源码:https://github.com/myfavouritekk/T-CNN
1 INTRODUCTION
近年来,随着新型深度卷积神经网络(CNN)[1],[2],[6],[7]和物体检测框架[3],[4],[5],[8]的成功,物体检测的性能得到显着提高。R-CNN [3]及其后继者[4],[5]等最先进的对象检测框架从区域提案中提取深度卷积特征,并将提案分类为不同的类别。DeepID-Net [8]通过引入box pre-training, cascade on region proposals,deformation layers and context representations来改进R-CNN。最近,ImageNet引入了一个新的挑战,视频(VID)中的对象检测,将对象检测带入视频领域。在这个挑战中,需要一个物体检测系统,在视频的每一帧中,使用边界框和类标签,自动注释属于30个类中每个对象,而测试视频没有预分配的额外信息,如用户标签(不懂)。 VID在视频分析方面有广泛的应用。
尽管它们对静态图像具有有效性,但这些静态图像对象检测框架并不是为视频而设计的。视频的一个关键因素是时间信息,因为视频中对象的位置和出现应该在时间上是一致的,即检测结果不应该在边界框位置和检测信息方面随时间发生巨大变化。然而,如果静态图像对象检测框架直接应用于视频,则对象的检测置信度显示出相邻帧之间的显着变化 和大的长期时间变化 ,如图1 (a) 中的示例所示。
提高时间一致性的一个直觉是将检测结果传播到邻近帧以减少检测结果的突然变化。如果在某个帧存在一个对象,相邻帧可能在相邻位置具有相似置信度的相同的对象。换句话说,检测结果可以根据运动信息传播到相邻帧,以便减少错误的检测。通过非极大值抑制(NMS)可以轻松地删除生成的重复框。
提高时间一致性的另一个直觉是对检测结果施加长期约束。如图 1(a)所示,一个物体的外边框序列的检测分数随着时间的推移有很大的波动。这些外边框序列或tubelets,可以通过跟踪和空间-时间对象提案算法[9]来生成。tubelet可以被视为应用长期约束的一个单元。某些正边界框的低检测置信度可能是由于运动模糊,不良姿势或在特定姿势下缺乏足够的训练样本造成的。因此,如果一个tubelet的大多数外边框具有较高的置信度检测分数,那么应该增加在某些帧中的低置信度得分以实现其长期一致性。
除了时间信息,与静态图像相比,上下文信息也是视频的关键要素。虽然已经研究了图像的上下文信息[8]并且被融入静态图像检测框架中,但是作为数百个图像的集合的视频,具有更丰富的上下文信息。如图1(b)所示,视频中的少量帧可能在一些背景对象上具有高置信度false positive。单帧内的上下文信息有时不足以区分这些false positive。然而,考虑到视频剪辑中的大部分高置信度检测结果,false positive可以被视为离群值,然后可以抑制其检测置信度。
本文的贡献是三重的。 1)我们提出了一个深度学习框架,扩展了流行的静态图像检测框架(R-CNN和Faster R-CNN),通过融合来自tubelet的时间和上下文信息来解决视频中的通用对象检测问题。它被称为T-CNN,即具有卷积神经网络的tubelet。 2)通过在相邻帧之间局部的传播检测结果,以及全面修改检测置信度和从跟踪算法生成的tubelet,时间信息被有效地纳入提出的检测框架。 3)根据视频剪辑中的所有检测结果,利用上下文信息来抑制低置信度类别的检测分数。该框架赢得具有提供的数据的VID任务,并在ILSVRC2015中实现了具有外部数据的第二名。代码在https://github.com/myfavouritekk/T-CNN。
2 RELATED WORK
Object detection from still images.
用于通用对象检测的最先进的方法主要基于深度CNN [1],[3],[4],[5],[8],[10],[11],[12] ],[13],[14],[15],[16],[17]。 Girshick等人[3]提出了一种称为R-CNN的多阶段流水线,用于训练深层CNN,以区分对象检测的区域提案。它将检测问题分解为包括边界框提案,CNN预训练,CNN微调,SVM训练和边界框回归等几个阶段。这种框架表现良好,被广泛应用于其他工作中。 Szegedy等人[1]提出了具有22层结构和“inception”模块的GoogLeNet,以取代R-CNN中的CNN,赢得了ILSVRC 2014对象检测任务。欧阳等[8]提出了a deformation constrained pooling layer and a box pre-training strategy,在ILSVRC 2014测试集上达到了50.3%的准确度。为了加快R-CNN pipeline的训练速度,提出了Fast R-CNN [4],其中每个图像块在被送入CNN之前不再被warp到固定大小。相反,相应的特征是从最后一个卷积层的输出特征图裁剪出来的。在Faster R-CNN pipeline[5]中,区域提案由RPN网络生成,整体框架可以以端到端的方式进行训练。所有这些方法都是用于从静态图像中检测物体。当他们以逐帧的方式直接应用于视频时,他们可能会漏掉一些正样本,因为对象可能不会在视频的某些帧上呈现最佳姿势。
Object localization in videos:
目前还有关于对象定位和共定位的研究[18],[19],[20],[21]。虽然这个任务似乎是类似的,但我们关注的VID任务实际上更具挑战性。两个问题之间有重大的区别。 1)目标:(co)localization问题假定每个视频包含只有一个已知(弱监督设置)或未知(无监督设置)类别,并且仅需要在每个测试帧中定位其中一个对象。然而,在VID中,每个视频帧包含未知数量的对象实例和类别。 VID任务更接近实际应用。 2)评价指标:localization metric(CorLoc [22])通常用于(co)定位中的评估,而mean average precision(mean AP)用于评估VID任务。鉴于上述差异,我们认为VID任务更困难,更接近现实情况。以前在视频中对象(co)localization的研究无法直接应用于VID。
Image classification.
由于大规模数据集[23]和新型深层神经网络[1],[2],[6],[24],图像分类的性能在过去几年得到了显着改善。对象检测的模型通常在ImageNet 1000类分类任务上进行预训练。 [7]提出了batch normalization层,以减少mini batch的统计变化,加快训练过程。 Simonyan等人提出了一种具有非常小的3×3卷积核的19层神经网络[2],在其他相关任务中被证明是有效的,如检测[4],[5],行为识别[25]和语义分割[26 ]。
Visual tracking.
对象跟踪已经研究了几十年[27],[28],[29]。最近,深度CNN已被用于对象跟踪,并获得令人印象深刻的跟踪精度。 Wang等[30]提出通过在线选择来自ImageNet预训练的CNN的最有影响力的特征来创建一个特定对象的跟踪器,该CNN的优势比现有最先进的跟踪器大得多。 Nam 等[31]训练了一个多领域的CNN,用于学习跟踪对象的通用表示。当跟踪新目标时,通过将预训练的CNN中的共享层与新的二分类层组合来创建新网络,该新的二分类层在线更新。跟踪显然与VID不同,因为它假定在第一帧中的对象的初始位置,并且不需要预测类别标签。
3 METHODS
在本节中,我们首先介绍VID任务设置(第3.1节)和我们的整体框架(第3.2节)。然后每个主要的组成部分将会被更详细的介绍。 3.3节介绍了静态图像检测器的设置。3.4节介绍如何利用多上下文信息来抑制false positive检测并利用运动信息来减少false negative。第3.5节介绍了global tubelet rescoring。
3.1 VID task setting
3.2 Framework overview
所提出的框架如图2所示。它由四个主要部分组成:1)静态图像检测,2)多上下文抑制和motion-guided传播,3)temporal tubelet re-scoring ,以及4)模型组合。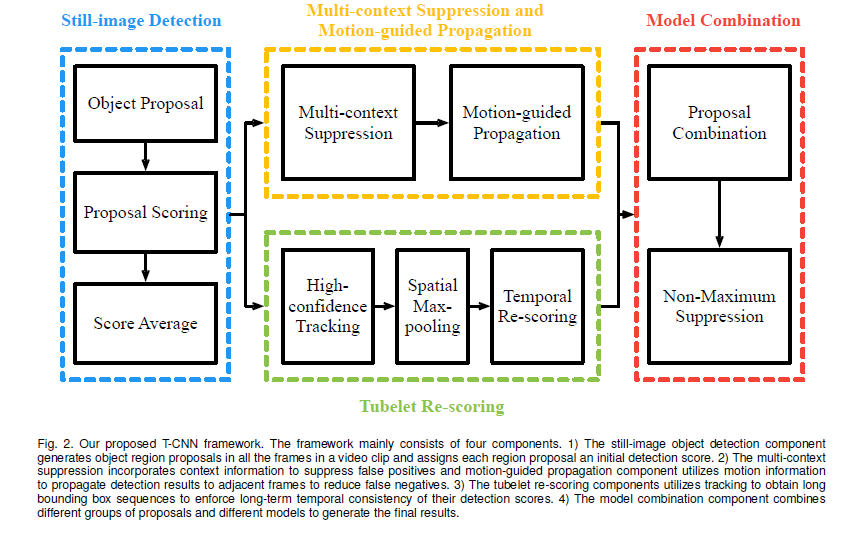
Multi-context suppression.
Motion-guided Propagation.
在静态图像对象检测中,在相邻帧中检测到的对象,在某些帧时可能会丢失某些对象。 运动引导传播使用诸如光流的运动信息来将检测结果局部地传播到相邻帧以减少false negative。Temporal tubelet re-scoring.
从静态图像检测器的高置信度检测开始,我们首先运行跟踪算法来获得边界框序列,我们称之为tubelet。 然后根据其检测分数的统计,将tubelet分为pisitive和negative样本。 positive分数映射到较高的范围,而negative值则映射到较低的范围,从而提高分数裕量。Model combination:
对于来自DeepID-Net和CRAFT的两组提案中的每一个,它们的来自于tubelet rescoring和运动引导传播的检测结果,每个最小 - 最大映射到[0,1],并通过与 IOU重叠0.5NMS的过程以获得最终结果。3.3 Still-image object detectors
我们的静态图像对象检测器采用DeepIDNet [8]和CRAFT [32]。两个检测器具有不同的区域提案方法,预训练模型和训练策略。3.3.1 DeepID-Net
Object region proposals. 对于DeepID-Net,通过selective search(SS)[33],Edge Boxes(EB)[34]和级联选择过程获得对象区域提案,该过程消除了使用ImageNet预训练的AlexNet [24]模型的简单false positive boxes。所有提案框然后被预先训练的AlexNet标记为200 ImageNet检测类分数。所有200类的最大预测分数低于阈值的框被认为是容易的负样本,并被消除。该过程消除了大约94%的提案框,同时获得了大约90%的召回率。预先训练的模型。 ILSVRC 2015有两个轨道任务。 1)对于提供的数据跟踪,可以使用所有ILSVRC 2015数据集的数据和注释,包括分类和定位(CLS),DET,VID和Places2。2)对于外部数据轨道,可以使用附加数据和注释。
对于所提供的数据轨道,我们使用CLS 1000类数据预处理了使用批处理标准化(BN)[7]的VGG [2]和GoogLeNet [1],而对于外部数据轨道,我们使用了ImageNet 3000类数据。预培训在对象级注解中完成,如[8]而不是R-CNN中的图像级注释[3]。
模型飞行和SVM训练。由于VID中的类是DET类的一个子集,所以DET预先保存的网络和SVM可以直接应用于VID任务,具有正确的类索引映射。然而,由于DET和VID数据分布的不匹配以及视频中的唯一统计信息,DET训练的模型对于VID任务可能不是最佳的。因此,我们对网络进行了优化,并结合DET和VID数据重新训练了30个SVM。研究不同的组合配置,并且2:1 DET到VID数据比达到了
最佳性能(见第4.2节)。
得分平均。针对DeepID-Net框架分别对多个CNN和SVM模型进行了训练,将其结果平均以产生检测分数。这种得分平均过程以贪婪的搜索方式进行。
最好的单一模型是首选。然后对于每个剩余的模型,其检测分数与所选模型的检测得分平均,并且选择具有最佳性能的模型作为第二选择的模型。该过程重复,直到没有观察到显着的改善。
参考:
[1]https://blog.csdn.net/xiaofei0801/article/details/72867829