Hazard of Overfitting
What is Overfitting
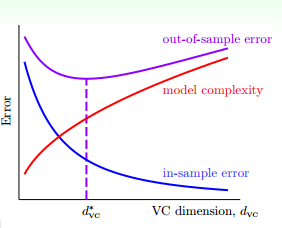
hypothesis的阶数越高,表示VC Dimension越大。随着VC Dimension增大,
是一直减小的,而
先减小后增大。在
位置,
取得最小值。在
右侧,随着VC Dimension越来越大,
越来越小,接近于0,
越来越大。即当VC Dimension很大的时候,这种对训练样本拟合过分好的情况称之为过拟合(overfitting)。另一方面,在
左侧,随着VC Dimension越来越小,
和
都越来越大,这种情况称之为欠拟合(underfitting),即模型对训练样本的拟合度太差,VC Dimension太小了。

bad generation和overfitting的关系可以理解为:overfitting是VC Dimension过大的一个过程,bad generalization是overfitting的结果。
The Role of Noise and DataSize
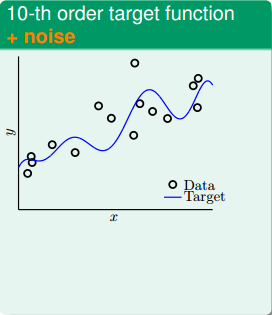
首先,在二维平面上,一个模型的分布由目标函数f(x)(x的10阶多项式)加上一些noise构成,下图中,离散的圆圈是数据集,目标函数是蓝色的曲线。数据没有完全落在曲线上,是因为加入了noise。
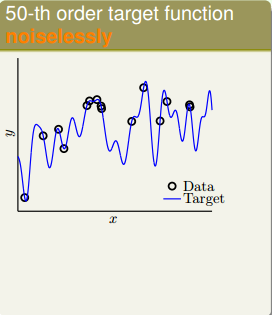
然后,同样在二维平面上,另一个模型的分布由目标函数f(x)(x的50阶多项式)构成,没有加入noise。下图中,离散的圆圈是数据集,目标函数是蓝色的曲线。可以看出由于没有noise,数据集完全落在曲线上。
然后我们分别用一个2阶多项式和10阶多项式来对上面两个数据集进行拟合,然后对于第一个数据集,产生了如下效果:
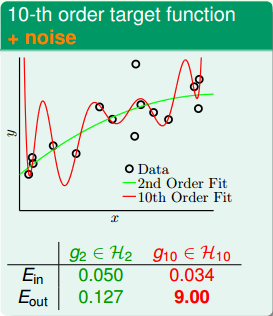
可以看出虽然10阶多项式的
更好,但是
比较大了。
然后对于第二个数据集来说:
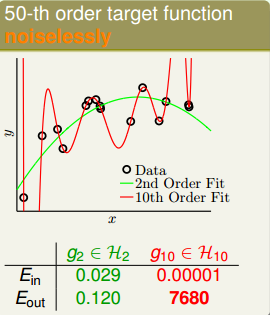
虽然10阶多项式的
变得非常小,但是
变得却非常大。

上面两个问题中,10阶模型都发生了过拟合,反而2阶的模型却表现得相对不错。这好像违背了我们的第一感觉,比如对于目标函数是10阶多项式,加上noise的模型,按道理来说应该是10阶的模型更能接近于目标函数,因为它们阶数相同。但是,事实却是2阶模型泛化能力更强。这种现象产生的原因,从哲学上来说,就是“以退为进”。有时候,简单的学习模型反而能表现的更好。
从上图可以看出,对于数据量不够大的时候,2阶多项式的表现好于10阶多项式,泛化能力更好
另一个例子中,目标函数是50阶多项式,且没有加入noise。这种情况下,我们发现仍然是2阶的模型拟合的效果更好一些,明明没有noise,为什么是这样的结果呢?
实际上,我们忽略了一个问题:这种情况真的没有noise吗?其实,当模型很复杂的时候,即50阶多项式的目标函数,无论是2阶模型还是10阶模型,都不能学习的很好,这种复杂度本身就会引入一种‘noise’。所以,这种高阶无noise的问题,也可以类似于10阶多项式的目标函数加上noise的情况,只是二者的noise有些许不同,下面一部分将会详细解释。
Deterministic Noise

上图中,红色越深,代表overfit程度越高,蓝色越深,代表overfit程度越低。先看左边的图,左图中阶数 固定为20,横坐标代表样本数量N,纵坐标代表噪声水平 。红色区域集中在N很小或者 很大的时候,也就是说N越大, 越小,越不容易发生overfit。右边图中 ,横坐标代表样本数量N,纵坐标代表目标函数阶数 。红色区域集中在N很小或者 很大的时候,也就是说N越大, 越小,越不容易发生overfit。上面两图基本相似。
从上面的分析,我们发现 对overfit是有很大的影响的,我们把这种noise称之为stochastic noise。同样地, 即模型复杂度也对overfit有很大影响,而且二者影响是相似的,所以我们把这种称之为deterministic noise。之所以把它称为noise,是因为模型高复杂度带来的影响。
总结一下,有四个因素会导致发生overfitting:
-
data size N ↓
-
stochastic noise ↑
-
deterministic noise ↑
-
excessive power ↑
我们刚才解释了如果目标函数f(x)的复杂度很高的时候,那么跟有noise也没有什么两样。因为目标函数很复杂,那么再好的hypothesis都会跟它有一些差距,我们把这种差距称之为deterministic noise。deterministic noise与stochastic noise不同,但是效果一样。其实deterministic noise类似于一个伪随机数发生器,它不会产生真正的随机数,而只产生伪随机数。它的值与hypothesis有关,且固定点x的deterministic noise值是固定的。
Dealing with Overfitting
避免overfitting的方法主要包括:
- start from simple model
- data cleaning/pruning
- data hinting
- regularization
- validataion
data cleaning/pruning就是对训练数据集里label明显错误的样本进行修正(data cleaning),或者对错误的样本看成是noise,进行剔除(data pruning)。
data hinting是针对N不够大的情况,如果没有办法获得更多的训练集,那么data hinting就可以对已知的样本进行简单的处理、变换,从而获得更多的样本。举个例子,数字分类问题,可以对已知的数字图片进行轻微的平移或者旋转,从而让N丰富起来,达到扩大训练集的目的。这种额外获得的例子称之为virtual examples。但是要注意一点的就是,新获取的virtual examples可能不再是iid某个distribution。所以新构建的virtual examples要尽量合理,且是独立同分布的。
总结
过拟合的表现就是 很小, 很大。过拟合可能会因为噪声,数据量,过大的多项式拟合导致的。同时解决过拟合的方法也有很多,主要有start from simple model、data cleaning/pruning、data hinting、regularization、validataion等方法。