0 - 背景
人体姿态识别是计算机视觉的基础的具有挑战性的任务,其中对于身体部位的尺度变化性是存在的一个显著挑战。虽然金字塔方法广泛应用于解决此类问题,但该方法还是没有很好的被探索,我们设计了一个Pyramid Residual Module(PRMs)来提高DCNNs的尺度不变性。
并且我们发现现存的初始化方法并不使用multi-branch的网络,我们在当前的权重初始化方法上提出了新的方法并给出了理论证明。
1 - 贡献
- 提出Pyramid Residual Module来提高深度模型的尺度不变性问题,而只是比DCNNs多一点点复杂性
- 分析了DCNNs多输入或者多输出层的初始化问题(当前MSR和Xavier初始化方法不适用multi-branch网络),提出了新的权重初始化策略(可以用于许多网络架构,包括inception models和ResNets)
- 我们发现在一些场景中激活变化累积是由identity mapping造成的,运用一种简单的有效解决方案
2 - 整体思路
2.1 - 尺度不变性

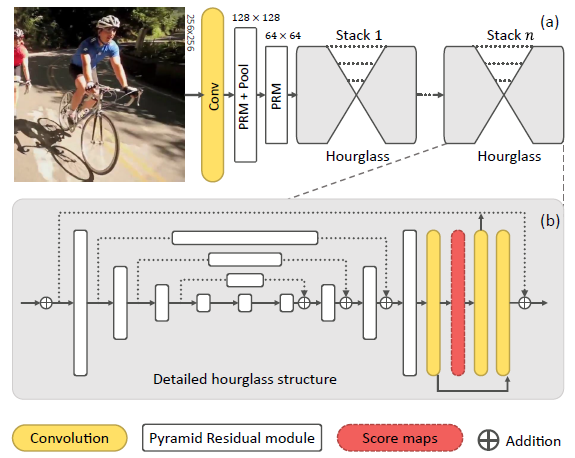
如上图,(a)和(b)由于透视关系,(a)中的上半身身体部位显得很大,而相反(b)中的上半身部位显得小,如果对于不同尺度的身体部位运用相同检测器,则尺度的变化将严重影响检测器的效果,因此在检测的时候需要在图像多变的情况下保证尺度不变性。论文用了如下大致架构:

2.2 - Pyramid Residual Modules (PRMs)
PRM被形式化描述为:
$$x^{(l+1)}=x^{(l)}+P(x^{(l)};W^{(l)})$$
其中$P(x^{(l)};W^{(l)})$是特征金字塔,可以被展开为:
$$P(x^{(l)};W^{(l)})=g\begin{pmatrix}\sum_{c=1}^{C}f_c(x^{(l)};w_{f_c}^{(l)});w_g^{(l)}\end{pmatrix}+f_0(x^{(l)};w_{f_o}^{(l)})$$
其中$C$为金字塔的层数,$f_c(\cdot)$为对于c-th层金字塔的转换,$W^{(l)}=\{w_{f_c}^{(l)},w_g^{(l)}\}_{c=0}^C$是参数集合。 通过转换$f_c(\cdot)$的输出将通过求和进行合并,并且通过卷积核为$g(\cdot)$的卷积。pyramid residual module图解如下,为了减少计算以及空间的复杂度,每一个$f_c(\cdot)$被组织成bottleneck架构(有点像ResNet,例如通过$1 \times 1$卷积核降低空间维度,而后新的特征通过将$3 \times 3$卷积核应用到一个下采样的输入特征集合上,最后所有新的特征上采样到同一个维度而后合并)。
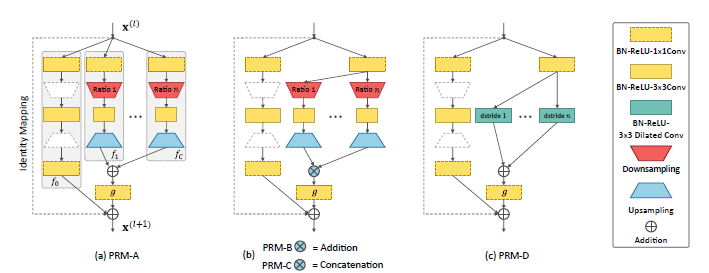
通过比较,PRM-B的参数更少,需要更少的计算资源但是与其它结构有可比的性能。
2.3 - fractional max-pooling
由于传统的pooling操作对于像素的减少太快以至于太过于粗糙,因此论文提出了一种新的fractional max-pooling方式,使得下采样的尺度平滑,金字塔的c-th层的下采样率定义为:
$$s_c=2^{-M\frac{c}{C}},\ c=0,...,C,M\geq 1$$
其中$s_c\in [2^{-M},1]$表示了与输入特征分辨率的关系。在实验中,作者的设置为$M=1$以及$C=4$,使得最低的层刚好是输入分辨率的一半。
2.4 - 评估策略
通过高斯方法来表示关键点,对于每一个关键点需要一个评分地图(score map)。例如,对于真实标签落在$z_k=(x_k,y_k)$的第$k$个关键点,其评分地图定义为:
$$S_k(p)\sim N(z_k,\Sigma )$$
其中$p\in R^2$表示了坐标,$\Sigma$是identity matrix $I$的经验集合,每一个沙漏网络预测$K$个评分地图,有$\hat{S}_k=\{\hat{S}_k\}_{k=1}^K$,损失函数定义如下:
$$L=\frac{1}{2}\sum_{n=1}^N\sum_{k=1}^{K}\begin{Vmatrix}S_k-\hat{S}_k\end{Vmatrix}^2$$
最后预测时候通过如下公式得到精确关键点坐标:
$$\hat{z}_k=arg\mathop{max}_p\hat{S}_k(p),k=1,...,K$$