Three Learning Principles
Occam‘s Razor
奥卡姆剃刀原则:如无必要勿增实体。
对这个原则的理解相当于是说,在机器学习里最简单的能够解释数据的模型就是最合理的模型。但是有两个问题,怎么知道一个模型是比较简单的?以及,怎么确定更简单的模型就是更好的?
一个简单的hypothesis看起来比较简单,一般是意味着有比较少的参数。而一个模型比较简单意味着它包含的hypothesis的数量比较小。这两个事情之间有着一定的联系,因为模型包含更少的hypothesis意味着hypothesis可以用更少的bit来表示,因此更小的模型复杂度会带来更简单的hypothesis。

所以,为了让模型简单化,我们可以一开始就选择简单的model,或者用regularization,让hypothesis中参数个数减少,都能降低模型复杂度。
那为什么简单的模型就是好的呢?下面从哲学的角度简单解释一下。机器学习的目的是“找规律”,即分析数据的特征,总结出规律性的东西出来。假设现在有一堆没有规律的杂乱的数据需要分类,要找到一个模型,让它的 ,是很难的,大部分时候都无法正确分类,但是如果是很复杂的模型,也有可能将其分开。反过来说,如果有另一组数据,如果可以比较容易找到一个模型能完美地把数据分开,那表明数据本身应该是有某种规律性。也就是说杂乱的数据应该不可以分开,能够分开的数据应该不是杂乱的。如果使用某种简单的模型就可以将数据分开,那表明数据本身应该符合某种规律性。相反地,如果用很复杂的模型将数据分开,并不能保证数据本身有规律性存在,也有可能是杂乱的数据,因为无论是有规律数据还是杂乱数据,复杂模型都能分开。这就不是机器学习模型解决的内容了。所以,模型选择中,我们应该尽量先选择简单模型,例如最简单的线性模型。
Sampling Bias
首先引入一个有趣的例子:1948年美国总统大选的两位热门候选人是Truman和Dewey。一家报纸通过电话采访,统计人们把选票投给了Truman还是Dewey。经过大量的电话统计显示,投给Dewey的票数要比投个Truman的票数多,所以这家报纸就在选举结果还没公布之前,信心满满地发表了“Dewey Defeats Truman”的报纸头版,认为Dewey肯定赢了。但是大选结果公布后,让这家报纸大跌眼镜,最终Truman赢的了大选的胜利。
为什么会出现跟电话统计完全相反的结果呢?是因为电话统计数据出错还是投票运气不好?都不是。其实是因为当时电话比较贵,有电话的家庭比较少,而正好是有电话的美国人支持Dewey的比较多,而没有电话的支持Truman比较多。也就是说样本选择偏向于有钱人那边,可能不具有广泛的代表性,才造成Dewey支持率更多的假象。
这个例子表明,抽样的样本会影响到结果,用一句话表示“If the data is sampled in a biased way, learning will produce a similarly biased outcome.”意思是,如果抽样有偏差的话,那么学习的结果也产生了偏差,这种情形称之为抽样偏差Sampling Bias。
从技术上来说,就是训练数据和验证数据要服从同一个分布,最好都是独立同分布的,这样训练得到的模型才能更好地具有代表性。
Data Snooping
之前的课程,我们介绍过在模型选择时应该尽量避免偷窥数据,因为这样会使我们人为地倾向于某种模型,而不是根据数据进行随机选择。所以,Φ应该自由选取,最好不要偷窥到原始数据,这会影响我们的判断。
事实上,数据偷窥发生的情况有很多,不仅仅指我们看到了原始数据。什么意思呢?其实,当你在使用这些数据的任何过程,都是间接地偷看到了数据本身,然后你会进行一些模型的选择或者决策,这就增加了许多的model complexity,也就是引入了污染。
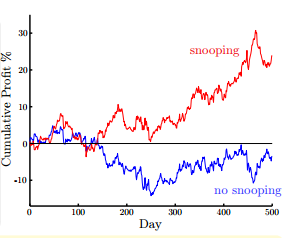
如图所示,我们现在有两种训练模型的方法,一种是使用前6年的数据,后两年作为测试,图中蓝色曲线表示后两年的收益;另一种是使用8年的数据来进行训练,图中红色曲线表示后两年的收益。很明显,利用8年数据进行训练能达到的收益更多,但是明显这是自欺欺人的做法,因为我们本身已经偷窥了后两年的数据,这样进行预测肯定可以获得较大的收益。

而对于数据的重复使用也会导致这个问题。比如对一个公开数据集的连续使用进而选择模型,无形中会存在一个联合的过程,也就导致了最终的模型复杂度会很大。也就是说一直用一个数据会导致效果可能会很好,但不一定能代表真实情况。

为了解决这个问题,需要做到以下的几点:

Power of Three
首先介绍了跟机器学习相关的三个领域:

然后介绍了三个理论保证:

然后介绍了三个线性模型:

同时我们介绍了三个重要的工具:
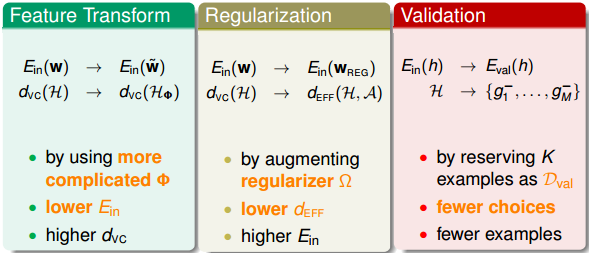
还有我们本节课介绍的三个锦囊妙计:

最后,我们未来机器学习的方向也分为三种:

总结
本节课主要介绍了机器学习三个重要的锦囊妙计:Occam’s Razor, Sampling Bias, Data Snooping。并对《机器学习基石》课程中介绍的所有知识和方法进行“三的威力”这种形式的概括与总结,“三的威力”也就构成了坚固的机器学习基石。