https://arxiv.org/pdf/1701.08289.pdf
FDDB face detection benchmark evaluation
引言:
在物体检测上,R-CNN十分成功,跟随这个工作,我们提出一个新的脸部检测方法,扩展改进Faster R-CNN算法。我们的算法通过结合几个策略,包括特征连接,强负面挖掘(hard negative mining)和多尺度训练等来改进。
最终达到state-of-the-art 的表现
方法:
包含两个部分:RPN(Region Proposal Network)为了生成RoIs(同Faster R-CNN);和一个fast RCNN 网络来区分RoIs是物体(或背景),并调整这些区域的边界。 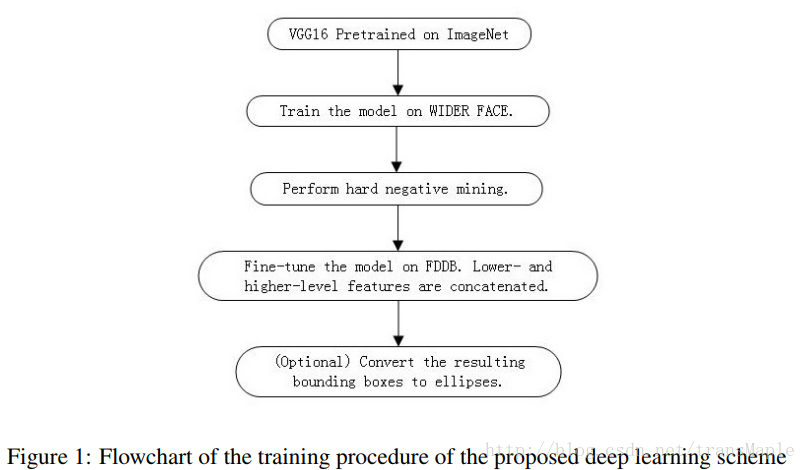
首先我们用WIDER FACE训练模型,并生成hard negatives。然后第二步把这些hard negatives送入训练,然后用FDDB数据集调优。最后我们应用多尺度训练和特征连接策略(feature concatenation strategy)。最后一个额外步骤,我们将检测的边界框转换为椭圆。
下面我们详细讨论这几个关键步骤
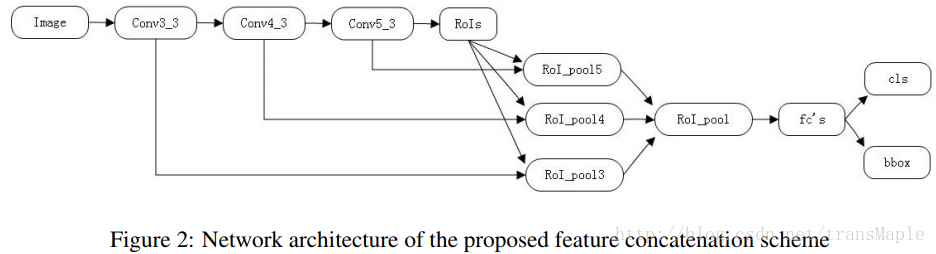
特征连接(feature concatenation)
传统RoI pooling是在最后一个特征图上提取RoI。这种方法不总是最优且可能遗漏一些重要特征,因为深层卷积层的特征输出有更广的接受域,导致成为更特征粗糙。我们为了捕获更好的RoI的细节,我们结合了多聚集层的特征图,包括低层与高层。我们合并了多个卷积层的池化结果来生成最后的池化特征。特别的,低层的卷积层都是经过ROI池化和L2正则化。然后合并,缩放,然后用1x1卷积来匹配最后的channels。结构如图:
Hard Negative Mining
将未能正确分类的样本标记为困难样本,再一次送入模型中。我们把实际值上的IoU小于 0.50.5 的区域视为负样本。(its itersection over union (IoU) over the ground truth region was less than 0.5), 在Hard Negative Mining 中, 我们把这些hard negative困难负样本添加到RoIs中来微调模型,并把前景和后景的比率调到1:3左右,和我们在第一步里的比率相同。
多尺度训练
输入多尺度图片训练,经验主义说明多尺度训练让模型更有鲁棒性,提高了在测试集上的表现。
实验部分,我自己翻译的关键内容:
We conduct an empirical study of evaluating the proposed face detection solution on the well-known
FDDB benchmark testbed [12], which has a total of 5,171 faces in 2,845 images, including various
detection challenges, such as occlusions, difficult poses, and low resolution and out-of-focus faces.
(FDDB:检测挑战:遮挡、不同的姿态、低分辨率、离焦人脸(应该是模糊))
For implementation, we adopt the Caffe framework [31] to train our deep learning models.(采用caffe框架) VGG16
was selected to be our backbone CNN network, which had been pre-trained on ImageNet. (采用VGG16作为基本框架,
并且已经在imagenet预训练过)
Forthe first step, WIDER FACE training and validation datasets were selected as our training dataset.
(首先选择WIDER FACE作为训练集和验证集)
We gave each ground-truth annotation a difficulty value, according to the standard listed in Table
1. Specifically, all faces were initialized with zero difficulty. If a face was satisfied with a certain
condition listed in Table 1, we add the corresponding difficulty value. We ignored those annotations
whose difficulty values greater than 2. Further, all the images with more than 1000 annotations were
also discarded.(初始困难度为0,然后按照表1标注困难度,超过2的标注直接丢掉)
《训练》
(迭代次数:110000,学习率:0.0001)
The pre-trained VGG16 model was trained on this aforementioned dataset for 110,000 iterations
with the learning rate set to 0.0001.
(重现调节尺寸,短边为600, 长边的上限为1000,水平翻转来增强数据)
During this training process, images were first re-scaled while always keeping the original aspect ratio.
The shorter side was re-scaled to be 600, and the longerside was capped at 1000.
Horizontal flipping was adopted as a data augmentation strategy.
(RPN:12 anchor)
During the training, 12 anchors were used for the RPN part, which covers a total size of 64× 64, 128× 128,
256 × 256, 512 × 512, and three aspect ratios including 1:1, 1:2, and 2:1.
After the non-maximum suppression (NMS), 2000 region proposals were kept.
(对于分类阶段,IOU大于0.5为前景,其余为背景;前景和背景的比例为1:3)
For the Fast RCNN classification part, an RoI is treated as foreground if its IoU with
any ground truth is greater than 0.5, and background otherwise.
To balance the numbers of foregrounds and backgrounds, those RoIs were sampled to
maintain a ratio of 1:3 between foreground and background.
《第二步》
For the second step, the aforementioned dataset was fed into the network.
Those output regions,whose confidence scores are above 0.8 while having IoU values with any
ground-truth annotation are less than 0.5, were regarded as the “hard negatives”.
(将wild faces喂入网络,输出的区域中,置信度得分大于0.8,同时IOU小于0.5的,作为”困难负样本“)
The hard negative mining procedure was then taken for 100,000 iterations using
a fixed learning rate of 0.0001, where those hard negatives were ensured to
be selected along with other sampled RoIs.
(最后困难负样本和其余样本roi训练训练,100000次,固定学习率为0.0001)
(最后结果模型在FDDB上进行微调,作为本文的最终模型)
Finally, the resulting model was further fine-tuned on the FDDB dataset to yield our final detection model.
To examine the detection performance of our face detection model on the FDDB benchmark, we
conducted a set of 10-fold cross-validation experiments by following the similar settings in [12].
For each image, in addition to performing the horizontal flipping, we also randomly resize it before
feeding it into the network. Specifically, we resize each image such that its shorter side will be one
of 480; 600; 750. Similar to the policy taken in the first step, we ensure that the longer side would
not exceed 1250.
During the training process, we apply the feature concatenation strategy as introduced in the previous
section. Specifically, we concatenated the features pooled from conv3 3, conv4 3, and conv5 3
layers. As illustrated in [11], the scale used after the features being concatenated could be either
refined or fixed. Here we used a fixed scale of 4700 for the entire blob, both in the training and test
phases. We fine-tuned the model for 40,000 iterations using a fixed learning rate of 0.001 to obtain
our final models.
During the test phase, a query image was first re-scaled by following the same principle as in the first
stage. For each image, a total of 100 region proposals were generated by the RPN network during
the region proposal generation step. A selected region proposal would be regarded as a face if the
classification confidence score is greater than 0.8. In our approach, the NMS threshold was set to
0.3. For the analysis purposes, we also output all the region proposals whose confidence scores are
greater than 0.001 in our experiments.