文章地址Object Detection in Videos with Tubelet Proposal Networks
废话不多说,直接翻译,还是只翻译方法部分,相关工作、结果和结论就不多说了。
Abstract
随着大规模ImageNet VID数据集的出现,视频目标检测得到了越来越多的关注,与静态图片不同,视频中的时间信息对目标检测而言是十分重要的。为了完全运用视频中的时间信息,最新的方法(参考我上一篇翻译)就是基于时空tubelet——一系列相关联的边框。但是,现有的方法在产生tubelet时,效率和质量都有很大的问题。基于motion的方法可以有效地获得密集的tubelet,但是只是一些框架,并不能很好的长期时间信息。而基于appearance的方法,通常包含目标跟踪,可以产生长的tubelet,但是计算量非常庞大。在这篇论文中,我们建立了一个框架,包含了一个可以产生时空候选区域的tubelet proposal网络,还有一个长短时间记忆网络,可以融合时间信息来获取高准确率。在大规模数据集ImageNet VID上的实验表明了这种框架可以在视频目标检测中取得很好的结果。
1. Introduction
目标检测的性能随着深度神经网络的出现而大大提高。在很多计算机视觉任务中,比如目标检测、语义分割、跟踪、场景理解、行人检测等,类似于GoogLeNet、VGG、ResNet等神经网络用来提高在大规模计算机视觉数据集上的学习能力。静态图像中最高水平的目标检测框架就是基于这些网络,由三个主要步骤组成。首先基于每个位置包含目标的可能性,从输入图片中产生许多候选边框,然后从每个候选边框中提取特征并将其分类,最后,候选边框和它们相对应的分类值经过一些后处理技术进行微调矫正,比如非最大值抑制,得到最终检测结果。类似于Fast R-CNN和Faster R-CNN等许多不同框架都是遵照这个研究方向,最终将目标检测问题化为一个端对端的神经网络问题。
尽管静态图像的目标检测取得了巨大的成功,但是视频目标检测还是一个非常有挑战性的问题,许多因素导致了这个问题,比如同一目标随着时间变化可能外表出现巨大的不同变化、目标与目标之间的互相影响、运动模糊,还有静态数据与动态数据之间的区别。2015年,ImageNet提出了一个视频目标检测的任务,提供一个大规模的视频数据集,要求对视频中的每一帧中的目标检测并标注分类。
与静态目标检测中的候选边框(bounding box proposals)相同,视频目标检测中的边框被称为tubelet,tubelet是一系列候选边框的集合,视频目标检测算法使用tubelet来获得时间上的信息。但是,tubelet的产生一般是基于对每一帧的检测结果,过程非常耗时,比如,我上一篇翻译的文章中,产生每一帧中的每一个检测边框都需要0.5s,而一个视频通常有上百帧,每一帧又有上百个检测边框,所以无法在一个可以接受的时间范围内产生足够的候选tubelet。在Tubelets with con- volutional neural networks for object detection from videos这篇文章中,一种基于运动的方法——optical-flow-guided传播可以有效地产生密集的tubelet,但是tubelet只能持续几帧,因为这种方法在长期目标跟踪方面是不连续的。理想的tubelet一方面可以持续很多帧以利用时间信息,一方面在每一帧也达到足够多的数量以保证高的召回率(Figure 1)。

为了解决这个问题,我们设计了一个框架,包含一个Tubelet Proposal Network(TPN),从静态候选区域开始,同时获取上百个不同的tubelet,还包含一个长短时间记忆Long Short-Term Memory(LSTM)子网络来根据tubelet估计目标的确信值。TPN可以利用池化后的特征图高效的产生候选tubelet,在开始帧给定一个静态候选边框区域位置,对于不同帧的这个同一位置,得到其中的特征作为一个多帧回归神经网络TPN的输入数据。TPN可以学习前景目标复杂的运动模式,生成鲁棒的tubelet候选。视频中的上百个候选区域可以被同时检测,这种tubelet区域比每帧独立检测出的tubelet区域的质量要高,也表明了时间信息的重要性。从tubelet边框中提取出来的视觉特征自动排列成特征序列,适合LSTM网络学习时间特征使用,可以抓住长期时间独立性以得到精确的分类结果。
这篇论文的贡献是我们设计了一个新的深度学习框架,结合了tubelet proposal generation和temporal classification两者。生成tubelet proposal的算法是抓住了目标位置时空信息,而时间LSTM模型是使用视觉特征和时间特征对tubelet proposal进行分类。现有的检测系统经常会忽略这种时间特征,但是其对于视频目标检测十分重要。
3.Tubelet proposal network
现有的视频目标检测方法使用两种方法产生tubelet proposals:从某几张关键帧开始使用单一目标跟踪器,或者对某一帧的检测结果进行一些多目标跟踪算法,比如tracking-by-detection method。这些方法要么计算量太大,无法产生足够数量的tubelet,要么则是容易漂移到其他位置,导致检测和跟踪的失败。对于大规模ImageNet VID数据集来说,一个100fps的单一目标跟踪器,需要56天的时间才能做到每一帧产生300个候选边框。


我们设计了一个TPN来产生tubelet,见Figure 2,TPN有两个主要的部分:第一个子网络基于一个单一帧的静态候选区域抓取视觉特征,由于CNN的感受野足够大,针对运动中的物体,我们可以在同样的边框位置操作特征图池化,来抽取视觉特征。基于池化后的视觉特征,第二部分是一个回归层,用来估计边框随时间变化而变化的位置。
3.1 Preliminaries on ROI-pooling for regression
有一些方法也用到了特征图池化,Fast R-CNN框架就是用视觉特征图的ROI池化来做目标分类和边框回归,输入图像喂给CNN,然后经过前向传播生成特征图。给定候选目标,直接根据边框的坐标对特征图进行ROI池化而得到特定目标的视觉特征。这种方法使CNN中的前向传播只需要对一张图片使用一次,减少了计算量。记bti=(xti, yti, wti, hti)为t时的第i个静态候选边框,x、y、w、h分别代表了边框中心的坐标、宽度、高度。边框bti通过ROI池化得到视觉特征rti。
特征rti不仅可以做目标分类,也可以用来做边框回归,表明了视觉特征包含了描述目标位置的必要信息。所以,我们决定用ROI池化提取多帧视觉特征,然后通过回归,用视觉特征产生tubelet。
3.2 Static object proposals as spatial anchors
静态候选区域是一些未标注的边框,表明了目标可能在的位置,可以用SelectiveSearch、Edge boxes、Region Proposal Networks等方法得到。但是视频目标检测需要目标的时空位置信息,对候选区域分类十分重要。
视频中,目标的移动总是复杂难以预测的。静态的候选区域单帧通常有高召回率(>90%),这个值非常重要,因为它是目标检测能达到的最高正确率。所以,我们使用静态候选区域作为视频目标检测中的starting anchor来产生tubelet,如果目标的动作可以被鲁棒地预测,我们就可以在视频中保持高的召回率。
记b1i为t=1时的一个静态候选区域,为了从b1i开始生成一个tubelet proposal,从第一帧到第w帧,我们都对b1i同样的位置进行池化,得到w帧的视觉特征:r1i, r2i, …, rwi,以用来生成tubelet proposal。我们把b1i称作“spatial anchor”。池化后的这些回归视觉特征包含了目标的外表信息。恢复这些视觉特征之间的对应性,我们可以得到一个精确的tubelet proposal,下一个章节详细阐述了这一步骤的模型。
我们之所以可以从连续几帧都从同样的位置提取视觉特征,是因为CNN有很大的感受野,所以即使从一个很小的边框中取出视觉特征,它所包含的视觉内容是远远多于这个边框中的内容的,所以在连续的帧中的同样位置提取特征可以有效抓取目标的运动方式。在Figure 2中,我们阐述了使用“spatial anchor”来产生tubelet proposal的方法,用排列好的同样位置的特征来预测目标的行动。
我们用含有Batch Normalization(BN)模型的GoogLeNet作为TPN,ROI池化层连接到BN模型的“inception_4d”,其具有363个像素的感受野。所以这个网络模型可以在同样位置做池化时,提取363个像素的运动,这样的范围对于短期运动来说完全足够。每一个静态候选区域作为特征抽取的anchor。
3.3 Supervision for tubelet proposal generation
我们的目标就是在每一帧产生高召回率的tubelet proposals,可以精确的检测到目标。基于位置bti抽取到的视觉特征r1i, r2i, …, rwi,我们训练一个回归网络R(·),可以根据已经找到的spatial anchor有效地预测目标的运动:
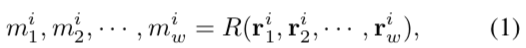
目标运动mti定义为mti=(
xti,
yti,
wti,
hti):

一旦我们得到了这样的相对运动,tubelet的实际边框位置就可以确定。我们将串联起来的视觉特征([r1i, r2i, …, rwi]T)作为一个全连接层的输入,输出为:
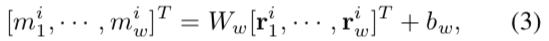
其中Ww
fw*4w,bw
4w。
剩下的问题就是如何设计一种正确的监督方式来学习相对运动,我们最主要的假设就是tubelet proposal应该与已经标注的目标一样有连贯的、持续的运动模式。但是,即使给定了静态候选区域作为开始的anchor,那些tubelet proposal往往与已经标注为真实的目标并不是100%重合(IoU)的。所以我们要求那些接近于真实边框的静态候选边框,继续跟随真实边框的运动模式,比如说,如果一个静态候选目标bti与真实边框
ti有大于0.5的重合度,并且没有其他真实边框与这个静态候选目标的重合度要大于这个值,那么回归层就努力的依照
ti的运动模式
ti来产生tubelet proposal。而相对运动模式
ti=(
ti,
ti,
ti,
ti)可以根据真实边框在t=1的时候的值下定义——即
1i,定义方式参照(2)式。显而易见
1i=(0, 0, 0, 0),我们只需要估计
2i至
wi。由这种方法得到的tubelet proposal,在一定程度上可以避免累积误差。
运动模式由均值
t和标准差
t归一化:

为了产生N个tubelet proposal,使其与其相对应的真实边框的运动模式相同,我们最小化下述目标函数:

{
}和{M}分别是所有正则化的运动目标和网络输出,其中d函数为边框回归中平滑后的L1损失:

网络输出
ti映射回真实的相对运动mti中:

根据定义,如果一个静态候选目标与真实目标有重叠,那在之后的帧中,它也会与真实目标有重叠。
3.4 Initialization for multi-frame regression layer
时间窗口的大小也是TPN的一个重要因素,最简单的模型是一个两帧模型。对于一个给定的帧,我们提取这一帧和下一帧中同样位置的视觉特征,都在spatial anchor中提取,串联成[r1i, r2i]T,用来判断b1i在第二帧中的运动,但是由于两帧模型只在一个极短的时间窗口中运用了极少的时间信息,得到的tubelet也许会不够平滑,产生漂移。增加时间窗口可以得到更多的时间信息,从而预测更复杂的行为模式。
给定一个时间窗口的大小w,抽取的视觉特征的维度是fw,f是单帧中spatial anchor抽取的视觉特征的维度(比如,BN模型中“inception_5d”特征有1024维)。所以,回归层的参数大小是
fw*4w,并且随着时间窗口的数量w成二次增长。
如果时间窗口的尺寸很大,随机初始化这样一个很大的矩阵不利于建立一个好的回归层。作者用“block”初始化方法,用两帧模型中学习到的特征来初始化多帧模型。

在Figure 3中展示了如何使用一个预训练好的两帧模型的回归层初始化一个5帧模型。由于第一帧的动作
1i总是(0, 0, 0, 0),我们只需要预测其余帧的动作。输入特征为两帧特征的串联,参数矩阵W2大小为
2f*4,偏置项b2大小为
4。对于5帧回归层来说,参数矩阵W5大小为
5f*(4*4),偏置项b5大小为
(4*4)。从图中可以看出,我们用第一帧和第二帧的的特征去预测第二帧的运动,用第一帧和第三帧的特征预测第三帧的行动……所以W2被分成两个子矩阵A
f*4,B
f*4来填充W5的相对应的部分,偏置项b5是b2重复4次。
在实验中我们首先训练一个随机初始化的两帧模型,然后用这个模型初始化多帧回归层。
4. Overall detection framework with tubelet generation and tubelet classification
基于TPN,我们搭建了一个高效的视频目标检测框架,与单个目标检测器相比,我们只需要9天就可以在ImageNet VID数据及上产生密集的tubelet proposals。网络还可以使用tubelet proposal中的时间信息提高检测准确性。在Figure 2中可以看到,框架主要由两个部分组成,第一个是产生候选tubelets的TPN,第二个网络是一个CNN-LSTM分类网络,可以将tubelet中的每一个边框分到不同的类别中。
4.1 Efficient tubelet proposal generation
TPN可以用时间窗口w对每一个静态候选区域做预测。对于大规模数据集的视频目标检测来说,我们需要的不仅仅是同时产生上百个tubelet,而且需要产生的tubelet都足够长到可以从中分析时间信息。
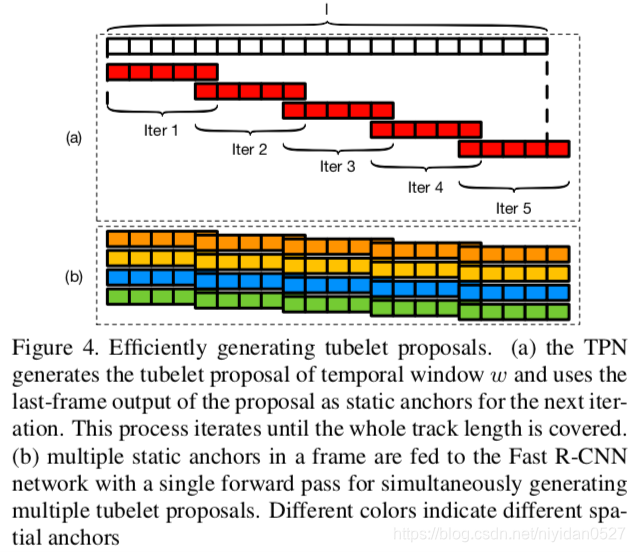
产生一个长度为
的tubelet(见Figure 4(a)),我们用第一帧的静态候选目标作为spatial anchor,然后不断地应用含有时间窗口w的TPN,直到
帧都有tubelet。前一次迭代的最后预测到的位置,作为后一次预测开始的anchor。
在同一个开始帧中有N个静态候选目标,底层CNN使用一次前向传播得到特征图,这种方法可以高效地产生上百个tubelet proposals(见Figure 4(b))。
与之前的单目标检测不同的是,我们的方法可以非常高效地同时产生大量的tubelet proposals。在
Object Detection from Video Tubelets with Convolutional Neural Networks这篇文章中,一个目标需要0.5fps,所以对于一个含有300个spatial anchors的视频,一帧需要150秒。而我们的方法一帧需要0.488秒,比这篇文章快300倍。与
Learning to Track at 100 FPS with Deep Regression Networks这篇文章的100fps相比,也快了6.14倍。
4.2 Encoder-decoder LSTM(ED-LSTM) for temporal classification
在有了长度为
的tubelet proposal之后,从tubelet边框位置可以得到视觉特征ul1, ul2, …, uli。现有的方法主要是在后处理中用时间信息,向相邻帧传输检测目标或者平滑检测值。检测结果的时间连续性确实很重要,但是为了抓住tubelets中的变化,我们还需要学习边框中的判别时空特征discriminative spatiotemporal feature。
如Figure 2所示,分类子网络包含一个CNN,将输入图像处理成特征图。从每个tubelet proposal中池化得到的分类特征会被喂给一个一层的长短时间记忆网络(LSTM,见Long short-term memory这篇文章)。 它是一种特殊的循环神经网络,在最近几年中被广泛运用在学习时空特征中。每一个LSTM单元都包含一个记忆单元以传达视觉信息。
LSTM对每一个时间步长t和第i个tubelet的输入为前一帧的cell state ct-1i和hidden state ht-1i,还有t时的分类特征uti。LSTM的开始状态(c0i, h0i)被设为0,输出是hidden states hti,连接到两个全连接层:一个用来做预测分类确信值,另外一个用作边框回归。最基准的LSTM(vanilla LSTM)的一个问题就是开始的状态会大大影响刚开始若干帧的分类结果。我们搭建了一个encoder-decoder LSTM模型(见Figure 2),输入特征首先被喂给一个LSTM编码器,将整个tubelet的特征编码进memory,然后memory和hidden states被喂给LSTM解码器,这一步可以将tubelet以相反的方式进行分类:从最后一帧处理到第一帧。用这种方法,我们可以利用过去和未来的两方面的信息,从而提高检测准确率。由于全零状态初始化而产生的问题也会得到有效的解决。