按列(行不变)形式组成矩阵(mx2)
# 最后对生成的mesh点进行LR预测
Z = logreg.predict(np.c_[xx.ravel(), yy.ravel()])
# 对LR预测值进行维度变换,以满足mesh绘图
Z = Z.reshape(xx.shape)
# 定义figure图:序号及大小
plt.figure(1, figsize=(4, 3))
# 绘制mesh图,cmap为两两相近色图
plt.pcolormesh(xx, yy, Z, cmap=plt.cm.Paired)
# 绘制样本散点图
plt.scatter(X[:, 0], X[:, 1], c=Y, edgecolors='k', cmap=plt.cm.Paired)
# 定义横纵坐标
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
# 设置横纵轴刻度范围,防止出现白边
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
# 取消刻度显示
plt.xticks(())
plt.yticks(())
plt.show()