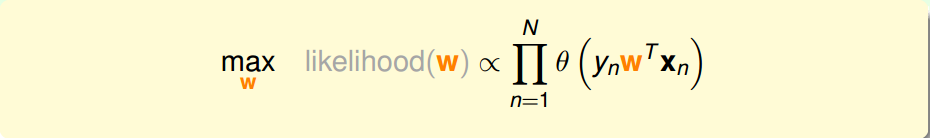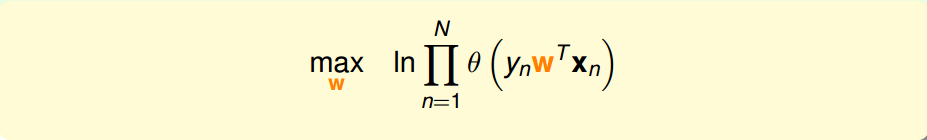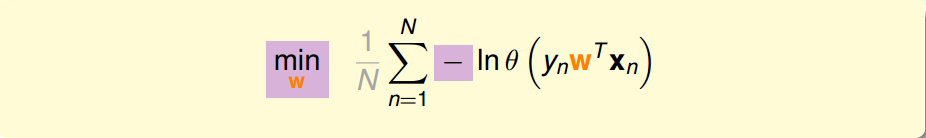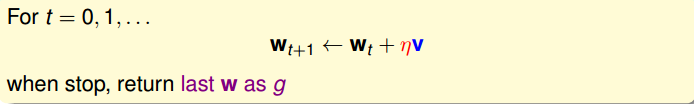版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_35564813/article/details/84394684
之前提过的二元分类器如PLA,其目标函数为,
f
(
x
)
=
s
i
g
n
(
w
T
x
)
∈
−
1
,
+
1
f(x)=sign(w^Tx)∈{−1,+1}
f ( x ) = s i g n ( w T x ) ∈ − 1 , + 1
f
(
x
)
=
P
(
+
1
∣
x
)
∈
[
0
,
1
]
f(x)=P(+1|x)∈[0,1]
f ( x ) = P ( + 1 ∣ x ) ∈ [ 0 , 1 ]
Logistic Regression use:
h
(
x
)
=
1
1
+
e
x
p
(
−
w
T
x
)
∈
[
0
,
1
]
h(x)=\frac{1}{1+exp(-w^Tx)}∈[0,1]
h ( x ) = 1 + e x p ( − w T x ) 1 ∈ [ 0 , 1 ]
之前我们讲到Linear Regression所使用的平方误差,那么Logistic可以使用平方误差吗?当然可以,但是使用平方误差不够好。
如果使用平方误差,每个点产生的误差是:
$Tx)-(0)) 2, & y_n=0\Tx)) 2, & y_n=1
=
y
n
(
1
−
θ
(
w
T
x
)
)
2
+
(
1
−
y
n
)
(
θ
(
w
T
x
)
)
2
=y_n(1-\theta(w^Tx))^2+(1-y_n)(\theta(w^Tx))^2
= y n ( 1 − θ ( w T x ) ) 2 + ( 1 − y n ) ( θ ( w T x ) ) 2
此时cost function,
E
i
n
(
w
)
=
∑
e
r
r
E_{in}(w)=\sum err
E i n ( w ) = ∑ e r r
f
(
x
)
=
P
(
+
1
∣
x
)
f(x)=P(+1|x)
f ( x ) = P ( + 1 ∣ x )
Logistic Regression的目标函数的输出是,在已知x的条件下,y=+1的概率,因此在已知x的条件下,y=+1的概率是f(x),y=−1的概率是1−f(x):
$
g
=
a
r
g
m
a
x
h
l
i
k
e
h
o
o
d
(
h
)
g=argmax_h \ likehood(h)
g = a r g m a x h l i k e h o o d ( h )
当h是logistic函数的时候,即
h
(
x
)
=
θ
(
w
T
x
)
h(x)=θ(w^Tx)
h ( x ) = θ ( w T x )
所以:
$
因为
P
(
x
n
)
P(x_n)
P ( x n )
h
(
y
n
)
h(y_n)
h ( y n )
如果将w带入的话:
有了误差函数后,我们就可以定出cost function:
E
i
n
(
w
)
=
1
N
∑
n
=
1
N
l
n
(
1
+
e
x
p
(
−
y
n
w
T
x
n
)
)
E_{in}(w)=\frac{1}{N}\sum^N_{n=1}ln(1+exp(-y_nw^Tx_n))
E i n ( w ) = N 1 ∑ n = 1 N l n ( 1 + e x p ( − y n w T x n ) )
既然是凸函数,我们可以根据之前线性回归的例子,如果我们能解出一阶微分(梯度)为0的点,这个问题就可以解决了。
x
n
,
i
x_{n,i}
x n , i
E
i
n
(
w
)
E_{in}(w)
E i n ( w )
∇
E
i
n
(
w
)
=
1
N
∑
n
=
1
N
θ
(
−
y
n
w
T
x
n
)
(
−
y
n
x
n
)
\nabla E_{in}(w)=\frac{1}{N}\sum^N_{n=1}\theta(−y_nw^Tx_n)(−y_nx_n)
∇ E i n ( w ) = N 1 ∑ n = 1 N θ ( − y n w T x n ) ( − y n x n )
和之前的线性回归不同,它不是一个线性的式子,要让
∇
E
i
n
(
w
)
=
0
\nabla E_{in}(w)=0
∇ E i n ( w ) = 0
θ
(
)
\theta()
θ ( )
y
n
w
T
x
n
≫
0
y_nw^Tx_n\gg0
y n w T x n ≫ 0
y
n
y_n
y n
w
T
x
n
w^Tx_n
w T x n
但是相对来说,保证所有的权重
θ
(
−
y
n
w
T
x
n
)
\theta(-y_nw^Tx_n)
θ ( − y n w T x n )
我们尝试从PLA中找到些许灵感:
y
n
x
n
y_nx_n
y n x n
根据上一小节PLA的思想,那么:
E
i
n
(
w
)
E_{in}(w)
E i n ( w )
E
i
n
(
w
)
E_{in}(w)
E i n ( w )
E
i
n
(
w
t
+
η
v
)
≃
E
i
n
(
w
t
)
+
η
v
T
∇
E
i
n
(
w
t
)
E_{in}(w_t+\eta v)\simeq E_{in}(w_t)+\eta v^T\nabla E_{in}(w_t)
E i n ( w t + η v ) ≃ E i n ( w t ) + η v T ∇ E i n ( w t )
至于泰勒展开(矩阵形式):
f
(
x
)
=
f
(
x
k
)
+
[
∇
f
(
x
k
)
]
T
(
x
−
x
k
)
+
1
2
!
[
x
−
x
k
]
T
H
(
x
k
)
[
x
−
x
k
]
+
o
n
f(x)=f(x_k)+[\nabla f(x_k)]^T(x-x_k)+\frac{1}{2!}[x-x_k]^TH(x_k)[x-x_k]+o^n
f ( x ) = f ( x k ) + [ ∇ f ( x k ) ] T ( x − x k ) + 2 ! 1 [ x − x k ] T H ( x k ) [ x − x k ] + o n
迭代的目的就是让
E
i
n
E_{in}
E i n
E
i
n
(
w
t
+
η
v
)
<
E
i
n
(
w
t
)
E_{in}(w_t+\eta v)<E_{in}(w_t)
E i n ( w t + η v ) < E i n ( w t )
η
\eta
η
∇
E
i
n
(
w
t
)
\nabla E_{in}(w_t)
∇ E i n ( w t )
E
i
n
(
w
t
+
η
v
)
<
E
i
n
(
w
t
)
E_{in}(w_t+\eta v)<E_{in}(w_t)
E i n ( w t + η v ) < E i n ( w t )
v
=
∇
E
i
n
(
w
t
)
∣
∣
∇
E
i
n
(
w
t
)
∣
∣
v=\frac{\nabla E_{in}(w_t)}{||\nabla E_{in}(w_t)||}
v = ∣ ∣ ∇ E i n ( w t ) ∣ ∣ ∇ E i n ( w t )
那么每次迭代的公式就可以写出:
w
t
+
1
←
w
t
−
η
∇
E
i
n
(
w
t
)
∣
∣
∇
E
i
n
(
w
t
)
∣
∣
w_{t+1}\leftarrow w_t-\eta\frac{\nabla E_{in}(w_t)}{||\nabla E_{in}(w_t)||}
w t + 1 ← w t − η ∣ ∣ ∇ E i n ( w t ) ∣ ∣ ∇ E i n ( w t )
步长η比较难决定,太小了,更新太慢,太大了,容易矫枉过正:
η
\eta
η
∣
∣
∇
E
i
n
(
w
t
)
∣
∣
||\nabla E_{in}(w_t)||
∣ ∣ ∇ E i n ( w t ) ∣ ∣
∣
∣
∇
E
i
n
(
w
t
)
∣
∣
||\nabla E_{in}(w_t)||
∣ ∣ ∇ E i n ( w t ) ∣ ∣
η
′
\eta'
η ′
w
t
+
1
←
w
t
−
η
∇
E
i
n
(
w
t
)
∣
∣
∇
E
i
n
(
w
t
)
∣
∣
w_{t+1}\leftarrow w_t-\eta\frac{\nabla E_{in}(w_t)}{||\nabla E_{in}(w_t)||}
w t + 1 ← w t − η ∣ ∣ ∇ E i n ( w t ) ∣ ∣ ∇ E i n ( w t )
∥
\Vert
∥
w
t
−
η
′
∇
E
i
n
(
w
t
)
w_t-\eta' \nabla E_{in}(w_t)
w t − η ′ ∇ E i n ( w t )
我们称这个
η
′
\eta'
η ′
整个步骤是这样的:
initialize w0
for t=0,1,…
1.compute
∇
E
i
n
(
w
)
=
1
N
∑
n
=
1
N
θ
(
−
y
n
w
T
x
n
)
(
−
y
n
x
n
)
\nabla E_{in}(w)=\frac{1}{N}\sum_{n=1}^N\theta(-y_nw^Tx_n)(-y_nx_n)
∇ E i n ( w ) = N 1 ∑ n = 1 N θ ( − y n w T x n ) ( − y n x n )
2.update by
w
t
−
η
∇
E
i
n
(
w
t
)
w_t-\eta\nabla E_{in}(w_t)
w t − η ∇ E i n ( w t )
…until
E
i
n
(
w
t
+
1
)
=
0
E_{in}(w_{t+1})=0
E i n ( w t + 1 ) = 0
return last
w
t
+
1
w_{t+1}
w t + 1
今天介绍了逻辑回归。首先指出逻辑回归将P(+1|x)作为目标函数,将
θ
(
w
T
x
)
\theta(w^Tx)
θ ( w T x )
E
i
n
E_{in}
E i n