翻译仅为学习,如有侵权请联系我删除
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
摘要行人检测被认为是特定课题,而不是一般的物体检测。虽然最近的深度学习对象检测器,如Fast/Faster R-CNN[1,2]在一般目标检测方面表现出了优异的性能,但它们在检测行人方面的成功率有限,而以往的主要行人检测器通常采用手工构造特征和深度卷积特征相结合的混合方法。在本文中,我们研究了Faster R-CNN[2]的行人检测问题。我们发现Faster R-cnn中的区域提议网络(Rpn)作为一个独立的行人检测器确实表现良好,但令人惊讶的是,下游分类器降低了结果。我们认为可能是如下两个原因导致的:(一)处理小实例的特征图分辨率不足;(二)缺乏挖掘硬负面实例的自举策略。在这些观测的驱动下,我们提出了一个非常简单但有效的行人检测基线,在共享的、高分辨率的卷积特征图上使用RPN,后接boosted forests。我们在几个基准(Cal-tech、INRIA、ETH和Kitti)上对该方法进行了综合评价,显示出了竞争的准确性和良好的速度。代码将公开。
1、简介
行人检测作为自动驾驶、智能监控等实际应用中的一个重要组成部分,已经引起了人们的广泛关注。尽管计算机视觉中的深入学习特性取得了普遍的成功,但目前领先的行人检测器(例如,[3,4,5,6])通常是将传统手工制作的特征[7,8]和深卷积特征[9,10]结合在一起的混合方法。例如,在[3]中,采用一个独立的行人检测器11作为高度选择性的提议者(每幅图像<3个区域),然后采用R-CNN[12]进行分类。手工制作的特征似乎对最先进的行人检测至关重要。
图1、Fast/Faster R-CNN在行人检测中的两个挑战。(A)小型对象可能无法在低分辨率特征图上实现ROI池化。(B)在Fast/Faster R-CNN中没有得到认真注意的严重的负面例子。

另一方面,Faster R-CNN[2]是一种特别成功的一般目标检测方法。它由两个部分组成:一个完全卷积区域提案网络(RPN),用于提出候选区域,然后是一个下游Fast R-CNN[1]分类器。因此,Faster R-cnn系统是一种纯粹基于cnn的方法,无需使用手工制作的特征(例如,基于低级特征的选择性搜索[13])。尽管它的精确性领先于几个多类别的基准,Faster R-cnn并没有在流行的行人检测数据集(例如Caltech集[14])上呈现出有竞争力的结果。
在本文中,我们研究了Faster R-CNN作为行人检测器的问题。有趣的是,我们发现一个专门为行人检测量身定做的RPN作为一个独立的行人检测器取得了有竞争力的结果。但令人惊讶的是,在将这些提议输入Fast R-CNN分类器后,准确性就降低了。我们认为,这种不令人满意的表现有以下两个原因。
首先,Fast R-CNN分类器的卷积特征图对于小目标的检测具有较低的分辨率。典型的行人检测场景,如自动驾驶和智能监控,通常会出现小规模的行人实例(例如,28×70[14])。在小物体上(图1(A),感兴趣区域(ROI)池层[15,1]在低分辨率特征映射(通常有16像素的步幅)上执行,可以导致折叠箱造成的“平坦”特征。这些特征不区分小区域,从而降低了下游分类器的等级。我们注意到,这与手工制作的具有更好的分辨率的特征形成了鲜明对比。我们通过池化较浅但分辨率较高的层的特征,以及通过增加特征图大小的孔算法(即“àtrous”[16]或Filter稀薄[17])来解决这个问题。
图2、我们的模型。RPN用于计算候选边界框、分数和卷积特征映射。候选框被输入级联增强森林(BF)进行分类,使用从RPN计算的卷积特征图中汇集的特征。
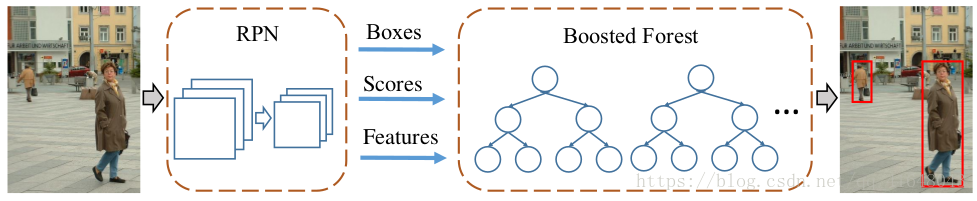
其次,在行人检测中,错误预测主要是由硬背景实例的混淆引起的(图1(B)。这与一般的对象检测形成了鲜明的对比,在这种情况下,混淆的主要来源来自多个类别。为了解决硬负例,我们采用级联增强森林(BF)[18,19]进行有效的硬负挖掘(Bootstrating)和样本重加权,对RPN提出的候选区域进行分类。与以前使用手工制作的特征来训练森林不同的是,在我们的方法中,BF重用了RPN的深度卷积特征。该策略不仅通过共享特征降低了分类器的计算量,而且利用了深入学习的特征。
因此,我们提出了一个令人惊讶的简单但有效的基线,用于基于RPN和BF的行人检测。我们的方法克服了Faster R-CNN用于行人检测的两个限制,并摆脱了传统手工制作的特征。我们在一些基准上给出了令人信服的结果,包括Caltech[14]、INRIA[20]、ETH[21]和Kitti[22]。值得注意的是,我们的方法在评估交并比(IOU)阈值0.7的情况下,定位精度有了很大的提高,在Caltech数据集上相对提高了40%。同时,该方法的测试时间速度为每幅图像0.5秒,与以往的方法相比具有很强的竞争力。
此外,本文还揭示了传统的行人检测器至少有两个原因被继承在最近的方法中。首先,手工制作的高分辨率特征(如[7,8])及其金字塔有利于探测小物体。其次,对硬负例的挖掘进行了有效的引导。然而,如果在深度学习系统中适当地处理这些关键因素,就会产生优异的效果。
2、相关工作
积分通道特征(ICF)检测器[7]扩展了Viola-Jones框架[23],是最流行的无深度学习特征的行人检测器之一。ICF检测器包括信道特征金字塔和增强分类器。ICF的特征表示方法已经通过多种方法提升了,有ACF[8]、LDCF[24]、SCF[11]等,但Booding算法仍然是行人检测的关键组成部分。
在一般目标探测的(“慢”)R-cnn[12]的成功的推动下,最近的一系列方法[11,4,5]采用两级管道进行行人检测。在[3]中,SCF行人检测器[11]用于提出区域,随后使用R-CNN进行分类;TA-CNN[4]使用ACF检测器[8]生成建议,并训练R-CNN风格的网络来联合优化具有语义任务的行人检测;DeepParts方法[5]使用LDCF检测器[24]生成建议,并通过神经网络学习一组互补部分。我们注意到,这些提议者是独立的行人探测器,由手工制作的特征和增强分类器组成。
与上述基于R-cnn的方法不同,CompACT方法[6]在混合手工和深卷积特征的基础上学习增强分类器。与我们的工作密切相关的是,CCF检测器[25]是在深度卷积特征金字塔上的增强分类器,但没有使用区域提案。我们的方法没有金字塔,比[25]更快、更精确。
3、方法
我们的方法包括两个组件(如图2所示):一个RPN生成候选框以及卷积特征映射,以及一个使用这些卷积特征对这些提议进行分类的增强森林。
3.1、行人检测的区域提议网络
Faster R-CNN[2]中的RPN是在多类目标检测场景中发展起来的一类不可知检测器。对于单类别检测,RPN自然是唯一相关类别的检测器。我们特别为行人检测量身订造RPN,如下所述。
我们采用单纵横比为0.41(宽与高)的锚(参考箱)[2]。如[14]所示,这是行人的平均高宽比。这与最初的RPN[2]不同,RPN[2]具有多个纵横比的锚。高宽比不适当的锚点与实例很少相关,因此噪声大,不利于检测精度。此外,我们使用9种不同尺度的锚,从40像素的高度开始,尺度步长为1.3×。这一范围比[2]范围更广。多尺度锚的使用省去了使用特征金字塔检测多尺度对象的要求。
在[2]之后,我们采用了在ImageNet数据集[26]上预先训练的VGG-16网[10]作为骨干网络。RPN建立在Conv 5_3层之上,然后是中间3×3卷积层和2个1×1卷积层,用于分类和边界框回归(详见[2])。通过这种方式,RPN可以通过16像素的步幅(Conv 5_3)来恢复方框。分类层提供了预测框的置信度分数,可用作后续增强森林梯级的初始分数。
值得注意的是,虽然我们将在下一节中使用“àtrous”[16]技巧来增加分辨率和减少步幅,但我们仍然使用相同的步幅为16像素的RPN。只有在提取特性时(如下一节介绍的那样),才能利用这个技巧,而不是用于微调。
3.2、特征提取
根据RPN提出的候选区域,我们采用ROI池[1]从区域中提取固定长度的特征。如下一节所介绍的那样,这些特性将被用来训练BF。与速度更快的R-cnn不同,后者需要将这些特征输入到原始的完全连接(FC)层,从而限制它们的维数,BF分类器不对特征的维数施加任何限制。例如,我们可以从Conv 3_3(步幅=4像素)和Conv 4_3(步长=8像素)上的Rois中提取特征。我们将特征集合成7×7的固定分辨率。由于BF分类器的灵活性,这些来自不同层的特征只是简单地连在一起而不进行归一化;相比之下,对于深度分类器,当归一化特征时,需要仔细地处理这些特征[27]。
值得注意的是,由于没有对特征尺寸施加任何限制,我们可以灵活地使用分辨率更高的特征。特别是,考虑到RPN中的微调层(Conv 3上的span=4,Conv 4上的8层,Conv 5上的16层),我们可以使用àtrous技巧[16]来计算分辨率更高的卷积特征映射。例如,我们可以将Pool 3的步长设为1,并将所有Conv 4滤波器扩展2,从而将Conv 4的步幅从8减小到4。与以前的方法[17,16]微调膨胀滤波器不同,在我们的方法中,我们只使用它们进行特征提取,而不对新的rpn进行微调。
虽然我们采用与Faster R-CNN[2]相同的ROI分辨率(7×7),这些ROI相比Fast R-CNN(Conv 5_3)是在更高分辨率的特征图(例如,Conv 3_3,Conv 4_3,或Conv 4_3àtrous)。如果ROI的输入分辨率小于输出(<7×7),则池箱崩溃,特征变得“平坦”而不具有区分性。这个问题在我们的方法中得到了缓解,因为在我们的下游分类器中使用Conv 5_3的特性是不受限制的。
3.3 Boosted Forest
RPN生成了区域提案、信心分数和特征,所有这些都用于训练级联增强森林分类器。我们采用RealBoost算法[18],主要跟踪[6]中的超参数。形式上,我们引导训练6次,每个阶段的森林都有{64,128,256,512,1024,1536}树。最初,培训集由所有正面示例(Caltech集上的∼50k)和相同数量的从提案中随机抽样的负示例组成。在每个阶段之后,挖掘额外的硬负示例(其数量为阳性数的10%,∼5k on Caltech),并将其添加到培训集中。最后,一个拥有2048棵树的森林在经过所有的自举阶段后都得到了训练。最后一个林分类器用于推理。我们的实现是以[28]为基础的。
我们注意到,没有必要平等地处理最初的建议,因为我们的建议有RPN计算的初步信任分数。换句话说,rpn可以看作是stage-0的分类器f0,我们按照RealBoost形式设置f0=0.5*log(s/(1-s)),其中s是建议区域的分数(f0是标准boosting的常数)。其他阶段与标准RealBoost相同。
3.4 实现细节
我们采用[15,1,2]中的单尺度训练和测试,而不使用特征金字塔。对图像进行调整,使其较短的边缘具有N个像素(Caltech为N=720像素,INRIA为600像素,ETH为810像素,Kitti为500像素)。对于RPN训练,如果锚与一个真值框的交并比(IOU)大于0.5那么锚就被认为是一个正的例子,否则它是负的。我们采用了以图像为中心的训练方案[1,2],每个小批由1个图像和120个随机抽样的锚组成,用于计算损失。在一个mini-batch中正样本与负样本的比例为1:5。RPN的其他超参数如[2]所示,我们采用[2]的公开代码对RPN进行微调。我们注意到,在[2]中,跨边界的锚在微调过程中被忽略,而在我们的实现中,我们在微调过程中保留了跨界负锚,这在经验上提高了这些数据集的准确性。
在微调RPN的情况下,我们采用阈值为0.7的非最大抑制(NMS)方法对建议区域进行滤波。然后将提案区域按分数进行排序。对于BF训练,我们通过选择每个图像的分数最高1000项提议(和真值框)来构建训练集。根据不同数据集的大小,将树深设为5,INRIA和ETH集为2,而INRIA和ETH集为2。在测试的时候,我们只使用图片中排名最高的100个提案,这是由BF分类的。
4、实验和分析
4.1、数据集
我们综合评价了4个基准:Caltech[14]、INRIA[20]、ETH[21]和Kitti[22]。默认情况下,用于确定这些数据集中的正例的IOU阈值为0.5。
在Caltech[14]上,训练数据在[3]之后增加了10倍(42782幅图像)。标准测试集中的4024幅图像用于在“合理”设置下对原始注释进行评估(行人至少有50像素高,至少65%可见)[14]。评价指标是[10−2,10 0]中对每幅图像的假阳性的对数平均漏报率(在[29]后面表示为MR−2,或者简称MR)。此外,我们还在[29]提供的新注释上测试我们的模型,这将纠正原始注释中的错误。这个集合被表示为“Caltech-New”。Caltech的评价指标是MR−2和MR−4,对应于[10−2,10 0]和[10−4,10 0]的FPPI对数平均漏报率[29]。
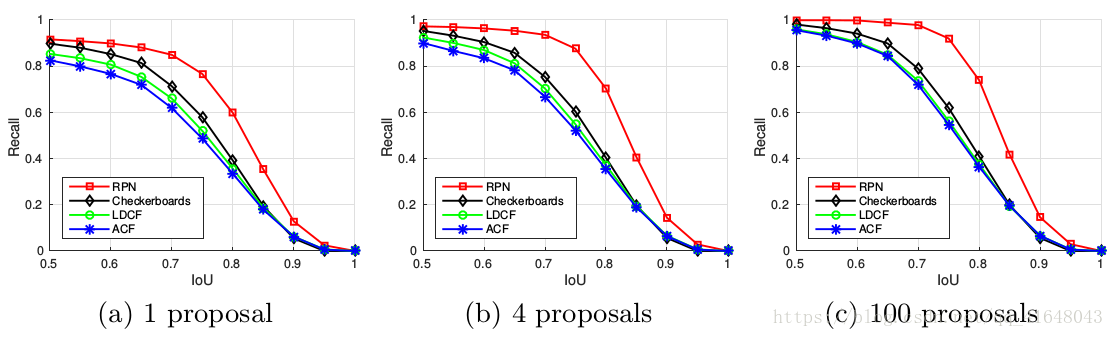
图3、比较RPN和现有的三种方法在Caltech数据集的提案质量(召回和IOU),平均每个图像1,4或100个提案被评估。
INRIA[20]和ETH[21]数据集常用于验证模型的泛化能力。按照[30]中的设置,我们的模型在INRIA培训集中对614幅正面图像和1218幅负片图像进行了培训。模型在INRIA中的288张测试图像上进行了评估,在ETH中的1804幅图像上进行了评估,由MR−2进行了评估。
Kitti数据集[22]由具有立体声数据的图像组成。我们对7481的左相机图像进行训练,并对标准的7518个测试图像进行评估。KITTI评估PASCAL-style平均精度(地图)在三个困难级别:“容易”,“中等”和“困难”1。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
后面的消融实验等实验数据对比感兴趣的可以自行查看相应论文。