人体姿态估计的分布感知坐标表示
摘要: 热图才是姿态估计的实际坐标表示,本文对热图进行深入研究。本项工作首次发现:将预测热图解码为原始图像空间中的最终关节坐标的过程对性能影响很大。 本文进一步探讨了标准坐标解码法的设计局限,并提出了一种分布感知解码方法。此外,通过生成无偏差/准确热图来改进标准坐标编码过程(即GT 坐标转换为热图)。将两者结合,本文提出一种新的关键点的分布感知坐标表示(Distribution-Aware coordinate Representation of Keypoints:DARK)方法。DARK 是 model-agnostic且plug-in。DARK给现有的人体姿态估计模型带来了显著的性能提升,大量实验表明,DARK在MPII和COCO上实现了sota。此外,DARK在ICCV 2019 COCO关键点挑战赛中获得第二名。代码链接:https://github.com/ ilovepose/DarkPose
1. Introduction
姿态估计任务需要识别细粒度的关节坐标,但由于不同的服装风格、任意遮挡和不受约束的背景,身体关节的外观变化很大,给这项任务带来了挑战。类似于图像分类中用 one-hot vector 作为目标类的 label representation ,姿态CNN 模型也需要一个 label representation(label representation用于编码标签标注,例如在ImageNet中,1000个对象类标签对应1000个one-hot vector,与用于编码数据样本的 data representation 完全不同) 编码身体关节坐标label ,从而在训练期间量化和计算被监督的学习损失,并正确推断关节坐标。姿态估计中使用的 label representation 是以每个关节GT坐标为中心的 2D 高斯分布/核生成的坐标热图。热图在 GT 位置周围提供空间支持,不仅考虑上下文线索,还考虑固有的目标位置模糊性,这类似于class label smoothing regularisation,可以有效降低训练过程中的过拟合。
热图标签的主要问题是:计算成本是输入图像分辨率的二次函数,阻碍了CNN模型处理高分辨率原始图像数据。如图1所示,降低计算量的标准策略是通过数据预处理将人体边界框降采样为确定的小分辨率,再喂给人体姿态估计模型预测热图,之后通过分辨率转换,将热图最大激活位置映射回原始图像空间坐标,该过程称为:coordinate decoding。为缓解降低分辨率过程可能引入的量化误差,现有的坐标解码过程会根据从最高激活到第二高激活方向执行一个 hand-crafted shifting。

目前业内对坐标编码解码的关注不够多,本文揭示了坐标表示对模型性能的重要作用。例如,上述的 shifting 操作给 HRNet-W32 在COCO val set 上带来 5.7% AP的涨点。
本文专门研究坐标表示的编码解码问题,揭示了热图分辨率是阻碍使用较小输入分辨率进行模型快速推断的主要障碍。当输入分辨率从256×192 降至128×96 时,在COCO val set上 HRNet-W32的性能从 74.4% 掉到 66.9%,但模型的推理成本也从 7.1×109 降至 1.8×109 FLOPs。
关键点检测的 关键限制在于坐标解码过程。 现在的标准shifting操作是有效的,本文提出一种原则性的 distribution-aware 表示方法,以 sub-pixel 精度进行更准确的定位。具体而言,分布感知通过基于泰勒展项的分布近似来综合考虑热图激活的分布信息。此外,我们观察到,生成GT热图的标准方法存在量化误差,导致不精确的监督和较差的模型性能,为解决此问题,我们允许高斯核以sub-pixel为中心,生成unbiased heatmaps。
本文贡献在于:我们发现了坐标表示在人体姿态估计中的重要性,并提出了一种关键点的分布感知坐标表示(Distribution-Aware coordinate Representation of Keypoints:DARK)方法,该方法包括两个关键组件:(1) efficient Taylor-expansion based coordinate decoding;(2) unbiased sub-pixel centred coordinate encoding。 现有的姿态估计方法无需修改算法,可以无缝从DARK中受益。MPII和COCO上广泛的实验表明该方法能提升sota人体姿态估计模型的性能,实现sota单模型精度。当使用更小输入分辨率图像时,在显著提高模型推理效率的情况下,DARK有助于减小性能的降低,从而促进嵌入式 AI 场景所需的 low-latency 和 low-energy 应用。
2. Related Work
坐标回归: 直接坐标回归表示缺乏空间和上下文信息。
热图回归: 热图表示巧妙解决了上述限制。姿态估计的主流研究重点是设计网络架构,以便更有效地回归热图监督。代表性的设计改进包括:顺序建模、扩大感受野、位置voting、中间监督、成对关系建模、树结构建模、分层上下文学习、金字塔残差学习、级联金字塔学习、知识引导学习、主动学习、对抗学习、转置卷积上采样、多尺度监督、注意力机制和保持高分辨率表示。
本文不仅揭示了分辨率降低对热图表示的巨大影响,还提出了一种原则性的坐标表示方法,以提高现有模型的性能。最重要的是,DARK 可以无缝集成,无需更改模型设计。
3. Methodology
训练过程中,为便于模型学习,将标记的GT关节坐标编码为热图作为学习目标,测试时需要将预测的热图解码为原始图像坐标空间中的坐标。
3.1. Coordinate Decoding
姿态估计的坐标解码是将每张单独关节的预测热图转换为原始图像空间坐标的过程。若假设热图与原始图像的size一致,那只需要找到热图的最大激活位置即为预测关节坐标。但这个假设往往不成立,我们需要通过一个 sample-specific unconstrained factor λ ∈ R+,将热图上采样到原始图像分辨率。这涉及 sub-pixel 定位问题。下面先回顾现有姿态估计模型中使用的标准坐标解码方法。
The standard coordinate decoding method。 具体而言,给定由训练模型预测的热图 h,先确定最大(m)和次大(s)激活的坐标。然后将关节位置预测为:

∥ . ∥ 2 \left \|. \right \|_2 ∥.∥2 代表向量的大小,上式意味着在热图空间中,预测的最大激活有0.25像素(即,sub-pixel)向第二大激活shiftting。原始图像中的最终坐标预测计算如下:

eq(1) 中的 sub-pixel shifting 用于补偿图像分辨率下采样产生的量化误差,也就是说,预测热图的最大激活并不对应于关节在原始坐标空间中的精确位置,而仅对应于粗略位置,表1显示了这种 shifting 带来了显著的性能增益,这也解释了为什么它经常被用作模型测试的标准操作。有趣的是,据我们所知,还没有具体的工作深入研究这种操作对人体姿态估计性能的影响,因此它的真正意义从未在文献中被承认。这种标准方法在设计中缺乏直觉和解释,我们通过提出一种 shifting estimation 的原则性方法来填补这一空白,并最终实现更精确的人体姿态估计。
Our coordinate decoding method. 不同于上述没有设计理由和基本原理的依靠手工设计的 off-set,我们的坐标解码方法探索预测热图的分布结构,以推断潜在的最大激活。
具体而言,为获得 sub-pixel 级的准确位置,假设预测热图与GT热图一样遵循2D高斯分布,因此预测热图可以表示为:

为降低近似难度,使用对数将原始指数形式的 G \mathcal{G} G 转换为二次形式 P \mathcal{P} P,在保持原始最大激活位置的同时便于推理:
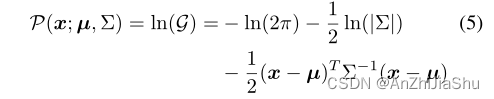
我们的目的是估计 μ ,作为分布的极值点,位置 µ 处的一阶导数满足以下条件:

采用泰勒展项探索该条件,通过在预测热图的最大激活m处评估的泰勒级数(直到二次项)来近似激活 P ( µ ) \mathcal{P}(µ) P(µ):

对eq(7)等号两边同时对 求导(这是原论文中没有解释的推导),得到:

选择 预测热图最大激活位置 m 近似 µ 是因为 m 代表了接近µ的好的粗糙关节预测。
μ 是高斯分布的中心,D′(μ)=0 ,联立等式6, 7, 8,得到:

与仅考虑热图中第二大值激活的标准方法相反,本文提出的坐标解码充分探索热图分布统计来准确揭示潜在最大值。理论上,我们的方法基于训练监督一致假设下的一个原则性分布近似,即假设预测热图也遵循高斯分布。关键是它只需要计算每张热图一个像素位置的一阶导数和二阶导数,因此它是计算有效的。因此,现有的人体姿态估计方法可以在不增加任何计算成本的情况下受益。
Heatmap distribution modulation 热图分布调制. 由于所提出的坐标解码方法基于高斯分布假设,因此有必要检查该条件的满足程度。相比于用于训练的GT热图数据,人体姿态估计模型预测的热图通常不是良好的高斯结构,如图3(a)所示,预测热图常在最大激活附近呈现多个峰值,这不利于解码性能,采用预先调节热图分布的方式解决此问题。
具体而言,为了满足要求,使用与训练数据方差相同的高斯核 K 来消除热图h 中多峰值的影响,形式上为:

为保持原始热图大小,最终通过下列转换公式 scale h′,使其最大激活与 h 的相等。

实验验证了这种分布调制能进一步提高坐标解码方法的性能(表3),其视觉效果和定性评估如图 3(b) 所示。
总结: 图2总结了我们的坐标解码方法,共涉及三个步骤:(a) 热图分布调制(等式(10), (11));(b)通过泰勒展开以 sub-pixel 精度进行的Distribution-aware joint localisation(等式(3)-(9)),以及 (c)恢复到原始坐标空间的分辨率(等式2)。这些步骤都不会产生高计算成本,可以即插即用。


3.2. Coordinate Encoding
坐标解码的问题根源在于分辨率的降低,坐标编码也同样如此。标准的坐标编码先将人体图像下采样至模型的 input size,因此,在生成热图之前,需要相应变换 GT 关节坐标。
用 g=(u, v) 表示关节的 gt 坐标。分辨率降低定义为:

通常,为便于生成kernel,通常量化g′:

quantise() 指定了一个量化函数,常用选项包括 floor、ceil 和 round(floor: 求小于参数的最大整数。例如:Math.floor(-4.2) = -5.0;ceil: 求大于参数的最小整数。例如:Math.ceil(5.6) = 6.0;round: 对小数进行四舍五入后的结果。返回int类型,例如:Math.round(-4.6) = -5)。
随后,通过以下方法合成以量化坐标g′′为中心的热图:

显然,由于量化误差,以上述方式生成的热图不准确且有偏差(图4所示),这可能引入次优监督信号并降低模型性能。

为了解决此问题,只需摒弃量化操作,仍然应用等式(14),但将 g′′ 替换为 g′。表3将展式该方法的优势。
3.3. Integration with State-of-the-Art Models
DARK与模型无关,可以与任何现有的基于热图的姿态模型无缝集成,不涉及对模型的更改。训练期间的唯一变化是基于精确关节坐标生成的 GT 热图数据。在测试时,将模型(如HRNet)预测的热图作为输入,并在原始图像空间中输出更精确的关节坐标。在整个生命周期中不改变模型,以最大化我们方法的通用性和可扩展性。
4. Experiments
4.1. Evaluating Coordinate Representation
默认使用 HRNet-W32 作backbone,128×96作为输入大小,报告COCO val set 上的结果。
(i) Coordinate decoding 坐标解码: 表1、表2。


(ii) Coordinate encoding 坐标编码: 表3.

(iii) Input resolution 输入分辨率: 表4.

(iv) Generality 泛化性。 表5,图5.


(v) Complexity 复杂性: 在输入大小为 128×96 的 HRNet-W32 中测试DARK 对推理效率的影响。在具有一个i9-7920X CPU和一个Titan V GPU的机器上,低效 python 环境下,运行速度从360 fps降低到320 fps,即下降11%,因此DARK的额外成本合理。基于本地编程语言(例如C/C++)的版本可以进一步加快推理速度。
4.2. Comparison to Coordinate Regression

4.3. Comparison to State-of-the-Art Methods
(i) Evaluation on COCO. 表7:

(ii) Evaluation on MPII. 表8

4.4. COCO Keypoints Detection Challenge
表9所示,我们的方法在多人姿态估计的 test-dev 上实现了78.9%AP,在test-challenge set上实现76.4%的AP。更多详细信息参阅技术报告 [Joint coco and mapillary workshop at iccv 2019 keypoint detection challenge track technical report: Distribution-aware coordinate representation for human pose estimation]。
5. Conclusion
本文提出了一种新的 ready-to-use 且 plug-in 分布感知坐标表示(DARK)来进行模型训练和推理。现有的 sota 模型无需任何算法修改即可从DARK方法中无缝受益,且成本可忽略。
热图法的Target和Output都是基于高斯分布假设的,而高斯分布的形状和参数是预先设定好的,也就是说:完全可以根据理论上的高斯分布形状,对输出的低分辨率的结果进行信息补全。在所有参数和分布已知的情况下,高斯分布的形状对我们来说就像有一张无限高分辨率的模板图,而模型输出的是这个模板的低分辨率图,我们完全可以通过比对手里的高清图,来找到理论上的高斯分布极值点坐标,从而将低分辨率Argmax抹去的小数恢复出来。
而这种信息补全的手段,正是泰勒展开。
对于泰勒展开的思想,简单来说就是,函数图像上每一个点,由于点是连续的,因而都蕴含着关于周围点的信息,通过该点的一阶导数,我们可以知道下一个点会比这个点高还是低,通过二阶导数,我们可以知道一阶导数的变化趋势,也就是这种升高和降低的力度变化,理论上来说阶数越高我们能还原出来的信息就越多,从而越逼近真实函数值 (但高斯分布最高只有二阶导数)。
由于高斯分布是我们已知的信息,所以我们很容易就能求出输出图像最大值点上的一阶导数和二阶导数,从而对结果进行信息补充,在一定范围内修正量化误差。