一、前言
线性回归是机器学习的基础,目前很多机器学习算法都是从这些基础算法演变而来,本着打算巩固基础知识的目的,一起回顾一下线性回归。
1.数据回归的目的
在介绍线性回归前,我们先了解回归分析的作用,回归分析就是将一系列的影响因素 x 和结果 y 进行拟合得到一个方程,然后用这个方程对同类事件进行预测。在简单应用中,我们可以对过去的销售额和广告费用进行拟合(广告费用作为x,销售额作为y),来预测广告费用对销售额的影响。
二、线性回归
线性回归可分为一元回归和多元回归,一元回归就是只有一个影响因子,也就是大家熟悉的线性方程,多元回归就是有多个影响因子。一元线性回归方程是 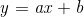
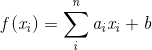
1.一元线性回归
如下图所示:
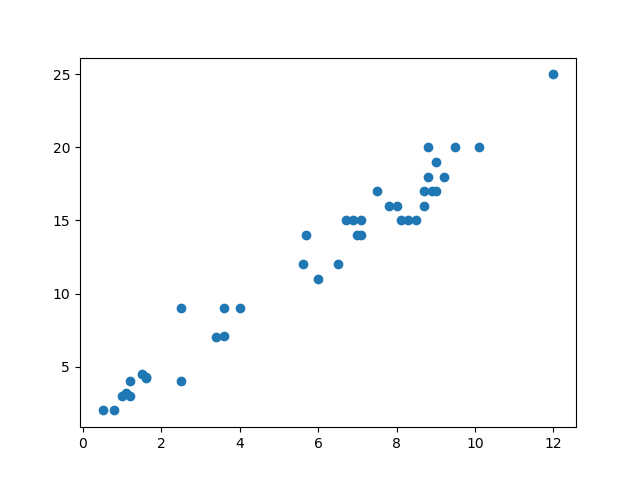
这是一系列点在坐标上的分布,这些点的分布很像一条直线,而我们的目的就是找到这条直线,即在已知 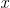


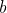
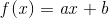
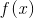
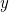

均方差对应了常用的欧式距离,我们的目的也就是取得所有点到直线距离的最小值。
我们令 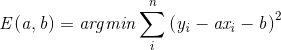
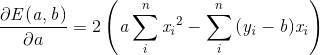

根据数学结论偏导数为0时,可以取得最小值,我们令上式为零,经过变换可得,
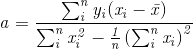
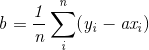
其中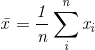
显然根据上述式子我们可以很容易求出
# coding=utf8
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
'''
description:python线性回归
author:谢宜廷
mail:[email protected]
'''
#读取数据
line_sample = pd.read_csv('linear_regression_sample.csv')
def plot_data(data):
x = data['x'].as_matrix().reshape() # 注意此处.reshape(-1, 1),因为此处x是一维的,每行元素要转换成向量
y = data['y'].as_matrix()
#初始化线性回归
regr = LinearRegression()
#数据拟合
regr.fit(x,y)
plt.plot(x,y,'o')
plt.plot(x,regr.predict(x),color = 'red')
plt.show()
plot_data(line_sample)我们得到结果:
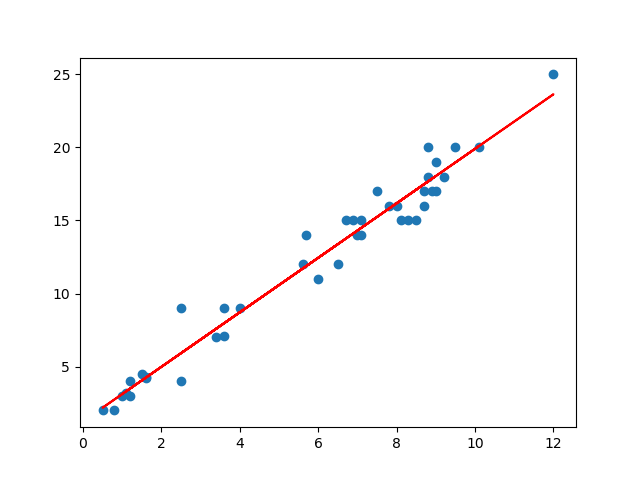
上述红线就是我们所拟合的直线,下面介绍多元回归。
2.多元线性回归
多元线性回归直白来说就是有多个影响因子,比如产品销售额不仅受广告投入的影响还和天气因素有关,每增加一个影响因素就多增加一个维度。多元线性回归的数学方程是 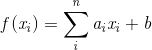
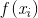
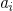
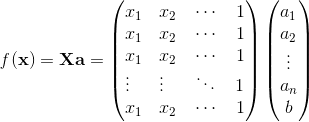
我们把样本也表示成向量形式 

令 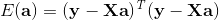
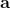

令上式为零可得 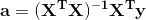
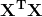
在实际任务中 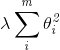
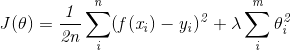

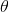
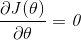

正规化为我们解决了矩阵不可逆的问题,具体的说只要正则参数是严格大于零,事实上我们也能证明
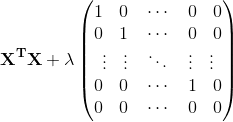
这个矩阵是可逆的。
熟悉的人会发现上面的正则化项就是L2正则化,也可以说是惩罚项,运用方法就是Ridge回归,实际运用中用于改善和减少过度拟合的问题,当然这个方法为什么要这样做的,公式本身也回答不了,按照自己的习惯默认1+1=2一样,千万不要去纠结,有兴趣的可以学习类似方法lasso回归。很显然惩罚项对回归程是有影响的,当惩罚项很大时,回归方程就会偏离需要拟合的数据,当惩罚项很小趋于0时,加入这个项就没有意义,发生过拟合的问题,目前常用的判断方法是赤池信息准则(AIC)和贝叶斯信息准则(BIC)。
三、总结
以上就是线性回归相关介绍,当然线性回归相反的还有非线性回归,常用的非线性回归,比如对数回归等,都是为了拟合出一个函数描述实际情况的因果关系。方法是有了,然而应用到实际情况中总会发现一些问题,比如输出的结果只有0和1,样本特征已经达到1000,这就需要降维方法比如LDA线性判别分析,这些实际问题也是促使我们改进和研究算法的动力。
PS: 如果觉得本篇本章对您有所帮助,欢迎关注、评论、赞!如果要转发请注明作者和出处
参考文献:
[1]周志华《机器学习》第三章线性模型