0 摘要
卷积神经网络已被广泛应用于计算机视觉领域,显着改善了最先进的技术。在大多数可用的CNN中,使用softmax loss(作为监督信号)训练深度模型。为了增强深度学习特征的判别力,本文提出了一种新的监督信号,称为center loss,用于人脸识别任务。具体而言,center loss为每个类(在人脸模型中,一个类就对应一个人)指定了一个类别中心。同一类的图像对应的特征都应该尽量靠近自己的类别中心,不同类的类别中心尽量远离。更重要的是,我们证明了所提出的center loss是可训练的并且可以在CNN中优化。通过联合使用softmax loss和center loss,我们可以训练一个鲁棒的CNN,以获得两个关键的学习目标的深度特征,即类间分散程度和类内紧凑程度,这对于人脸识别是非常重要的。通过联合监督,可以看到我们的CNN在几个重要的人脸识别数据集(LFW,YTF,MFC)上取得了最佳准确性。
1 引言
卷积神经网络在计算机视觉领域取得了巨大成功,显著改善了分类问题最先进的技术。例如物体分类,场景识别,动作识别等。它得益于大规模的训练数据集ImageNet和端到端的学习框架。最常见的就是利用CNN进行特征学习和标签预测,将输入数据映射到深层特征(最后一个隐藏层的输出),然后映射到预测标签,如图1所示。
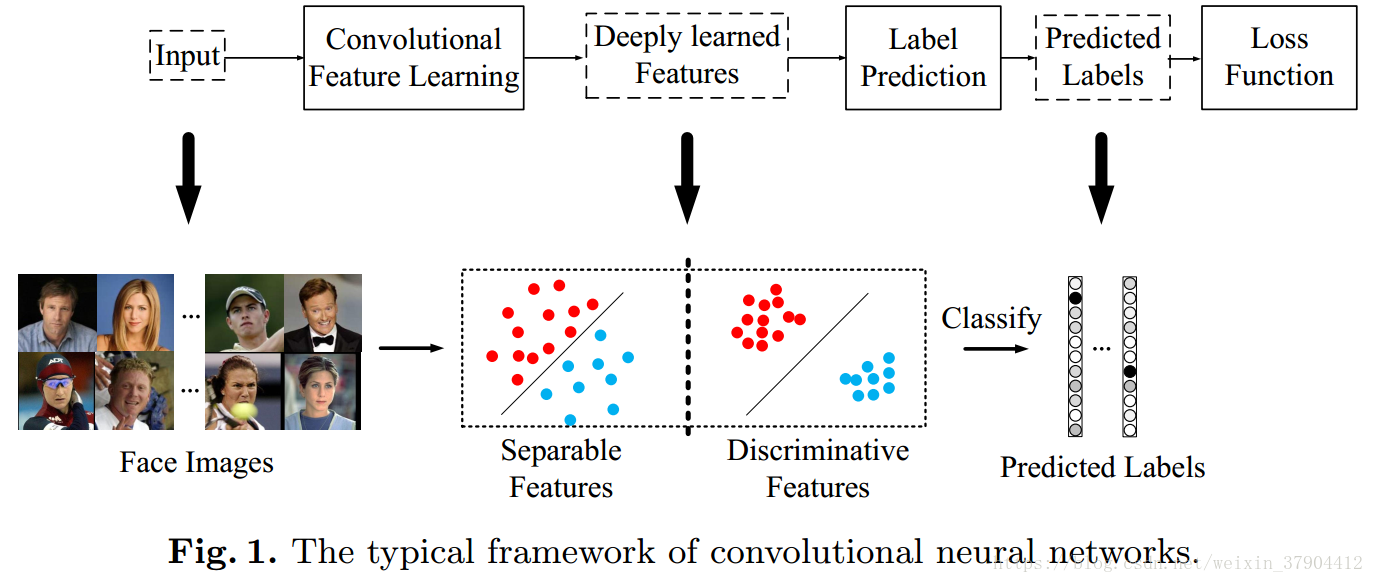
在通用的物体识别,场景识别或动作识别中,测试样本的类别在训练集合内,也称为close-set identification。 因此,预测标签是主要目标,并且softmax loss能够直接解决分类问题。 这样,标签预测(最后一个完全连接的层)就像一个线性分类器,对深度学习的特征进行分离。
对于人脸识别的任务,深度学习的特征不仅仅需要可分离,而且还需要具有区分性。因为预先收集所有可能的测试身份以进行训练是不切实际的,因此CNN中的标签预测并不总是适用的。 深度学习的特征需要具有区分性和足够的通用性,以便识别新的未知的未标记的类别。 图1中间的那幅图,左图画出的可分离特征,右图画出的不仅可分离而且有区分力特征。一个类如果太胖(左图可分离特征),那么出现的结果就是类内距离>类间距离。(但是任意红点之间的距离本应该小于红蓝之间的距离)。 左边是softmax一般结果,右边是center loss结果。我们期望的特征不仅可分,而且必须差异大(正如右图那样)。有区分度的特征可以通过KNN算法实现很好的分类。 但是,softmax loss只会鼓励特征具有可分离性(不具有可区分性), 这样的特征不足以有效识别人脸。
为了能学习出有区分性的特征,构建高效的损失函数是一个需要正视的问题。因为随机梯度下降(SGD)基于最小批次优化CNN,不能很好地反映特征在全局的分布。 由于训练集的规模庞大,在每次迭代中输入所有训练样本是不切实际的。 作为替代方法:siamese network中,采用的损失函数是contrastive loss;FaceNet中,采用的损失函数是triplet loss。然而,与单个图像样本相比,随着训练图像对或图像三元组数量显着增加,不可避免地导致收敛缓慢和不稳定。 通过仔细选择训练图像对或三元组,问题可能会得到缓解,但这显着增加了计算复杂度,并且训练过程变得不方便。
本文中,我们提出了一种新的损失函数center loss,有效地提高深度特征的区分性。具体来说,我们学习每个类的类别中心(类别中心与深度特征具有相同的维度)。在训练过程中,我们同时更新中心并最小化深度特征与其相应的类别中心之间的距离。 在softmax loss和center loss的联合监督下对CNN进行训练,用一个超参数来平衡两个监督信号。softmax loss迫使不同类别的深层特征保持分离。center loss有效地将同一类别的深层特征拉到他们的中心。 通过联合监督的训练,不仅扩大了类间的特征差异,而且减少了类内特征变化。 因此,深度特征的判别力可以大大提高。 我们的主要贡献总结如下:
1.我们提出了一种新的损失函数(center loss)来最小化深度特征的类内距离。 据我们所知,这是首次尝试使用这种损失函数来帮助监督CNN的学习。 通过center loss和softmax loss的联合监督,可以获得高度区分性的特征以用于鲁棒人脸识别,这得到了我们实验结果的支持。
2.我们表明,所提出的损失函数在CNN中非常容易实现。 我们的CNN模型是可训练的,可以通过标准SGD直接优化。
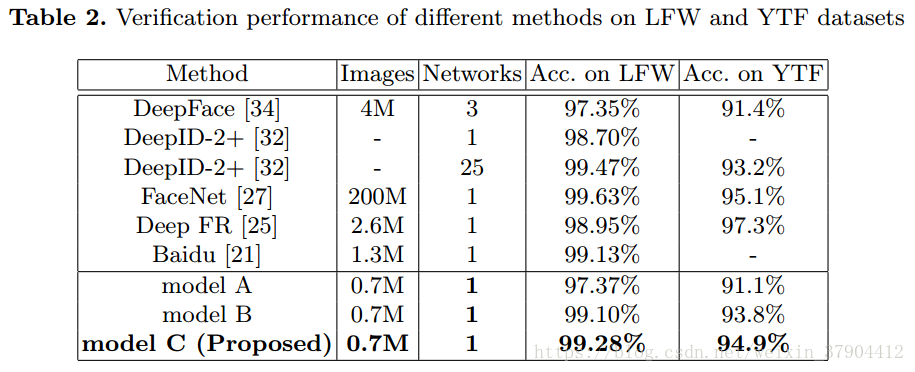
3.我们的CNN在几个重要的人脸识别数据集(LFW,YTF,MFC)上取得了最佳准确性。
2 相关研究
通过深度学习的人脸识别在这些年取得了一系列突破。 将一对脸部图像映射到一定距离的想法从Siamese network开始。 Siamese network被用于相似性度量,网络的输出是一个相似度数值。对于两张同一个人的人脸图像输出值小,对于两张不同人的人脸图像输出值大。等等。
3 方法
在本节中,我们将详细阐述我们的方法。 我们首先使用一个示例直观地展示深度特征的分布。 我们提出center loss提高深度特征的区分性,然后进行一些讨论。
3.1 一个示例
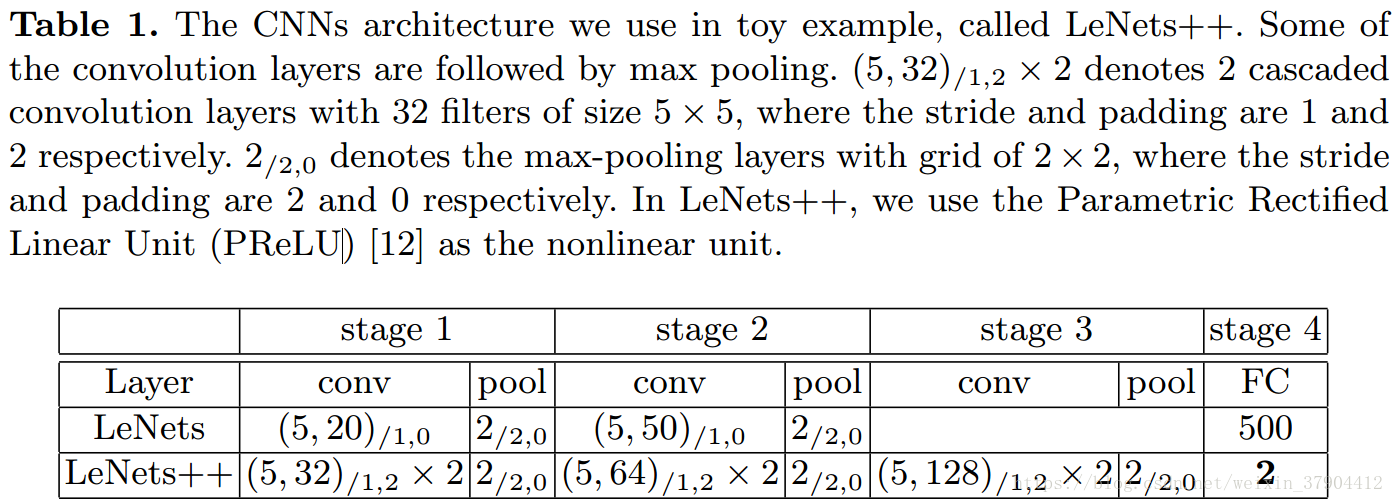
在示例中,我们使用MNIST数据集。我们将LeNets修改为更深更宽的网络,将最后一个隐藏层的输出数量减少到2(这意味着深度特征的维数为2)。 所以我们可以直接在二维坐标上绘制特征,进行可视化。 表1给出了网络架构的更多细节。
其损失函数采用的是softmax loss:
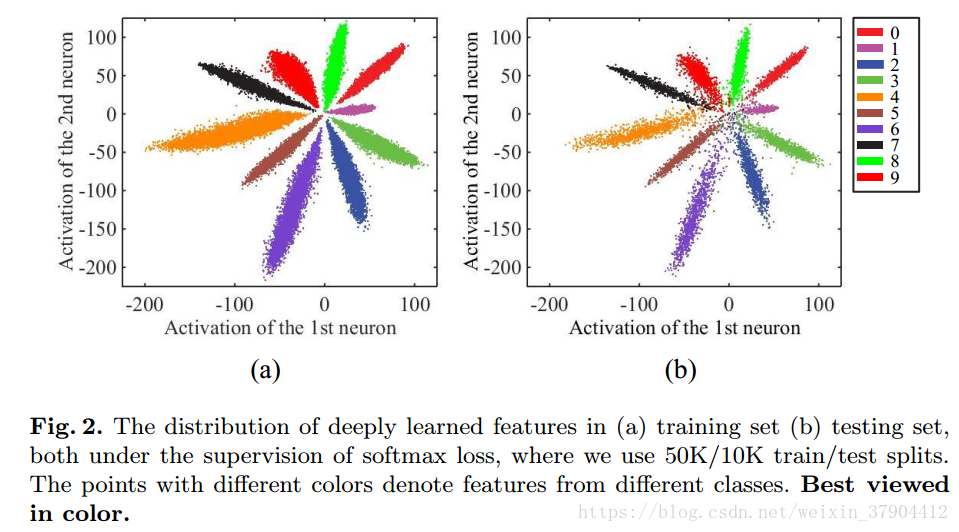
画出每一类对应的2维向量,如图2。由于最后的全连接层同线性分类器,不同类别的深层特征通过决策边界来区分。 从图2我们可以观察到:
1.在softmax loss的监督下,深度学习的特征是可分离的;
2.深度特征不具有足够的区分性,因为它们仍然表现出显着的类内变化。 因此,直接使用这些特征进行识别是不合适的。
我们期望的特征具有的特点是:
1.同一类对应的特征表示尽可能接近。但这里同一类的点可能具有很大的类间距离。
2.不同类对应的特征表示尽可能远。但这里图中靠近中心的位置,各个类别的距离都很近。
3.2 center loss
那么,如何开发一个有效的损失函数来提高深度特征的判别力呢? 直观地说,在保持不同类别的特征可分离的同时最小化类内变化是关键。 为此,我们提出center loss函数,如公式2所示。
其中输入的人脸图像为
,该人脸对应的类别为
,对每个类别都规定一个类别中心为
。希望每个人脸图像对应的特征
都尽可能接近其中心
。上述公式有效地定义了类内差异,理想情况下,
应该随着深度特征的变化而更新。换句话说,我们需要考虑整个训练集,并在每次迭代中,类别
的最佳中心应该是它对应的所有图片的特征的平均值。这是不切实际的,因为每一次迭代对所有图片计算一次
的计算复杂度太高。 因此,center loss不能直接使用。 这可能是迄今为止CNN中从未使用这种center loss的原因。
为了解决这个问题,我们进行了两处必要的修改。首先,我们不是针对整个训练集更新中心
,而是基于最小批次进行更新。 在每次迭代中,通过平均相应类的特征来计算中心(在这种情况下,一些中心可能不会更新)。(从下面的公式可以看到,对
更新的做法是:对当前batch内的
也计算梯度,并使用该梯度更新
)。其次,为了避免少量误标样本造成的大扰动,我们使用
来控制中心
的学习率。更新的计算公式如下:
其中,
,
。
我们采用softmax loss和center loss的联合监督来训练CNN进行特征学习,公式如下:
显然,由center loss监督的CNN可以训练,并且可以通过标准SGD进行优化。 标量
用于平衡两种损失函数。如果
设为0,损失函数就是传统的softmax loss,这是联合监督训练的特例。在算法1中,我们概括了CNN中的联合监督学习细节。
(总结:随机初始化各个中心
,接着不断地取出batch进行训练,在每一个batch中,使用总损失L,除了对模型的参数进行更新外,也对
计算梯度,并更新中心的位置。)

我们还进行实验来说明
如何影响深度特征的分布。 如图3。选择适当的
,深层特征的判别力就可以显着增强。 此外,
越大,生成的特征就会具有越明显的内聚性。 因此,联合监督有利于提高深度特征的判别力,这对于人脸识别至关重要。

3.3 讨论
1.联合监督训练的必要性
如果我们只使用softmax loss作为监督信号,则由此产生的深度特征将会有较大的类内变化。 另一方面,如果我们只通过center loss来监督CNN,那么深度特征和中心就会退化为零(此时center loss非常小)。 简单地使用它们中的任何一个都不能实现区别性特征学习。 因此,我们有必要结合他们共同监督CNN,我们的实验证实了这一点。
2.与contrastive loss,triplet loss的比较
最近,contrastive loss和triplet loss的提出,以提高深度学习的脸部特征的判别力。 然而,当从训练集中构成样本对或样本三元组时,contrastive loss和triplet loss都会受到数据扩增的影响。 我们的center loss与softmax loss具有相同的要求,不需要复杂的训练样本复合。 因此,我们的CNN更加高效且易于实施。 此外,我们的损失函数更直接地以类内紧密性为学习目标,这对于区分性特征的学习是非常有益的。
4 实验
4.1 实验细节
预处理:图像中的所有人脸和他们的landmarks由MTCNN算法检测。 我们使用5个landmarks(两只眼睛,鼻子和嘴角)进行相似变换。 当检测失败时,如果图像处于训练集中,我们只是丢弃图像,但如果图像是测试图像,则使用提供的landmarks。 脸部图像被裁剪为112×96RGB图像。 RGB图像中的每个像素通过减去127.5,然后除以128来归一化。
训练集:我们使用CASIA-WebFace,CACD2000,Celebrity+数据集。图像被水平翻转进行数据增强。
CNNs: 这部分的CNN模型都是相同的结构,细节如图4。为了公平的比较,我们训练了三个模型。model A仅用softmax loss训练;model B用softmax loss和contrastive loss训练;model C用softmax loss和center loss来训练。model A和model C初始学习率为0.1,在16K,24K次迭代的时候除以10。28K次迭代后完成训练,大约需要14个小时。 model B,我们发现它收敛较慢。 因此,我们将学习速率初始化为0.1,在24K,36K次迭代的时候除以10。 总迭代次数为42K,需要22小时。
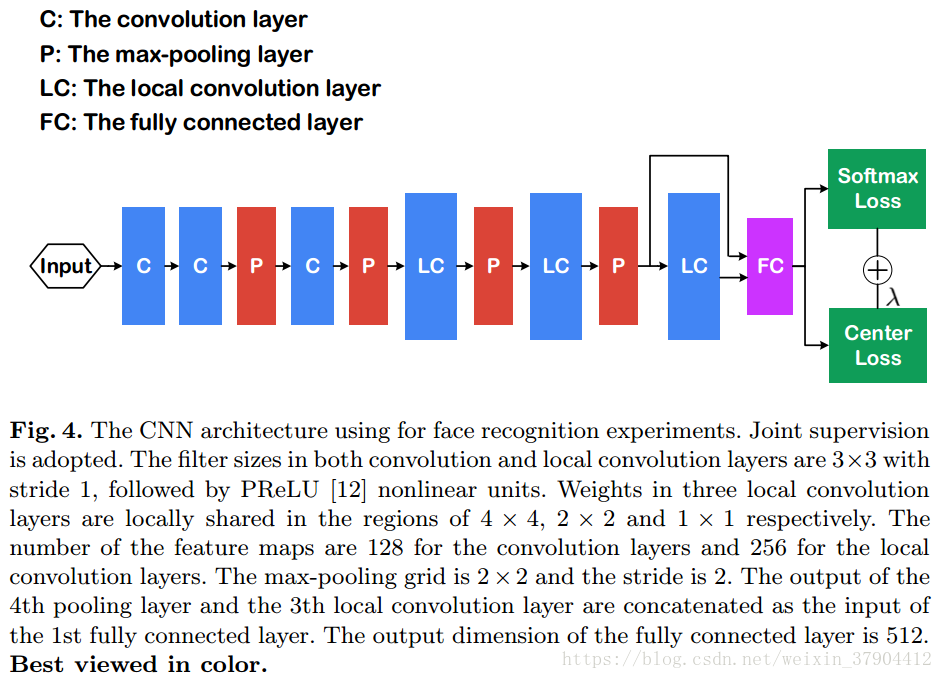
测试细节:深层特征取自第一个FC层的输出。 我们为每个图像和其水平翻转的图像提取特征,并将它们的特征连接起来作为最终特征表达。经过PCA降维后,两个特征向量之间的余弦距离作为最终得分。通过KNN分类器进行识别任务,通过设置阈值进行验证任务。所有测试使用单一模型。
4.2 参数 和
超参数
控制类内内聚性,
控制模型C中心
的学习率。它们对我们的模型都是必不可少的。 所以我们进行两个实验来研究这两个参数的敏感性。
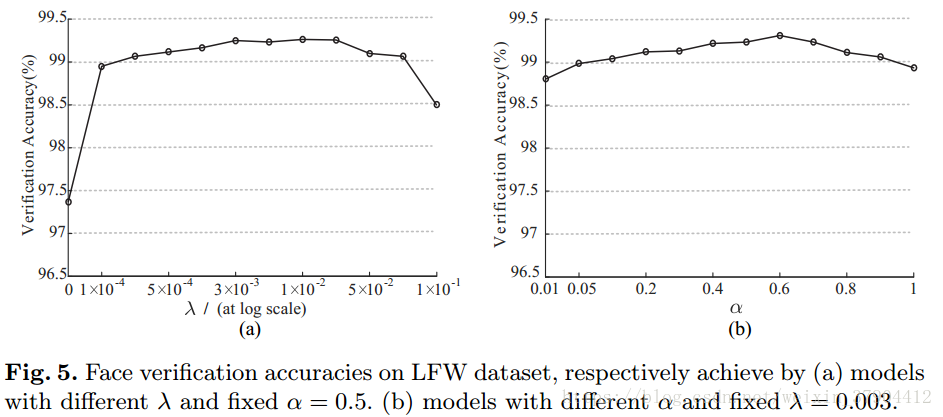
在第一个实验中,我们将
固定为0.5,并将
从0增长到0.1,从而学习不同的模型。 这些模型在LFW数据集上的验证精度如图5所示。很明显,仅使用softmax损失(在这种情况下,
)不是一个好选择,导致验证性能较差。 正确选择
的值可以提高深度特征的准确性。 我们还观察到,模型的性能随着
的波动,在很大范围内基本保持稳定。
在第二个实验中,我们固定
,并将
从0.01增长到1,从而学习不同的模型。 这些模型在LFW上的验证精度如图5所示。同样,我们模型的性能随着
的波动,在很大范围内基本保持稳定。