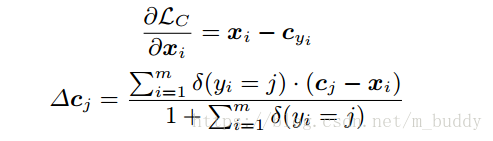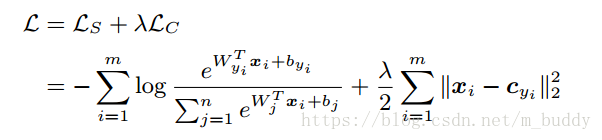1. 论文思想
在这篇文章中尉人脸识别提出了一种损失函数,叫做center loss,在网络中加入该损失函数之后可以使得网络学习每类特征的中心,惩罚每类的特征与中心之间的距离。并且该损失函数是可训练的,并且在CNN中容易优化。那么,将center loss与softmax相结合会增加CNN网络的鲁棒性。
在网络中增加center loss的损失函数的思想便是使得类间距变大,类内部间距变小,从而使得分类边界更加明了,类内部更加凝聚(方差减小)。那么这篇文章的主要工作就集中在:
(1)提出了新的损失函数center loss,通过实验证明CNN中加入softmax loss与center loss之后使得网络更加鲁棒。
(2)提出的损失函数在CNN网络中是很容易实现的,可以通过SGD直接进行训练的。
这里只关心了center loss对于其它人脸的部分就不仔细看了-_-||。。。
2. 实验尝试
这里论文使用MNIST数据集和包含两层全连接层的网络进行实验。试验中将第一个全连接层的输出设置为2,目的是为了方便进行可视化观测。对于一般的多分类模型都是采用softmax作为最后一层,那么梯度的源头便是softmax loss。那么对于softmax loss损失函数一般定义成为如下交叉熵的形式:(为啥是这样的形式?请参考:平方损失函数与交叉熵损失函数)
其中,
是特征第一个全连接层输出的特征向量,
是batch size的大小,
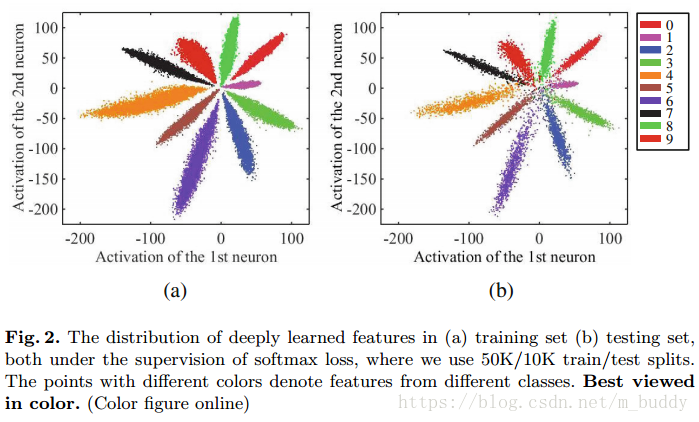
是softmax分类的数目。那么使用softmax loss的网络第一个全连接层的输出进行可视化得到的结果是
左边的是训练集的可视化结果,右边是测试集的可视化结果。可以看到softmax确实是可以将10个类分开,并且具有比较明显的边界信息。但是,每个类的类内方差比较大,类间距也比较小。这就导致了测试集中部分数据的混淆。
2.1 祭出Center Loss
在文章中将Center Loss定义为如下形式:
其中,
代表的是每个类聚类的中心,而且该值应该随着网络的变换而变化。在进行训练的时候为了使用batch更新,并且对一些异常的数据,使用
进行调和,该值在
之间。对于每个输入的特征向量
进行求导,聚类中心
的更新参照如下梯度,从而得到:
上式中的
是一个条件函数,在条件满足的时候是1,否则取值为0。那么接下来的事情就是怎么将两个loss结合起来了。文章中使用的是加权相加的形式,使用参数
去调和这两个loss了
那么这个算法的流程就可以描述为:
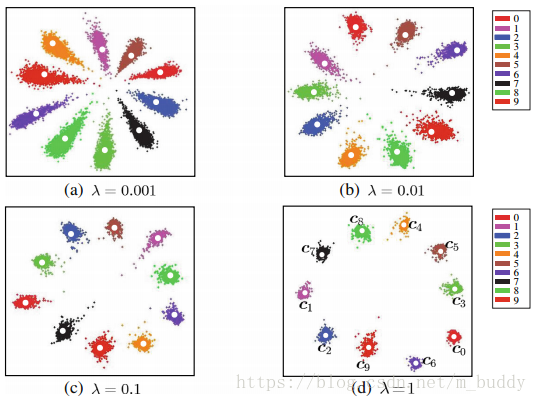
对于不同的参数
对最后结果的影响可以通过下图来进行说明:
可以看到参数
越大,center loss所占的权重越大,则数据就越向中心聚集。