
论文链接:Simple Baselines for Human Pose Estimation and Tracking
时间:2018.04.17 ECCV 2018
作者团队:Bin Xiao, Haiping Wu, and Yichen Wei
分类:计算机视觉–人体关键点检测–2D top-down
目录:
1.Simple Baseline背景
2.Simple Baseline姿态识别
3.Simple Baseline轨迹追踪
4.Simple Baseline网络架构图
5.引用
1.主要在于学习记录,如有侵权,私聊我修改
2.水平有限,不足之处感谢指出
1.Simple Baseline背景
coco2018关键点检测项目的亚军方案,方法简洁明了,但效果惊艳。
作者认为目前的姿态估计方法都太过于复杂,并且有显著的差异,比如hourglass,open pose,cpn等等,比较这些工作的差异性,更多体现在系统层面而不是信息层面。
作者在本文提出了一个既精确(sota水平),又简单(网络结构非常简单,见下文)的姿态估计方法,作为一个baseline,希望能激发一些新的ideas和简化评估方式。
2.Simple Baseline姿态识别
- 网络结构部分
普通的backbone(用resnet50就很好)加一些转置卷积层(作为一个head network),没有skip connection传递特征,没有任何的特征融合,网络结构非常简单,相较于Hourglass和CPN,唯一较为新颖的点是引入了Deconvolution来替换Upsampling与convolution组成的结构。作者认为这可能是得到heatmaps的最简单方式,并且包含了从深到浅的特征。
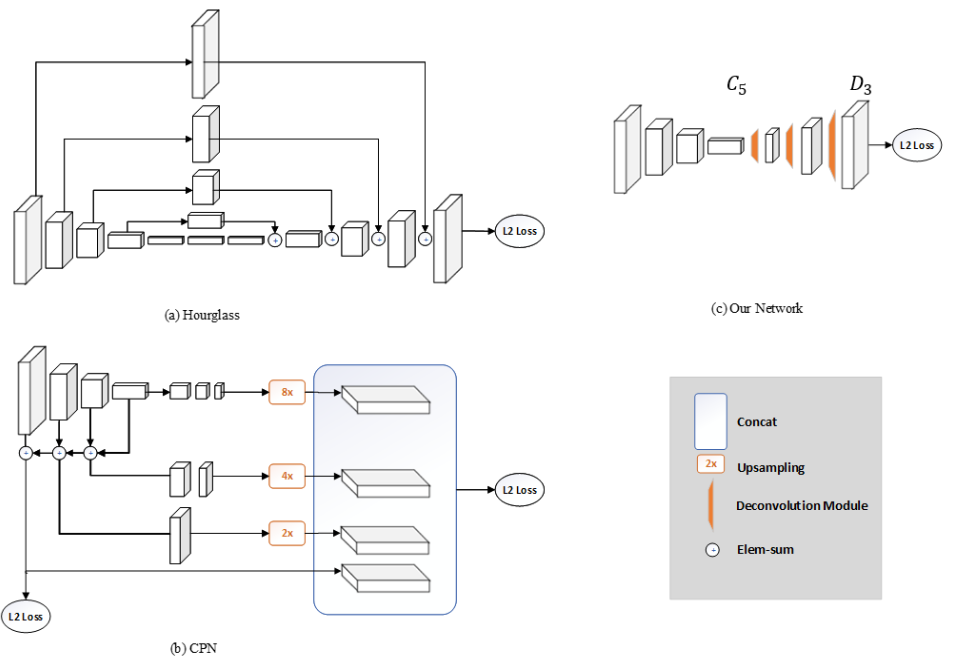
在 backbone 后添加几个 deconv 层,每个 deconv 后都接着 BN 层和 ReLU,每个 deconv 的 channel 数都为256,kernel_size 为4,stride 为2。最后在预测层使用一个1*1 conv 得到对应 channel 的 heatmap。
普通L2 loss,只在最后的输出算loss,并没有中继监督。 - 结果评估
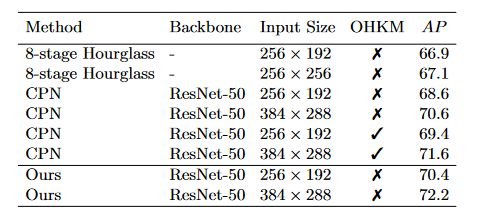
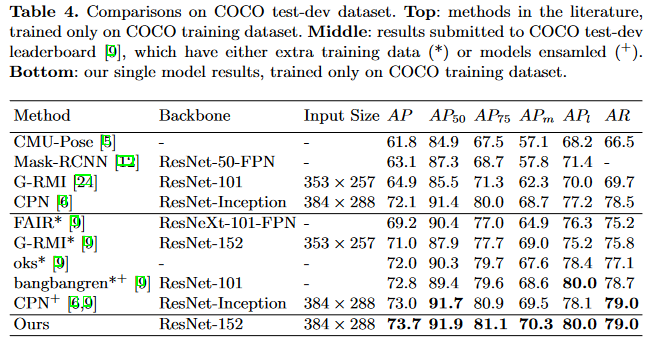
本文的方法在COCO关键点检测的任务上比CPN,Hourglass得到了更高的AP:
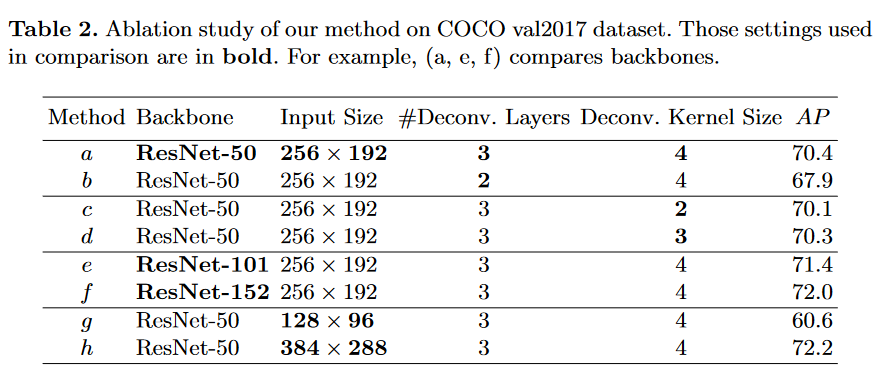
消融实验:
从heatmaps的尺寸,deconv的卷积核尺寸,backbone结构,输入图像尺寸等4个方面分别作了对比。heatmaps尺寸最好是64*48,三层deconv,kernel的size最好是4,backbone是越大越好,图像尺寸越大越好,但是后两者会极大增加计算量和显存。要做好精度和速度的平衡。
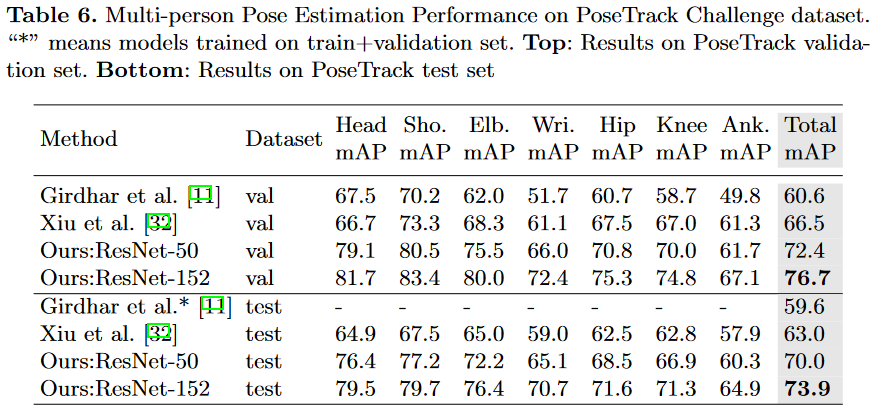
3.Simple Baseline轨迹追踪
1. Pose Track 基本都是对边框和ID进行跟踪。相较于贪婪匹配两帧中预测的 bounding box IoU,本文采用的跟踪管道有两点不同:解决多人轨迹追踪的原本算法是视频第一帧中每个检测到的人给一个id,之后的每一帧检测到的人都和上一帧检测到的人通过某种度量方式(IOU)算相似度,将相似度大的作为同一个id,没有匹配到的分配一个新的id。
改进点:(1)使用光流法补充一些检测框,用以解决检测网络的漏检问题。(2)使用 Object Keypoint Similarity (OKS)代替检测框的IOU来计算相似度。因为当人的动作比较快时,用IOU可能并不合理。
OKS计算公式:

使用光流法计算某一帧的关键点会出现在的另外一帧的位置,然后用预测前后的关键点之间计算OKS,作为两帧之间的不同人的相似度值。
2. 结果评估
4.Simple Baseline网络架构图
