一 线性回归原理
这部分相对来说比较简单,不理解的可以参考:
http://blog.csdn.net/xuxiatian/article/details/55002412
二 代码实现
1.简单的实现
根据公式:
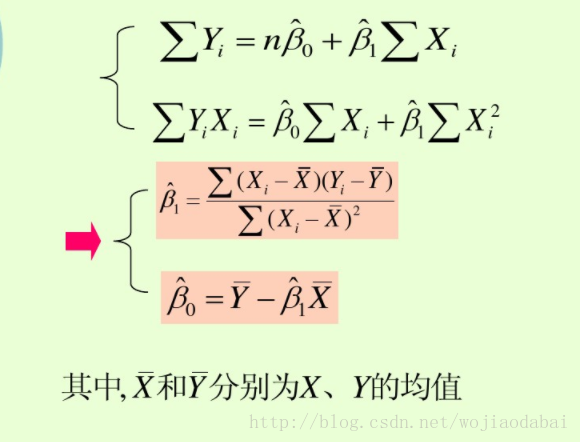
import numpy as np
import matplotlib.pyplot as plt
def firstLR(x,y):
n=len(x)
dinominator=0
numerator=0
for i in range(0,n):
numerator +=(x[i]-np.mean(x))*(y[i]-np.mean(y))
dinominator +=(x[i]-np.mean(x))**2
print('numerator',numerator)
print('dinominator',dinominator)
b1=numerator/float(dinominator)
b0=np.mean(y)/float(np.mean(x))
return b0,b1
x=[1,3,2,1,3]
y=[14,24,18,17,27]
b0,b1=firstLR(x,y)
print('intercept:',b0,'slope:',b1)
## 直线方程
b=range(1,6)
a=b1*b+b0
#可视化
plt.figure()
ax=plt.subplot(212)
ax.scatter(x,y,c='red',s=20,marker='*')
plt.plot(b,a)
plt.show()
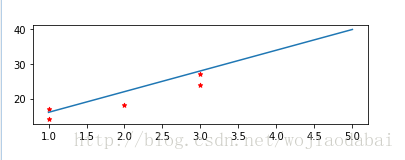
这是以预测为主,并没有检验参数的有效性,也没有计算损失函数。
2.利用 sklearn
import pandas as pd
import numpy as pd
x=np.array([[1],[3],[2],[1],[3]])y=np.array([[14],[24],[18],[17],[27]])
from sklearn.linear_model import LinearRegression
linreg = LinearRegression()
model=linreg.fit(x,y)
print(model)
print(linreg.intercept_)
print(linreg.coef_)

3.统计模块 statsmodels做回归
import pandas as pd
import numy as np
import statsmodels.api as sm
x=sm.add_constant(x)
e=np.random.normal(size=len(x))#添加随机扰动项
beta=np.array([1,10])
y=np.dot(x,beta)+e #dot 是乘 的意思
model=sm.OLS(y,x)
results=model.fit()
print(results.params)
print(results.summary())
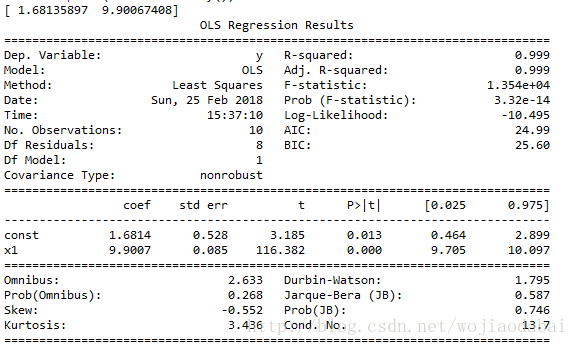
正规的统计表,可以对系数做显著性检验,P值较大,都不合格,不过是以预测为主,都没关系啦。