版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/asasasaababab/article/details/82314124
本周主要讲的是大规模的机器学习。其实里边很多内容在deeplearning.ai里边都讲过了。所以这里就把之前没有的部分做个总结。
大规模数据的意义
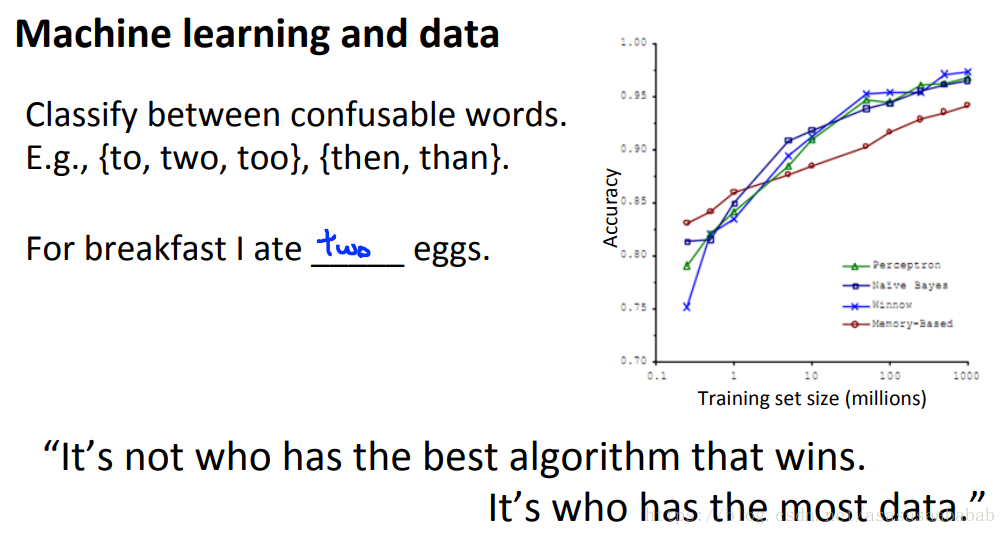
Banko and Brill, 2001发表的一个文章发现,只要数据规模变大,那么很多的算法表现得都很好。所以其实数据是机器学习里边非常重要的一个部分。
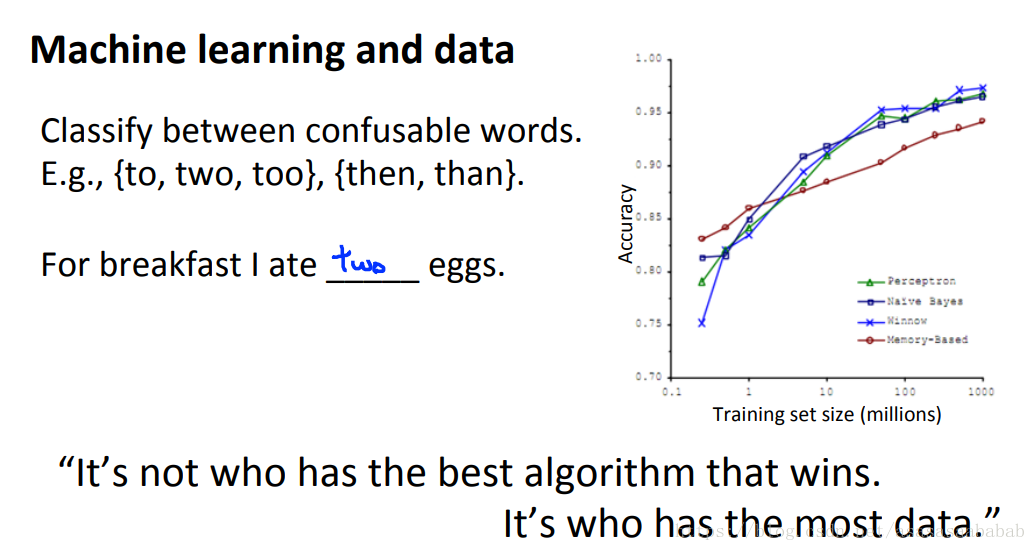
但是呢,这个argument成立的前提条件是所选的算法是一个bias很小的算法。画出learning curve就能看到了:
Batch GD, SGD, mini-batch GD
这块之前都讲过了。就补充一个要点就可以了。
有的时候可能因为对cost平均的比较少,导致看不出来是不是在下降,所以可以采用把cost平均的多一些,这样可以看出来有没有在下降。
Online Learning
案例和挑战
- 我们经营一个运输公司,每天都会有人来询问从A到B点多少钱,时间之类的。然后我们报价之后,会得到一个结果,他们愿意使用还是不愿使用。 是用户特征和服务价格等。 是结果,我们希望了解 ,也就是logistic regression。问题是,每天都有这个询价,也就是有数据集增加,我们应该怎么办呢?
- 产品搜索。假如我们经营一家销售平台,类似Amazon把,用户搜索1080p 安卓手机,我们从100条结果里边给他10条。然后他有可能click其中一个。每天都有这个行为,也就是 的时候发生了click事件。我们希望利用每天的数据流对模型进行训练,怎么办?
这些应用场景都有一个问题是,就是数据是以流的方式进来,不断更新,如果我们保存起来,那么数量会非常巨大。
解决问题的方法

当数据量非常大的时候,其实就可以这样一直repeat forever,然后拿一个新的数据来GD一下。然后这个数据其实就可以丢了。
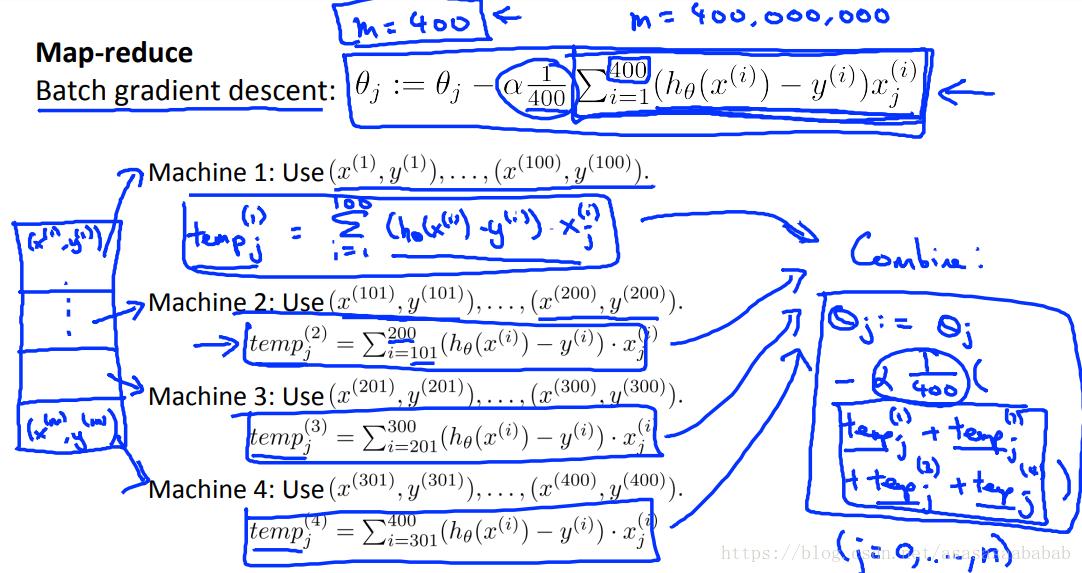
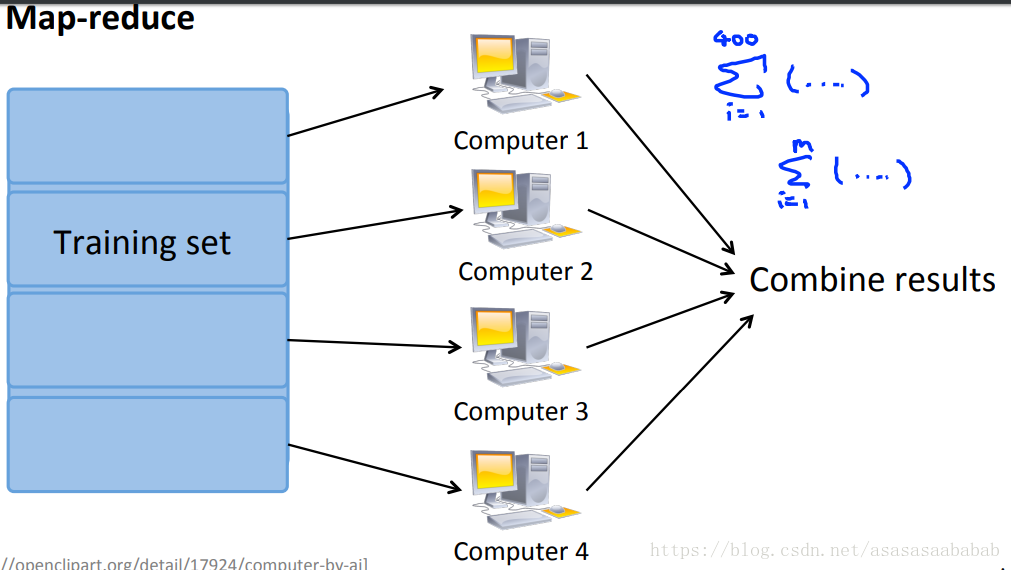
Map Reduce
大数据带来的挑战
其实就是数据非常大,导致一个电脑可能放不下,运算不过来。
解决方法
如果问题能够拆解成几个小规模的问题,分配给几个核心,或者几个电脑,那么就可以划分之后,给几个电脑分别做,然后再汇总。