论文阅读:https://arxiv.org/abs/1506.01497
源码地址https://github.com/kevinjliang/tf-Faster-RCNN
前言
Fast-RCNN基本实现端对端(除了proposal阶段外),下一步自然就是要把proposal阶段也用CNN实现(放到GPU上)。这就出现了Faster-RCNN,一个完全end-to-end的CNN对象检测模型。经过R-CNN和Fast RCNN的积淀,Kaiming He大神和Rgb(Ross B. Girshick)大神强强联手在2016年提出了新的Faster R-CNN,在结构上,Faster RCNN已经将特征抽取(feature extraction),proposal提取,bounding box regression(rect refine),classification都整合在了一个网络中,使得综合性能有较大提高,在检测速度方面尤为明显。
Introduction
从RCNN到Fast R-CNN,再到本文的Faster R-CNN,目标检测的四个基本步骤(候选区域生成,特征提取,分类,位置精修)终于被统一到一个深度网络框架之内。剔除了大部分的计算冗余,大部分训练过程在GPU中完成,进一步提高了运行速度。
三个框架的示意图如下: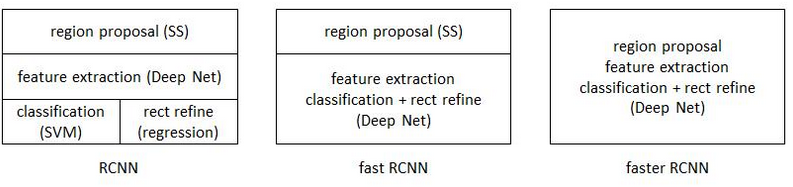
Faster R-CNN主要用两个模块组成:
- 第一个模块是深层的全卷积网络用于区域推荐
- 第二个模块是Fast R-CNN detector.
Faster R-CNN可以看做”区域生成网络+fast R-CNN”的系统,用区域生成网络代替Fast-RCNN中的Selective Search方法,来产生一堆候选区域。
亮点
Faster R-CNN可以看做“区域生成网络+Fast R-CNN“的系统,其中区域生成网络代替了Fast RCNN中的Selective Search方法。
Faster R-CNN解决了三个问题:
- 如何设计区域生成网络
- 如何训练区域生成网络
- 如何让区域生成网络和Fast R-CNN网络共享特征提取网络
侯选区域生成网络(RPN)
为什么要整出来侯选区域生成网络?
当前检测网络最耗时的地方在proposals选取。现在用的最多的时Selective Search,这在测试过程中会耗费较多的时间。
我们可以注意到,CNN在GPU上有着计算优势,有一个很直接的想法就是候选区域算法能从CPU上移植到GPU上,这是一个好的工程想法,但是这样的做法忽略了共享计算的可能.
论文提出了使用CNN来推荐候选区域,称之为RPNs(Region Proposal Networks)。作者观察到区域检测器(例如Fast R-CNN)的卷积层后的特征映射(feature map)可用户RPNs生成侯选区域.在特征映射的基础上向后添加几层卷积层构成区域推荐网络。这是一个FCN(fully convolutional network,全卷积网络).
先使用VGG等现有模型提取特征,然后使用一个小的网络在卷积最后得到的这个特征图上进行滑动扫描,这个滑动的网络每次与特征图上n*n 的窗口全连接,然后映射到一个低维向量,最后将这个低维向量送入到两个全连接层,对特征图上所有可能的候选框进行分类和回归。
侯选区域生成网络架构
RPN网络基本设想是:在提取好的特征图上,通过一个滑动窗口获取特征向量,然后输出到两个全连接层:
- 一个是box-regression layer(reg)
- 另一个是 box-classification layer(cls).
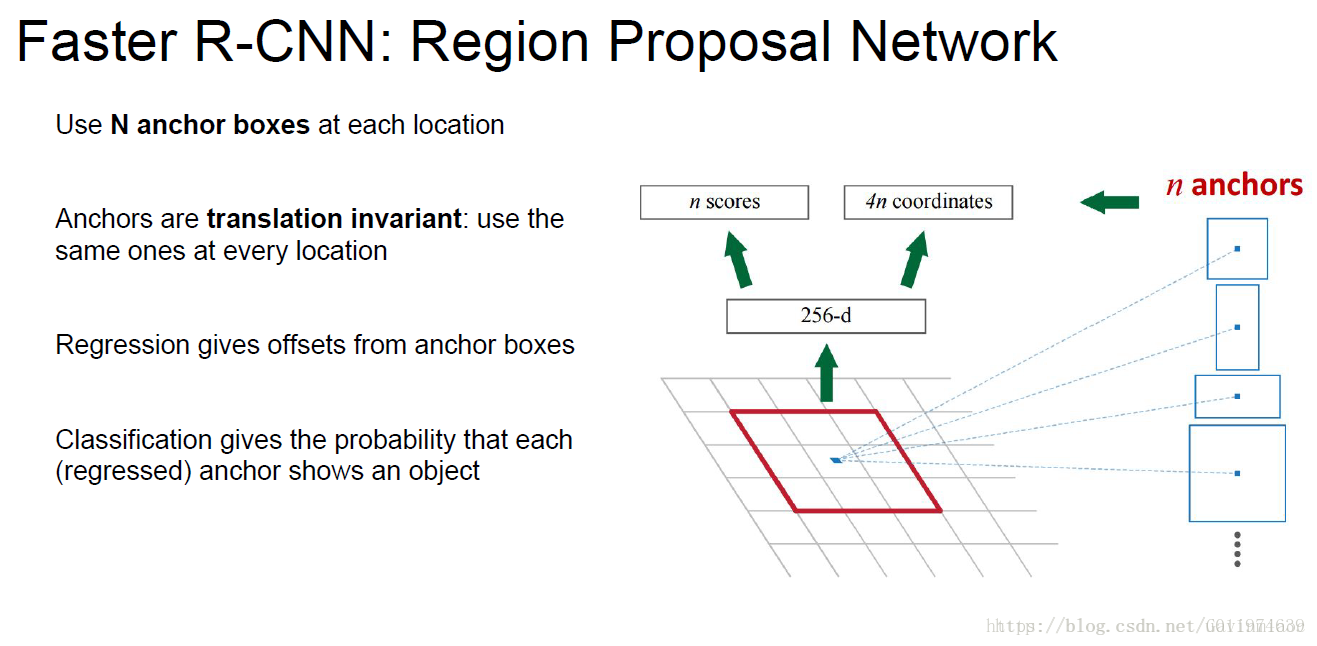
上图中可以看到,在feature map上会有一个sliding window,这个sliding window会遍历feature map上的每一个点,并且在每个点上配置k个anchor boxes。
这k个anchor boxes就是用于提取feature map上的特征,但是这样提取出来效果不是很好,所以后面会接一个分类器和一个bbox回归,这样就能修正检测位置了。

侯选区域生成网络(Region Proposal Networks,RPN),RPN网络接收任意大小的图片作为输入,输出一组目标侯选矩形框,并带有目标分数.
下面详细介绍一下anchor boxes的概念。
Anchors
在每一个滑动窗口的位置,我们同时预测k个推荐区域,故reg层有4k个输出(每个侯选区域是一个元素个数为4的元组)。cls层输出2k个得分(即对每个推荐区域是目标/非目标的估计概率)
k个推荐区域对应着k个参考框的参数形式,我们称之为anchors.每个anchor以当前滑动窗口的中心为中心,并与尺度和长宽比相关。默认地我们使用3种尺度和3种长宽比,对于每个滑动位置就有k=9个anchor。对于大小为W×HW×H(例如2,400)的卷积特征映射,总共有WHkWHk个anchor。
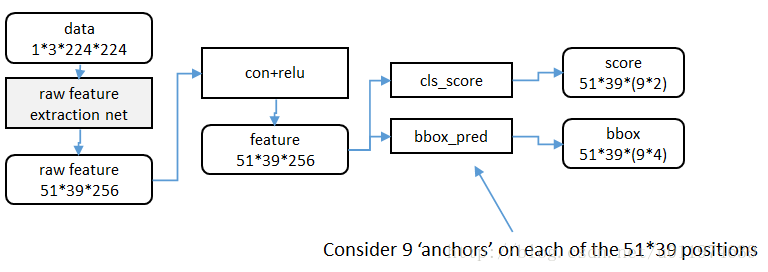
特征可以看做一个尺度51*39的256通道图像,对于该图像的每一个位置,考虑9个可能的候选窗口:三种面积{1282,2562,5122}×{1282,2562,5122}× 三种长宽比例{1:1,1:2,2:1}
{1:1,1:2,2:1}, 下图示出51*39个anchor中心,以及9种anchor示例。
下图示出51*39个anchor中心,以及9种anchor示例。
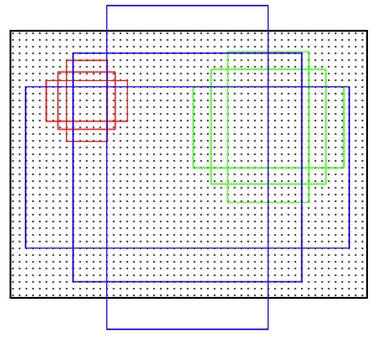
为方便举例,由VGG等现有模型提取的特征图,在这里我们将其看做尺度为51*39的256通道的图像,然后在这个特征图上进行滑窗操作。
在特征图上进行的滑窗操作,相当于映射回原图后,Sliding Window中心对应的原图上的中心,在不同尺寸和比例的anchor区域中进行特征提取(这个对应关系是在实现代码里事先确定好的);同时值得一提的是,作者实验指出,映射回原图的anchor比Sliding Window相应的感受野大一点也是可以的,因为有可能像人一样有预测边缘的能力。(感受野计算,见这里)
另一方面,Sliding Window的尺寸为3*3的滑窗操作可以看做3*3的卷积核与特征图进行卷积操作(也就是那“额外”的conv+relu层),那么这个3*3的区域卷积后可以获得一个256维的特征向量。
这个256维的向量提取的特征就对应着一个Sliding Window中心映射回原图后,9个anchor所在的区域。
当然我们知道,Sliding Window在不断滑动,所以还有很多这样的256维向量。
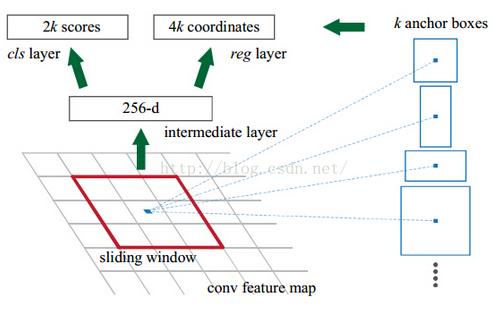
分类层(cls_score)输出每一个位置上,9个anchor属于前景和背景的概率;窗口回归层(bbox_pred)输出每一个位置上,9个anchor对应窗口应该平移缩放的参数。
对于每一个位置来说,分类层从256维特征中输出属于前景和背景的概率;窗口回归层从256维特征中输出4个平移缩放参数。
就局部来说,这两层是全连接网络;就全局来说,由于网络在所有位置(共51*39个)的参数相同,所以实际用尺寸为1×1的卷积网络实现。
窗口分类和位置精修
分类层(cls_score)输出每一个位置上,9个anchor属于前景和背景的概率;窗口回归层(bbox_pred)输出每一个位置上,9个anchor对应窗口应该平移缩放的参数。
对于每一个位置来说,分类层从256维特征中输出属于前景和背景的概率;窗口回归层从256维特征中输出4个平移缩放参数。
就局部来说,这两层是全连接网络;就全局来说,由于网络在所有位置(共51*39个)的参数相同,所以实际用尺寸为1×1的卷积网络实现。
需要注意的是:并没有显式地提取任何候选窗口,完全使用网络自身完成判断和修正。
侯选区域生成网络的训练
训练数据
对每个anchor给定标签选项,认定两种anchors为正样本:
- anchor/anchors与ground-truth box有着最高的IoU记为正样本
- 剩下的anchor/anchors与任何ground-truth box的IoU大于0.7记为正样本,IoU小于0.3,记为负样本
- 剩下的anchor/anchors记为非正样本,对训练没有贡献,不使用
同一个ground-truth可以确定多个anchors.
损失函数
这里使用的损失函数和Fast R-CNN内的损失函数原理类似,同时最小化两种代价:
- RPN可以BP算法和SGD算法完成end-to-end训练。每个mini-batch的数据包含着一张图片上的多个正样本和负样本。
- 在网络参数初始化上,前面的卷积层使用预训练的ImageNet的网络参数,新添加的层使用随机的高斯分布初始化权重.
代价函数
同时最小化两种代价:
a. 分类误差
b. 前景样本的窗口位置偏差超参数
原始特征提取网络使用ImageNet的分类样本初始化,其余新增层随机初始化。
每个mini-batch包含从一张图像中提取的256个anchor,前景背景样本1:1.
前60K迭代,学习率0.001,后20K迭代,学习率0.0001。 momentum设置为0.9,weight decay设置为0.0005。
共享特征
RPN和Fast R-CNN都需要一个原始特征提取网络(下图灰色方框)。这个网络使用ImageNet的分类库得到初始参数W0,但要如何精调参数,使其同时满足两方的需求呢?本文讲解了三种方法。

Alternating training(轮流训练)
- 先独立训练RPN,然后用这个RPN的网络权重对Fast-RCNN网络进行初始化并且用之前RPN输出proposal作为此时Fast-RCNN的输入训练Fast R-CNN
- 用Fast R-CNN的网络参数去初始化RPN
- 交换a,b训练过程即可
具体操作时,仅执行两次迭代(后面再迭代,效果没啥大的提升),并在训练时冻结了部分层。
Approximate joint training(近似联合训练)
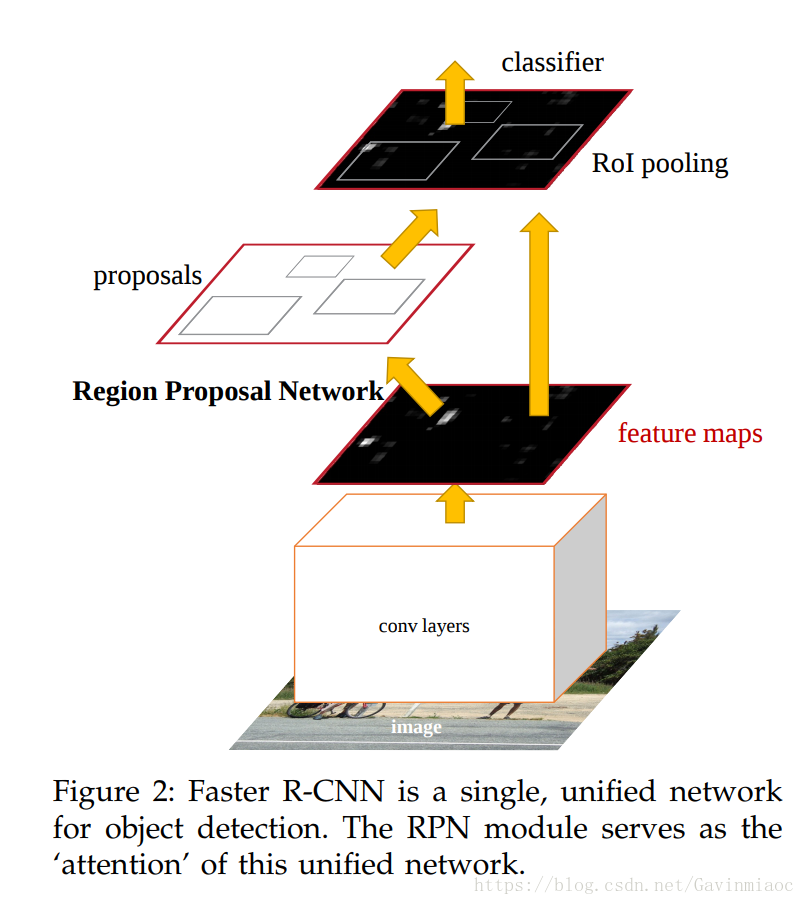
直接在上图结构上训练。proposals是由中间的RPN层输出的,而不是从网络外部得到。需要注意的一点,名字中的”approximate”是因为反向传播阶段RPN产生的cls score能够获得梯度用以更新参数,但是proposal的坐标预测则直接把梯度舍弃了,这个设置可以使backward时该网络层能得到一个解析解,能将训练时间减少20%-25%。(这里照搬别人的blog,自己没看懂晓雷)。
Non-approximate training(联合训练)
直接在上图结构上训练,上面的Approximate joint training把proposal的坐标预测梯度直接舍弃,所以被称作approximate,那么理论上如果不舍弃是不是能更好的提升RPN部分网络的性能呢?作者把这种训练方式称为“ Non-approximate joint training”,论文没有对这个方法进行讨论。
参考文献:
1.https://blog.csdn.net/u011534057/article/details/51247371
2.https://blog.csdn.net/u011974639/article/details/78053203#faster-r-cnn
3.https://zhuanlan.zhihu.com/p/24916624
4.https://zhuanlan.zhihu.com/p/31426458
5.https://blog.csdn.net/xg123321123/article/details/53073388