目录
主要贡献点有两条:
1. 提出了一种relation module,可以在以往常见的物体特征中融合进物体之间的关联性信息,同时不改变特征的维数,能很好地嵌进目前各种检测框架,提高性能
2. 在1的基础上,提出了一种特别的代替NMS的去重模块,可以避免NMS需要手动设置参数的问题
1. Background
假设现在有一个显示屏幕,问这是电脑显示屏还是电视屏幕,该怎么判断?如果单纯把屏幕取出来,确实很难回答这个问题,但是如果结合周围的东西,就很好解决了……比如,放在客厅环境、旁边有茶几的是电视,而旁边有键盘和鼠标的是电脑显示屏;又或者,宽度有沙发那么大的是电视,而只比一般座椅稍大一点的是电脑屏……
总之,周边其他物体的信息很可能对某个物体的分类定位有着帮助作用,这个作用在目前的使用RoI的网络中是体现不出来的,因为在第二阶段往往就把感兴趣的区域取出来单独进行分类定位了。这篇文章作者就考虑改良这个情况,来引入关联性信息。
放一个直观的例子,蓝色代表检测到的物体,橙色框和数值代表对该次检测有帮助的关联信息。 
实际上以往也有人尝试过类似的工作,但是由于关联性涉及到对其它物体特征和位置的假设等原因,一直不是个容易的问题,本文作者从google在NLP(https://arxiv.org/abs/1706.03762)方面的一篇论文中的Attention模块得到启发,设计了本文的这种思路。
2. Object Relation Module
这个模块的特点就是联合所有object的信息来提升每个object recognition的准确性。它的模块示意图如下图所示:



fR(n)fR(n)是第n个relation模块的输出,它是由各个所有物体的apperance特征经过WVWV的维数变化后,又赋予不同的权重叠加得到的……也许看到这里有人疑惑,不是说geometry特征也是输入吗,怎么没看到?其实位置特征是体现在权重里的,第m个物体对于当前第n个物体的权重ωmn的求法如下:


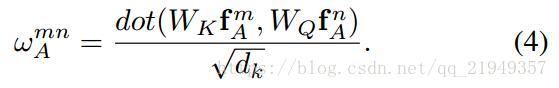


可以看出fg就是一维长度为4的向量,目标长度是dg=64。


改变为:

上面的N表示RPN选取出来的proposal的个数,比如300。
r1,r2代表重复次数,也可以用图来表示:

3. Duplicate removal
作者的另一个贡献就是提出了这种可以代替NMS的消除重复框的方法。框架如下: 


4. Experiment
这部分就不详细介绍了,作者主要使用了ResNet 50和101,用两个fc层作为baseline进行了很多对比实验。
包括:
- geometric feature特征的使用
- NrNr的数量
- relation modules的重复次数
- 效果的提升是源于relation module还是只是因为多加了几个层
- NMS和SoftNMS
- end2end和分阶段训练哪个更好
- 等等……
最终的实验结果:

5. Summary
本文主要是在detection当中引入了relation的信息,我个人觉得算是个很不错的切入点,而且motivation是源自NLP的,某种方面也说明了知识宽度的重要性。但是一个比较可惜的点就是,relation module更像是拍脑袋思考了一个方法然后直接去实验验证了,对于relation到底学到了什么,能不能更好地理解这个信息,作者认为这还是个有待解决的问题。期待在relation问题上能看到更多有趣的思路吧。
另外这种RM模块是在RPN选出proposal之后,就直接对这所有的框进行位置关系的计算,这是不合理的,毕竟你只和其中某些有关系,全都用上感觉就有点扯了(这当中可是有很多错误的框,而且也有很多重复的框),应该可以用的更好点的。
这个物体之间的关联的想法我认为是有效的,在作者已经做的实验的基础上再做改进,应该对检测精度是有帮助的。