
NIPS-2015
NIPS,全称神经信息处理系统大会(Conference and Workshop on Neural Information Processing Systems),是一个关于机器学习和计算神经科学的国际会议。该会议固定在每年的12月举行,由NIPS基金会主办。NIPS是机器学习领域的顶级会议 。在中国计算机学会的国际学术会议排名中,NIPS为人工智能领域的A类会议。
目录
1 Motivation
State-of-the-art object detection networks depend on region proposal algorithms to hypothesize object locations. Advances like SPPnet and Fast R-CNN have reduced the running time of these detection networks, exposing region proposal computation as a bottleneck.
作者提出 Region Proposal Network (RPN) that shares full-image convolutional features with the detection network, thus enabling nearly cost-free region proposals(10ms per image).
2 Innovation
RPN,end to end
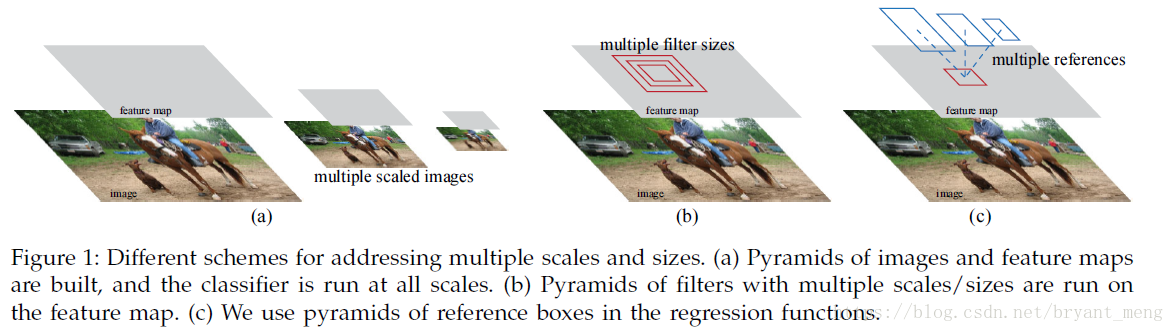
不是用 image pyramid 图1(a),也不是用 filter pyramid,图1(b),而是用 anchor,图一(c),可以叫做,pyramid of regression references
3 Advantages
- 5fps (including all steps) on a GPU——VGG
- state-of-the-art object detection accuracy on PASCAL VOC 2007, 2012, and MS COCO datasets with only 300 proposals per image
- ILSVRC and COCO 2015 competitions,the foundations of the 1st-place winning entries(eg:ResNet)
4 Methods
SS慢,EdgeBoxes 虽然能达到 0.2 second per image(和检测的时间差不多了),一个很直接的想法就是在 GPU上实现这些算法,但是 re-implementation ignores the down-stream detection network and therefore misses important opportunities for sharing computation.
相关工作先介绍了 object proposal的情况,然后是 Deep Net works for object detection(主要是 RCNN, fast RCNN 和 OverFeat),个人感觉对RCNN 和 OverFeat 的总结很精辟
R-CNN mainly plays as a classifier, and it does not predict object bounds (except for refining by bounding box regression).
In the OverFeat method, a fully-connected layer is trained to predict the box coordinates for the localization task that assumes a single object.
4.1 RPN
Note: RPN is class-agnostic 【R-FCN】《R-FCN: Object Detection via Region-based Fully Convolutional Networks》
4.1.1 Anchors
共享卷积的最后一层,ZF有 5 layers(256 dimension),VGG 有13 layers(512 dimension),
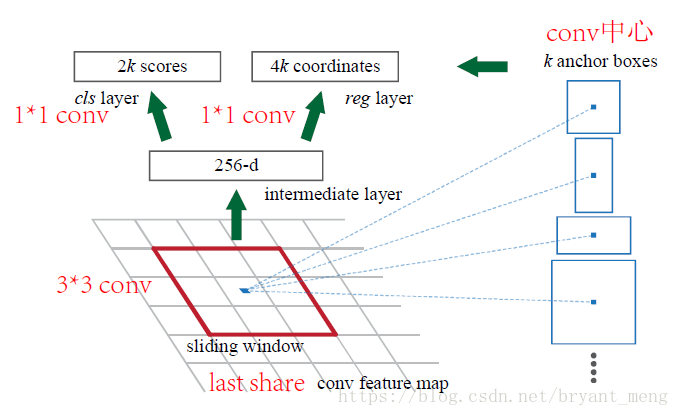
2k中 2 是 object or not object,k是每个3*3的 sliding window 中 anchor数量, 4k 中的 4 是 bbox
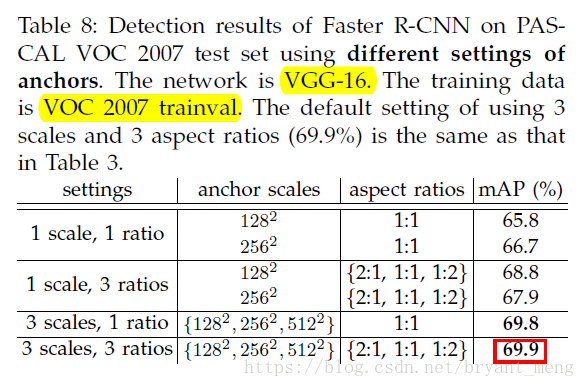
ratios 和 scales 的威力如下:
- Translation-Invariant anchors
相比与 MultiBox的方法,Faster RCNN的 anchor 基于卷积,有 translation-invariant 的性质,而且 参数量更少,(4+2)* k * dimension(eg,k=9,VGG dimension为512) parameters 为 ,更少的参数量的好处是,less risk of overfitting on small datasets,like PASCAL VOC
- Multi-Scale Anchors as Regression References
区别于 image pyramid 和 filter pyramid,作者用 anchor pyramid(不同的 scales 和 ratios),more cost-efficient,因为 only relies on images and feature maps of a single scales and uses filters(sliding windows on feature map)of a single size.
4.1.2 Loss Function
每个anchor进行2分类,object or not,positive 为 IoU>0.5或者max IoU,negative 为 IoU<0.3,其它的anchor对训练来说没有用
损失函数如下
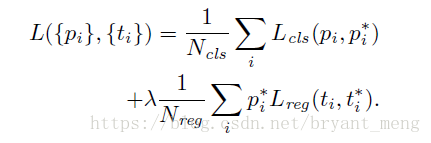
- :minibatch 中 anchor
- :predicted probability of anchor being an object.
- :is 1 if the anchor is positive, 0 if the anchor is negative
- :4 parameterized coordinates of the predicted bounding box
- :ground-truth box associated with a positive anchor
- :log loss
- :Smooth L1 loss,前面乘以了 表示 regression loss is activated only for positive anchors
Normalized by 和 (normalization is not required and could be simplified), 用来 balance parameters
- 设置为 mini-batch的大小,eg:256
- 设置为 numbers of anchor locations(~2400)
- 设置为 10,正好两种损失55开
的影响如下,Insensitive

具体的
和
如下:
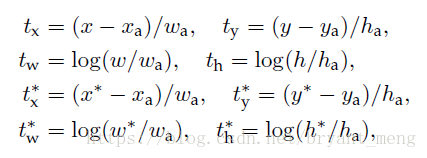
x,y 是 predict box 的中心,w 和 h 分别是 宽和高
分别表示 predict-box,anchor box 和 ground-truth box,y,h,w 的表示方法也一样
This can be thought of as bounding-box regression from an anchor box to a nearby ground-truth box.说白了,就是计算 (predict box 与 anchor 的 偏差) 和 (ground-truth 与 anchor的偏差)的损失
Note:这里的 bbox regression 不同于 Fast RCNN 和 SPPnet的,
Fast RCNN 和 SPPnet 的bbox regression: is performed on features pooled from arbitrarily sized RoIs, and the regression weights are shared by all region sizes.
Faster RCNN 此处的 bbox regression 是争对 per scales 和 per ratios的,To account for varying sizes, a set of k bounding-box regressors are learned. Each regressor is responsible for one scale and one aspect ratio, and the k regressors do not share weights.
4.1.3 Training RPNs
randomly sampls 256 anchors,这样会出现以下问题:but this will bias towards negative samples as they are dominate,所以我们按照1:1 的抽正负anchors,如果positive anchors不够128,pad negative anchors
We randomly initialize all new layers by drawing weights from a zero-mean Gaussian distribution with standard deviation 0.01.
4.2 Sharing Features for RPN and Fast R-CNN
Both RPN and Fast R-CNN, trained independently, will modify their convolutional layers in different ways. We therefore need to develop a technique that allows for sharing convolutional layers between the two networks, rather than learning two separate networks.
三种训练方法
- Alternating training(论文中采用的方法)
- Approximate joint training(效果会比交替训练好一些)
- Non-approximate joint training
作者用的是 交替训练,4-step Alternating Training
- RPN(ImageNet 初始化,RPN and Fast RCNN not share prameters)
- Fast RCNN(ImageNet 初始化,用RPN产生的proposal——替换掉SS产生的,训练Fast RNN,not share)
- 用上一步的训练好的参数,fine tuning RPN(share)
- 用重新训练的RPN提出的proposal, fine tuning the unique layers of Fast RCNN 也就是 head 部分(share)
为什么不一二三四,二二三四,换个姿势,再来一次?
A similar alternating training can be run for more iterations, but we have observed negligible improvements.
4.3 Implementation Detais
- Train and test 都是 single scales,reshape shorter side s = 600 pixels
- Image pyramid : trade off accuracy and speed(没采用)
- Anchors:scales, 、 、 ,ratios: , , ,见表一,表中红色的字体是预设的 anchors(2:1),表中列出来的是 bbox regression 之后的结果

- 训练的时候,剔除 cross image boundaries (跨图边界)的anchors,测试的时候,clip(裁剪) to the image
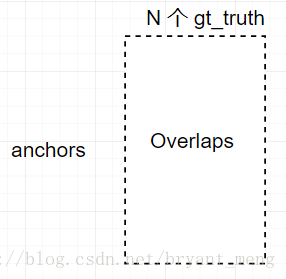
- RPN proposal 有很多overlap,我们用了非极大值抑制(NMS),iou设置为0.7,NMS does not harm the ultimate detection accuracy,但是减少了 proposal 的数量。论文中 用 top-2000的proposal 进行 train。为什么NMS overlap thresold 设置为0.7呢?
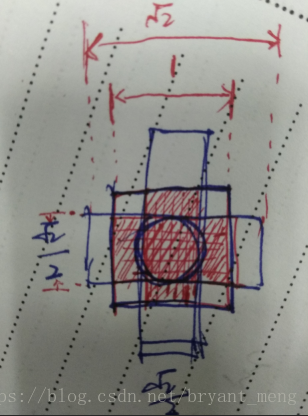
看上面这个图,就是 , , 三种情况,假如 ground truth 和 1:1一样大,那么与 , 的 IOU都为 ,这样的话会导致同一目标产生两种特征图,不利于网络的学习,所以把 IOU设置为0.7,尽量缓解这种情况(只是一种解释哟)
5 Experiments
5.1 Ablation Experiments
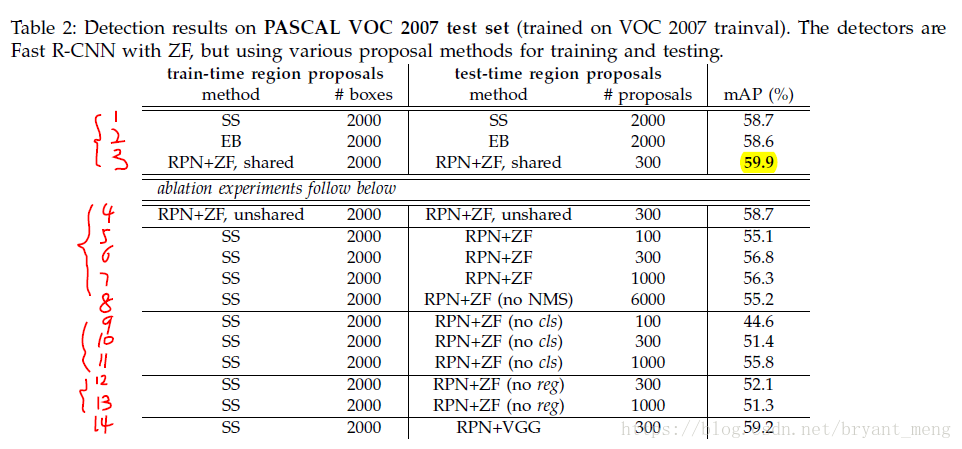
- 1,2,3对比,3 更好,the fewer proposals also reduce the region-wise fully-connected layers’ cost(table 5可以看到)
- 3,4 对比,share 好
- 3,6 对比,RPN+fast RCNN 比 SS+ Fast RCNN 好,train test 的 proposal 不一样
- 4,8 对比, NMS 影响不大
- 7,11差距不算大,9,11差距明显,cls 排序很重要
- 6,12对比,reg 很重要
5.2 VOC 07/12 实验结果
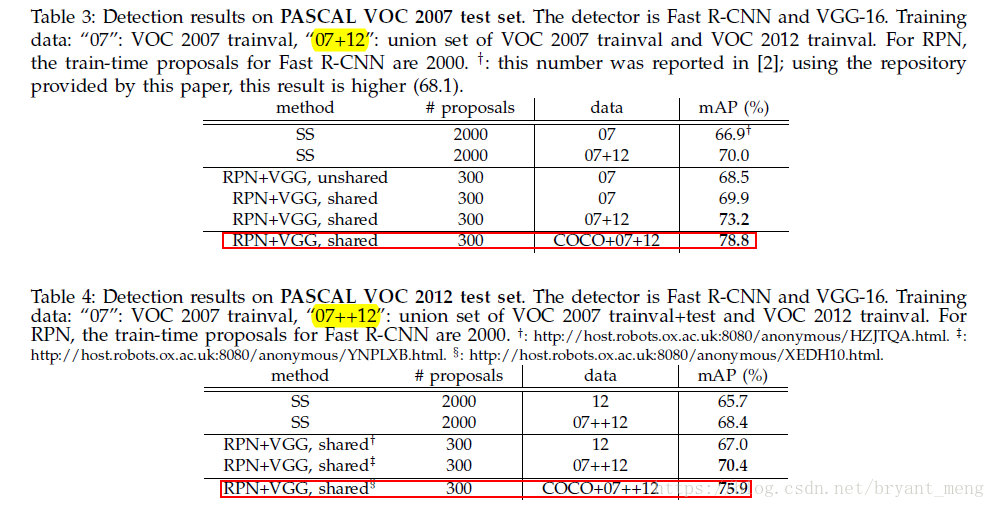
5.3 速度(ms)

5.4 recall-to-IoU
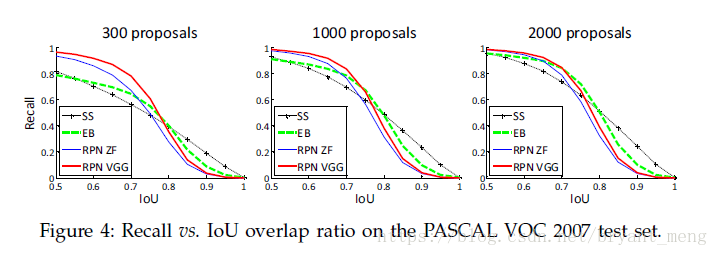
RPN 的 proposal 从 2000 drops 到 300 效果差不多
5.5 PK (one-stage overfeat)

5.6 COCO 上的结果

VGG 换成 ResNet, ensemble一下, COCO 2015 object detection 冠军
结构图

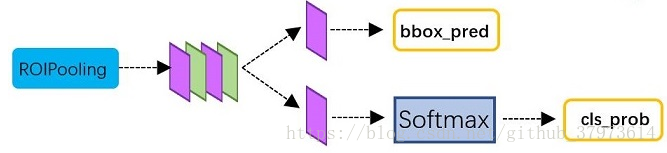
Note: reshape 是为了softmax操作,softmax操作中,第一维必须是类别数,类别如果是2,object or not,则是 class-agnostic ,如果类别是,比如 VOC 数据集,20+1类, 则是 class-specific


Faster RCNN-RES101 结构图
