
It is very hard to have a fair comparison among different object detectors. There is no straight answer on which model is the best. For real-life applications, we make choices to balance accuracy and speed. Besides the detector types, we need to aware of other choices that impact the performance:
- Feature extractors (VGG16, ResNet, Inception, MobileNet).
- Output strides for the extractor.
- Input image resolutions.
- Matching strategy and IoU threshold (exclude some predictions in calculating loss).
- Non-max suppression IoU threshold.
- Positive anchor vs negative anchor ratio (hard negative mining ratio).
- The number of proposals or predictions.
- Box encoding.
- Data augmentation.
- Training dataset.
- Use of multi-scale and cropping images in training.
- Which convolution feature map layer(s) for object detections.
- Location loss function.
- Deep learning software platform used.
- Training configurations include batch size, input image resize, learning rate, learning rate decay.
Worst, the technology evolves so fast that any comparison becomes obsolete quickly. Here, we try to present results from individual papers and a research survey from Google Research. By presenting multiple viewpoints, we should get a better picture easier.
Faster R-CNN (Source)
This is the results of PASCAL VOC 2007 test set. We are interested in the last 3 rows representing the Faster R-CNN performance. The second column represents the number of RoIs made by the region proposal network. The third column represents the training dataset used. The fourth column is the mean average precision (mAP) in measuring accuracy.
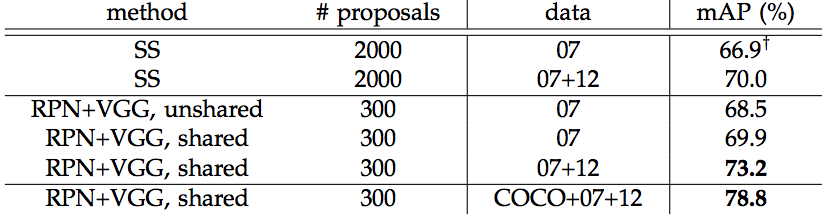 Detection results on PASCAL VOC 2012 test set for Faster R-CNN. SS (selective search).
Detection results on PASCAL VOC 2012 test set for Faster R-CNN. SS (selective search).
Results on PASCAL VOC 2012 test set.
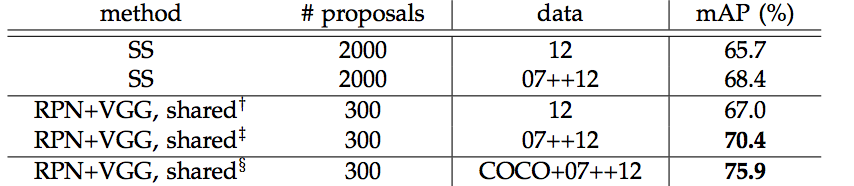 Detection results on PASCAL VOC 2012 test set for Faster R-CNN.
Detection results on PASCAL VOC 2012 test set for Faster R-CNN.
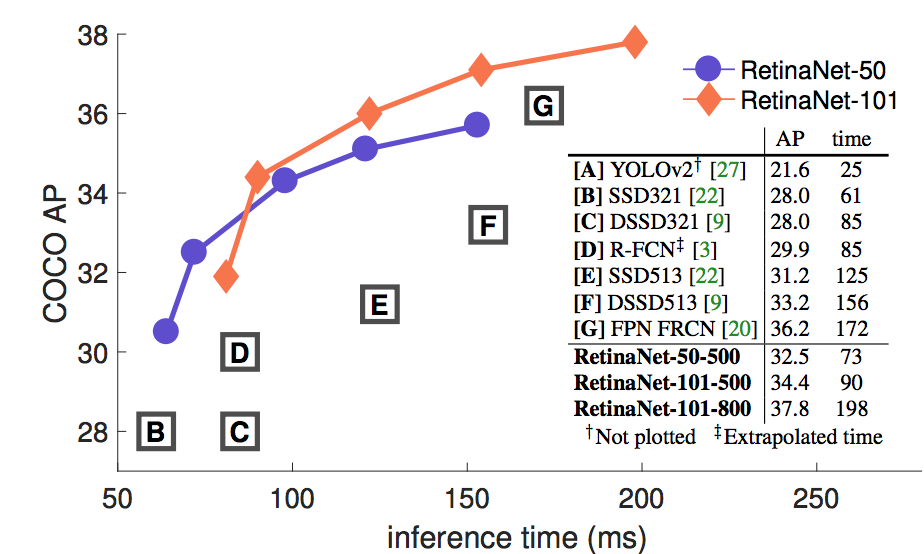
Results on MS COCO.

Timing on a K40 GPU in millisecond with PASCAL VOC 2007 test set.

R-FCN (Source)
Results on PASCAL VOC 2007 test set.
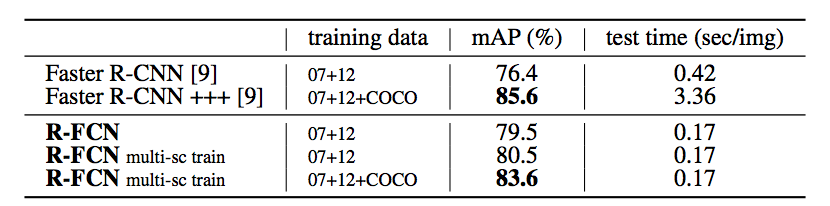
Results on PASCAL VOC 2012 test set.
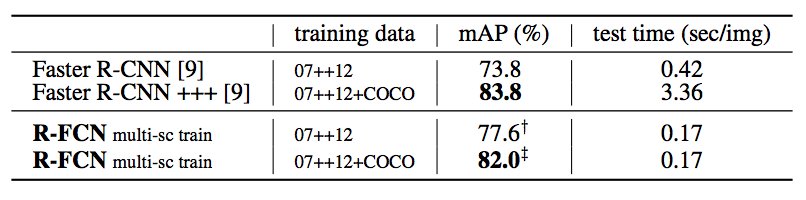
Results on MS COCO.

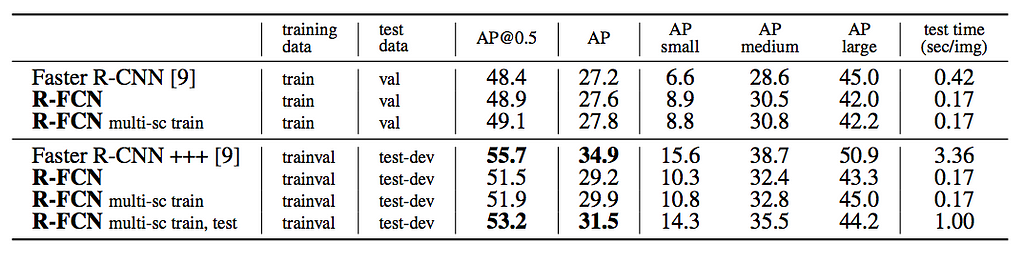
SSD (Source)
This is the results of PASCAL VOC 2007, 2012 and COCO. SSD300* and SSD512* applies data augmentation for small objects to improve mAP.
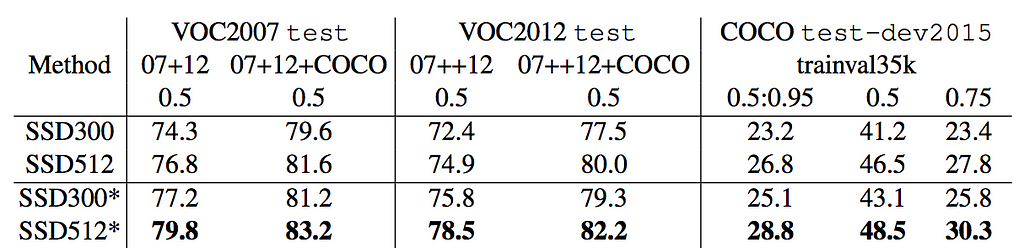
Performance:
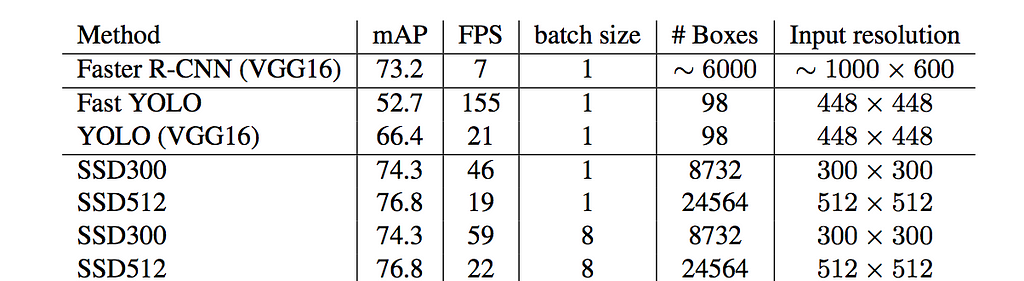 Speed is measure with a batch size of 1 or 8 during inference.
Speed is measure with a batch size of 1 or 8 during inference.
(Note: YOLO here refers to v1 which is slower than YOLOv2)
YOLO (Source)
Results on PASCAL VOC 2007 test set.
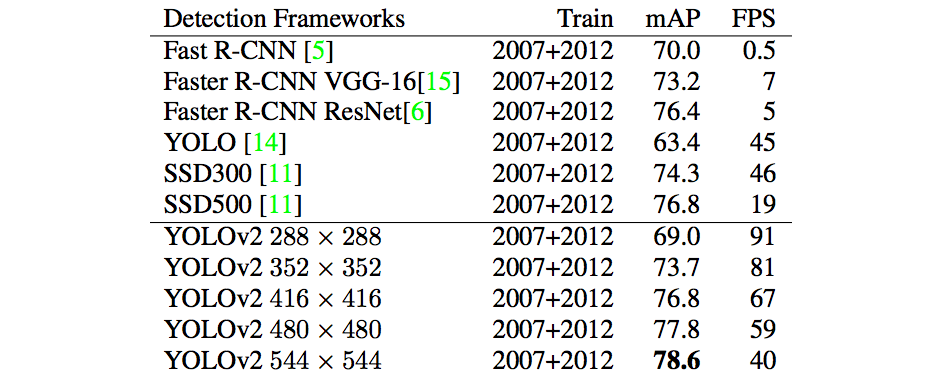
Results on PASCAL VOC 2012 test set.

(Note, results on other resolutions are missing for VOC 2012 testing set.)
Results on MS COCO.
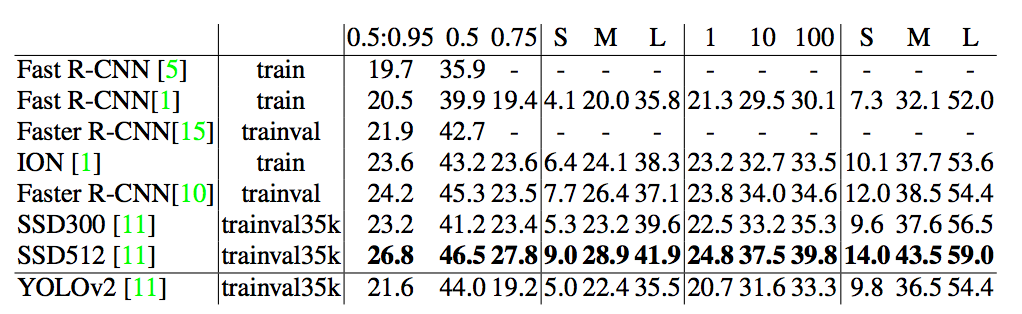
RetinaNet (Source)
Speed (ms) versus accuracy (AP) on COCO test-dev. Enabled by the focal loss, our simple one-stage RetinaNet detector outperforms all previous one-stage and two-stage detectors, including the best reported Faster R-CNN [28] system from [20]. We show variants of RetinaNet with ResNet-50-FPN (blue circles) and ResNet-101-FPN (orange diamonds) at five scales (400–800 pixels). Ignoring the low-accuracy regime (AP<25), RetinaNet forms an upper envelope of all current detectors, and an improved variant (not shown) achieves 40.8 AP.
R-FCN
R-FCN applies position-sensitive score maps to speed up processing while achieving similar accuracy as Faster R-CNN.
 Source
Source
FPN
FPN applies a pyramid of feature maps to improve accuracy. Here is the accuracy comparison with the Faster R-CNN.
 Source
Source
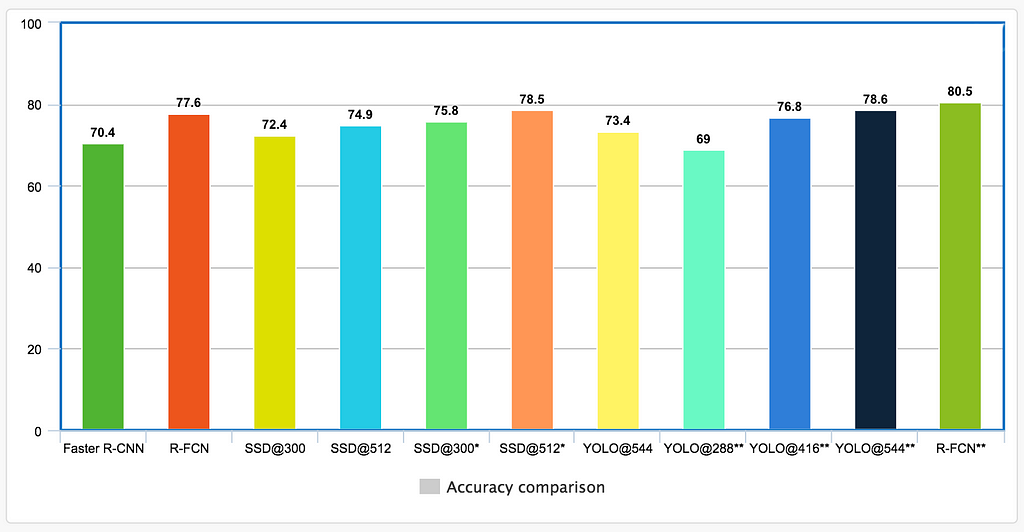
Comparing paper results
It is unwise to compare results side-by-side from different papers. Those experiments are done in different settings which are not purposed for apple-to-apple comparisons. Nevertheless, we decide to plot them together so you can get a rough picture. But you are warned that we should never compare those numbers directly.
The model is trained with both PASCAL VOC 2007 and 2012 data. The mAP is measured with the PASCAL VOC 2012 testing set. For SSD, the chart shows results for 300 × 300 and 512 × 512 input images. For YOLO, it has results for 288 × 288, 416 ×461 and 544 × 544 images. Higher resolution images for the same model have better mAP but slower to process.
“*” denotes small object data augmentation is applied to improve mAP.
“**” indicates the results are from VOC 2007 testing set. YOLO paper misses many VOC 2012 results so we decided to complement the chart with their VOC 2007 results. Since VOC 2007 results are in general better than 2012 results, we add the R-FCN VOC 2007 result as a reference.
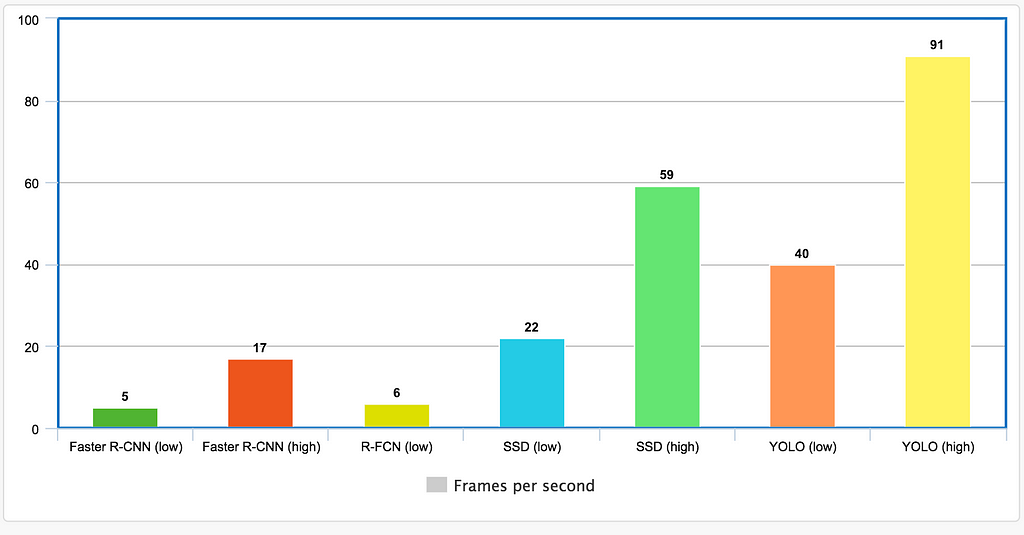
Many single shot detectors offer options including input image resolutions to improve the speed at the cost of accuracy. Nevertheless, cross reference those tradeoffs using their papers is difficult. Instead, we plot some of the achieved high and low frames per second below. It helps to understand the range of speed each offers.
Take away so far
Single shot detectors have a pretty impressive frame per seconds (FPS) with lower resolution images at the cost of accuracy. Those papers try to prove they can beat the region based detectors’ accuracy. However, that is less conclusive since higher resolution images and training techniques are applied in those claims. In addition, both camps are actually getting closer to each other in terms of both performance and design. But with some reservation, we may consider:
- Faster R-CNN and R-FCN demonstrate some small accuracy advantage if real-time speed is not needed.
- Single shot detectors are here for real-time processing. But applications need to verify whether it meets their accuracy requirement.
Report by Google Research (Source)
Google Research offers a survey paper to study the tradeoff between speed and accuracy for Faster R-CNN, R-FCN, and SSD. (YOLO is not covered by the paper.) It re-implements those models in TensorFLow using COCO dataset for training. It establishes a more controlled study and makes tradeoff comparison much easier. It also introduces MobileNet which achieves high accuracy with much lower complexity.
Speed v.s. accuracy
The most important question is not which detector is the best. The real question is which detector and what configurations give us the best balance of speed and accuracy each application needed. Below is the comparison of accuracy v.s. speed tradeoff (time measured in millisecond).
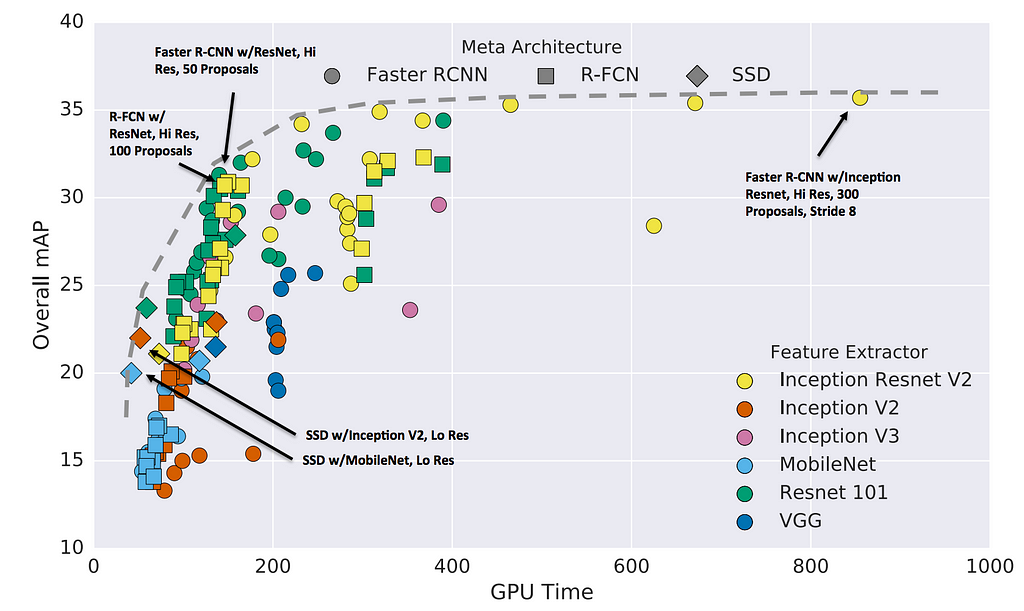
In general, Faster R-CNN is more accurate while R-FCN and SSD are faster. Faster R-CNN using Inception Resnet with 300 proposals gives the highest accuracy at 1 FPS. SSD on MobileNet has the highest mAP within the fastest models. This graph also helps us to locate some sweet spots with a good return in speed and cost tradeoff. R-FCN models using Residual Network strikes a good balance between accuracy and speed while Faster R-CNN with Resnet can attain similar performance if we restrict the number of proposals to 50.

Feature extractor
The paper studies how the accuracy of the feature extractor impacts (top 1% accuracy on classification) on the detector accuracy. Both Faster R-CNN and R-FCN can take advantage of a better feature extractor, but it is less significant with SSD.

Object size
For large objects, SSD performs pretty well even with a simpler extractor. SSD can even match other detector accuracies with better extractor. But SSD performs much worse on small objects comparing to other methods.
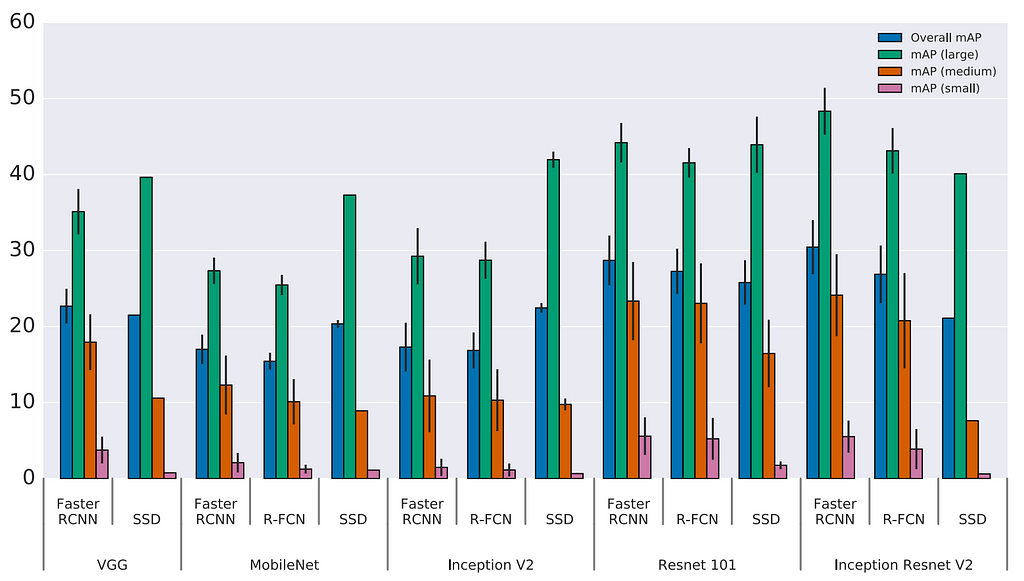
For example, SSD has problems in detecting the bottles while other methods can.

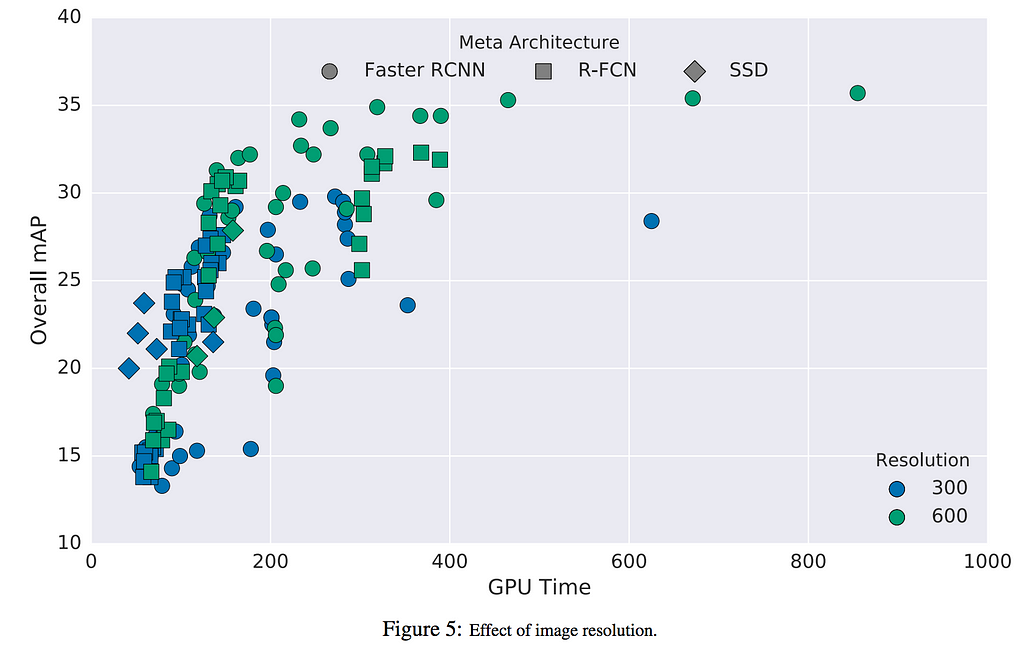
Input image resolution
Higher resolution improves object detection for small objects significantly while also helping large objects. When decreasing resolution by a factor of two in both dimensions, accuracy is lowered by 15.88% on average but the inference time is also reduced by a factor of 27.4% on average.
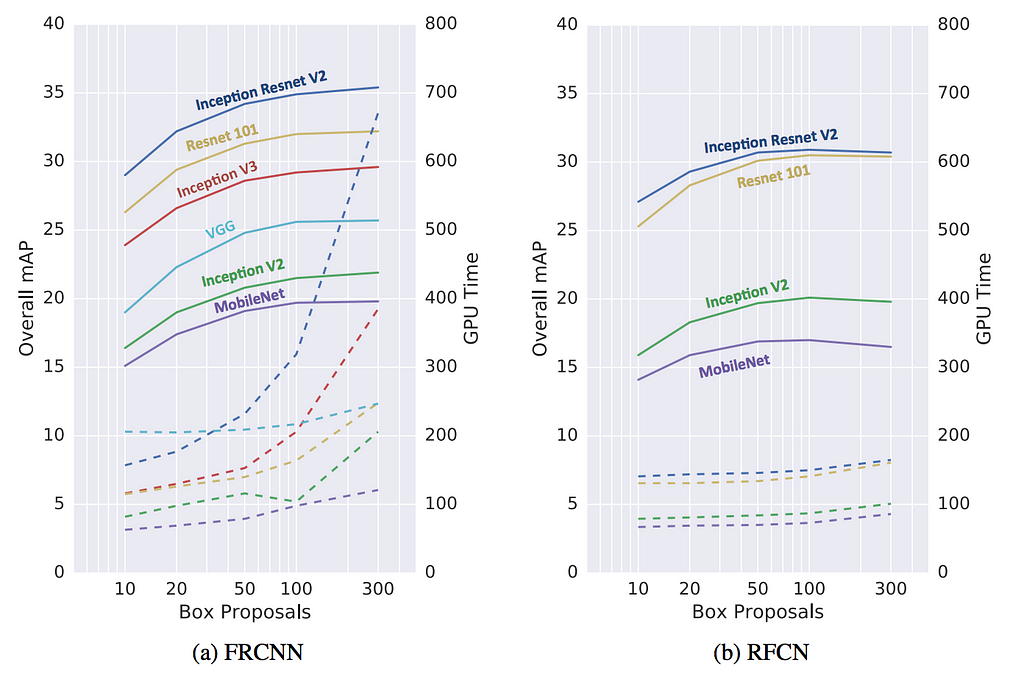
Number of proposals
The number of proposals generated can impact Faster R-CNN (FRCNN) significantly without a major decrease in accuracy. For example, for Inception Resnet, Faster R-CNN can improve the speed 3x when using 50 proposals instead of 300. The drop in accuracy is just 4% only. Because R-FCN has much less work per ROI, the speed improvement is far less significant.
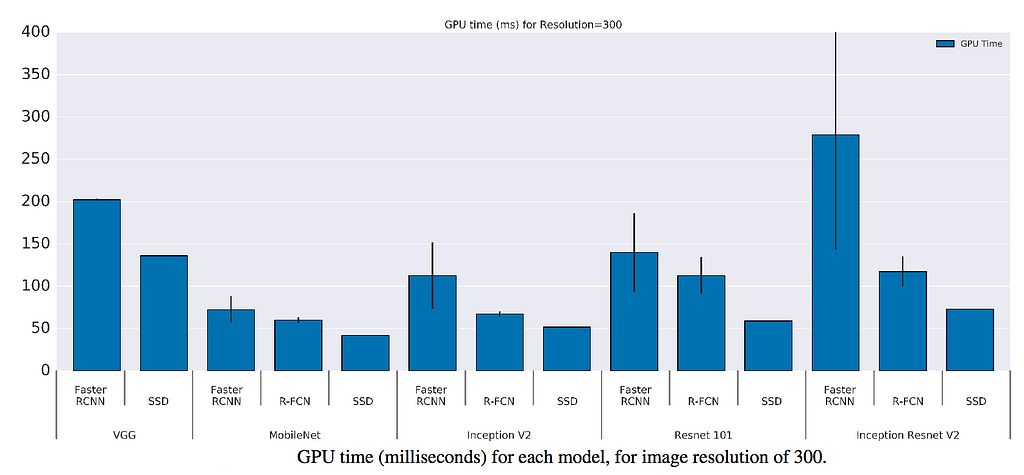
GPU time
Here is the GPU time for different model using different feature extractors.
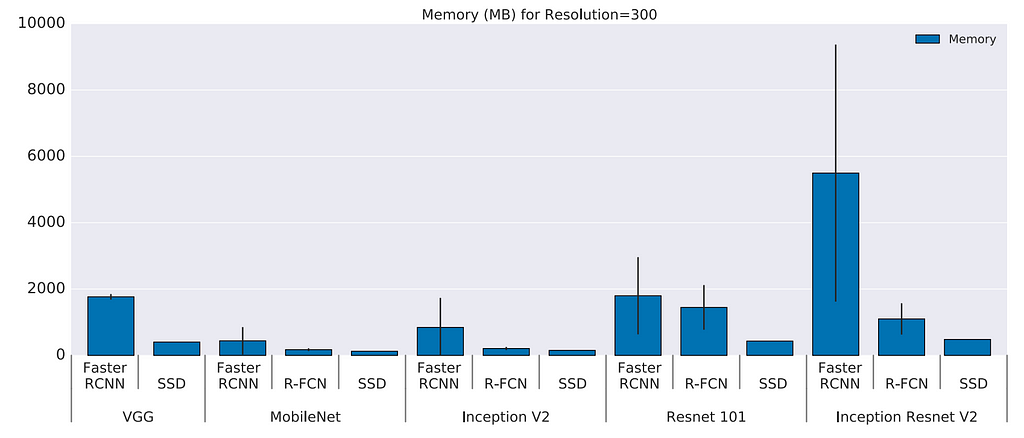
Memory
MobileNet has the smallest footprint. It requiring less than 1Gb (total) memory.
2016 COCO object detection challenge
The winning entry for the 2016 COCO object detection challenge is an ensemble of five Faster R-CNN models based on Resnet and Inception ResNet feature extractors. It achieves 41.3% mAP@[.5, .95] on the COCO test set and nearly 60% on small object recall over the previous best result.
 Source
Source
Lessons learned
Some key findings from the Google Research paper:
- R-FCN and SSD models are faster on average but cannot beat the Faster R-CNN in accuracy if speed is not a concern.
- Faster R-CNN requires at least 100 ms per image.
- Use only low-resolution feature maps for detections hurts accuracy badly.
- Input image resolution impacts accuracy significantly. Reduce image size by half in width and height lowers accuracy by 15.88% on average but also reduces inference time by 27.4% on average.
- Choice of feature extractors impacts detection accuracy for Faster R-CNN and R-FCN but less reliant for SSD.
- Post processing includes non-max suppression (which only run on CPU) takes up the bulk of the running time for the fastest models at about 40 ms which caps speed to 25 FPS.
- If mAP is calculated with one single IoU only, use mAP@IoU=0.75.
- With an Inception ResNet network as a feature extractor, the use of stride 8 instead of 16 improves the mAP by a factor of 5%, but increased running time by a factor of 63%.
Most accurate
- The most accurate single model use Faster R-CNN using Inception ResNet with 300 proposals. It runs at 1 second per image.
- The most accurate model is an ensemble model with multi-crop inference. It achieves state-of-the-art detection on 2016 COCO challenge in accuracy. It uses the vector of average precision to select five most different models.
Fastest
- SSD with MobileNet provides the best accuracy tradeoff within the fastest detectors.
- SSD is fast but performs worse for small objects comparing with others.
- For large objects, SSD can outperform Faster R-CNN and R-FCN in accuracy with lighter and faster extractors.
Good balance between accuracy and speed
- Faster R-CNN can match the speed of R-FCN and SSD at 32mAP if we reduce the number of proposal to 50.