1 图像分类和目标识别的区别
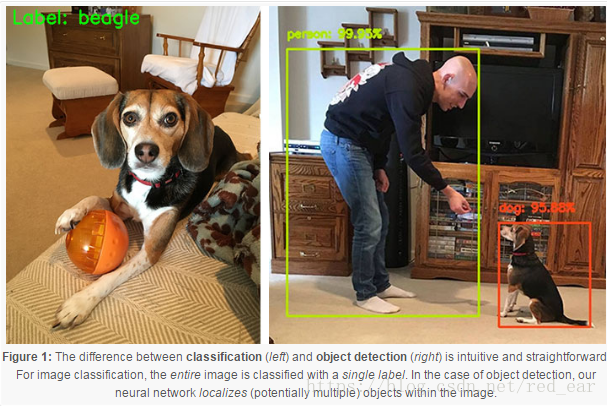
分类(左)和目标检测(右)之间的差异是直观和直接的。对于图像分类,将整个图像分类为单个标签。在对象检测的情况下,我们的神经网络定位图像中的(潜在多个)对象。
因此,我们可以认为图像分类为:
一个图像 一类标签(整幅图像)
对象检测:不管是否通过深度学习或其他计算机视觉技术来执行,都建立在图像分类上,并试图精确地定位图像中每个对象出现的位置。
当执行对象检测时,给定输入图像,我们希望获得:
1.一个包围盒的列表,或图像中每个对象的(x,y)坐标
2.与每个边界框关联的类标签
3.与每个边界框和类标签相关联的概率/置信分数
方法一:传统的目标检测流程
该方法不完全是端对端的深度学习目标检测
1.固定大小的滑动窗口,从左到右,从上到下滑动以定位不同位置的对象。
2.在不同尺度下检测物体的图像金字塔
3.基于预训练(分类)卷积神经网络的分类
在每一步的滑动窗口+图像金字塔,都需要提取ROI,将它输入到CNN,输出为ROI的分类。
如果标签L的分类概率高于某个阈值T,则将ROI的包围盒标记为标签(L)。每一个滑动窗口和图像金字塔都重复这个过程,我们得到输出对象检测器。最后,我们将非极大值抑制应用于产生最终输出检测的边界框:
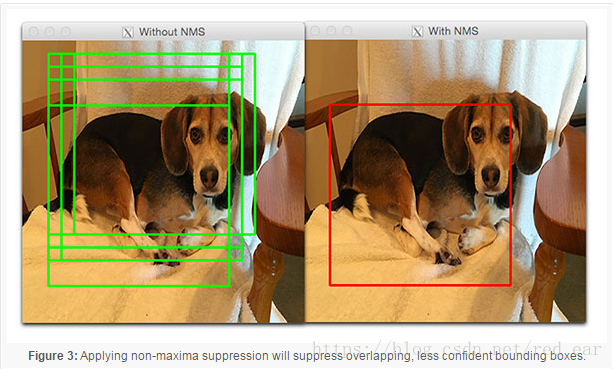
一般这样的方法慢且容易出错。然而,值得学习的是如何应用这种方法,因为它可以将任意的图像分类网络转换成对象检测器,避免了需要明确地训练端到端的深度学习对象检测器。
方法2:
对象检测框架的基本网络
深度学习对象检测的第二种方法在深度学习对象检测框架(faster-RCNN、SSD或YOLO)中处理预先训练的分类网络作为基础网络。
好处是可以创建一个完整的端到端的基于深度学习的对象检测器。
缺点是它需要对学习对象探测器的工作有多深的了解——我们将在下一节中对此进行更多的讨论。
深度学习对象检测器的组件
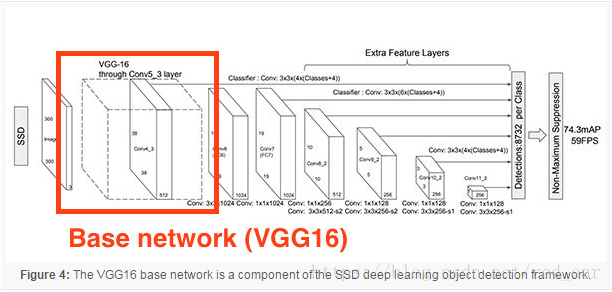
未完待续...