文章目录
Lecture 4: Feasibility of Learning
Learning is Impossible?
absolutely no free lunch outside
No Free Lunch
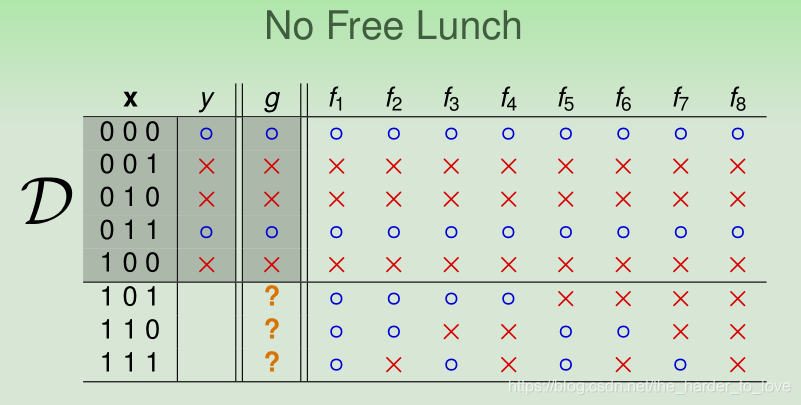
在已知的样本( )中, 都符合( ),但不同的f所预测的y完全不同。
你不能说这八个模型中谁比谁好,也就是说这八个模型预测都是对的,
Fun Time
This is a popular ‘brain-storming’ problem, with a claim that 2% of the world’s cleverest population can crack its ‘hidden pattern’.
It is like a ‘learning problem’ with
.
Learn a hypothesis from the one example to predict on x = (7,2,5).
What is your answer?
1 151026
2 143547
3 I need more examples to get the correct answer
4 there is no ‘correct’ answer
Explanation
根据“没有免费的午餐”,我们根据有限的输入,理论上在输入外可以得到一定数量的等价模型。
所以输入越多,归纳得到的规律
就越靠近
。
但是实际上我们永远得不到g,除非你拥有所有的样本(但如果你拥有所有的样本,直接对比查询即可,用不着用模型模拟了)或者加上其他的条件/倾向。
? 所以说数列要写通项公式才规范,小时候写的数学规律题目其实都不严谨,因为我发现一道填空题可能有多个答案,而标准答案往往只给一个。
Probability to the Rescue
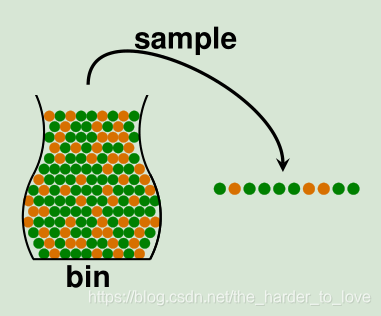
我们使用统计学与概率论工具,用已知样本的分布预估未知样本的分布。简单来说类似于抽样检测(实际上我们所做的相反:用样本估计整体),如下图所示。
Hoeffding’s Inequality
In big sample (
large),
is probably close to
(within
)
for marbles, coin, polling, …
概率上界的大小取决于宽松间隙(
)和样本数量(
),两者越大,概率上界就越小。
,概率最大,接近1.
越大,越有可能用
推测
Fun Time
Let
= 0.4. Use Hoeffding’s Inequality
to bound the probability that a sample of 10 marbles will have
. What bound do you get?
1 0.67
2 0.40
3 0.33
4 0.05
Explanation
? 霍夫丁不等式告诉了数据之间差距的概率上界,若知道数据的概率分布(概率密度函数|分布列),可积分直接求出概率。
霍夫丁不等式是统计学和概率论中最重要的几个定理之一。
Connection to Learning
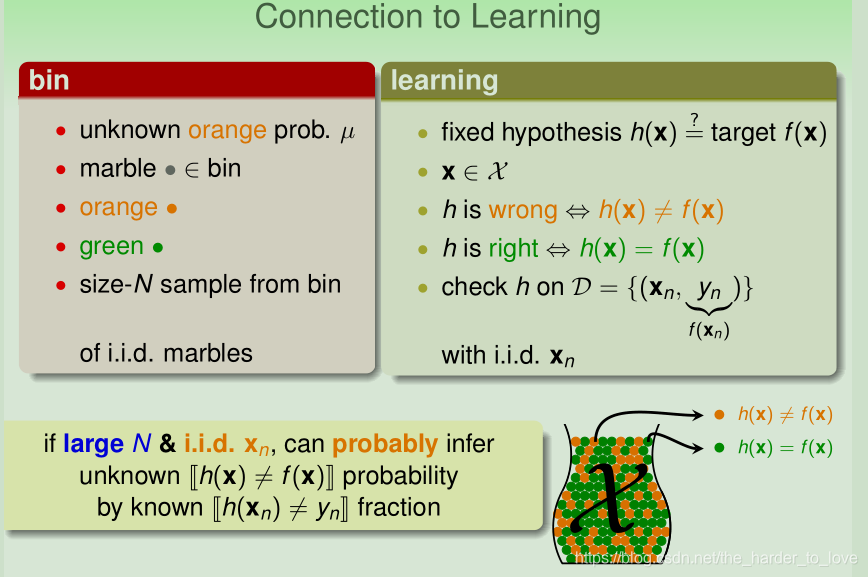
如果 足够大,我们可以用 (in-sample error)来估计 (out-sample error)。
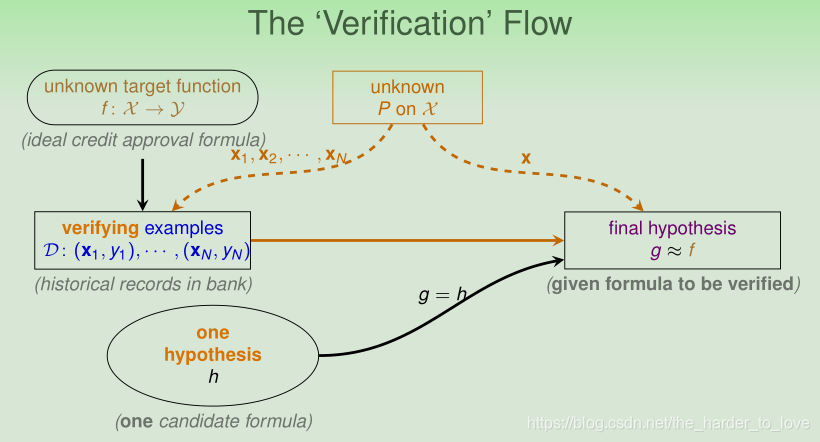
Fun Time
Your friend tells you her secret rule in investing in a particular stock: ‘Whenever the stock goes down in the morning, it will go up in the afternoon;vice versa.’
To verify the rule, you chose 100 days uniformly at random from the past 10 years of stock data, and found that 80 of them satisfy the rule.
What is the best guarantee that you can get from the verification?
1 You’ll definitely be rich by exploiting the rule in the next 100 days.
2 You’ll likely be rich by exploiting the rule in the next 100 days, if the market behaves similarly to the last 10 years.
3 You’ll likely be rich by exploiting the ‘best rule’ from 20 more friends in the next 100 days.
4 You’d definitely have been rich if you had exploited the rule in the past 10 years.
Explanation
股票市场风云变幻,你用历史数据搭建了一个优秀的模型当且仅当未来的趋势跟历史发展一致时,你才能利用这个模型获益。
从霍夫丁不等式的角度来看:历史数据搭建了一个优秀的模型(
), 且未来的趋势跟历史发展一致时
,那么模型对于未来趋势预测的效果优秀(
),你最终就能获益。
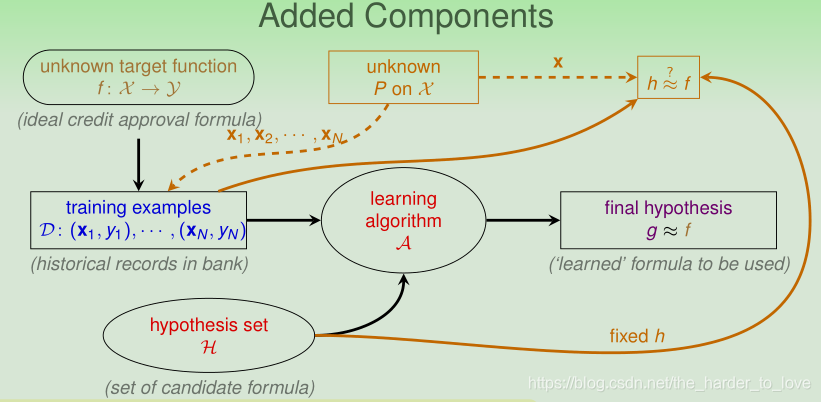
Connection to Real Learning
之前是验证1个假设,别忘了,我们的假设集有多个假设,来看看真实的学习环境下,霍夫丁不等式应用的改变。
Multiple h
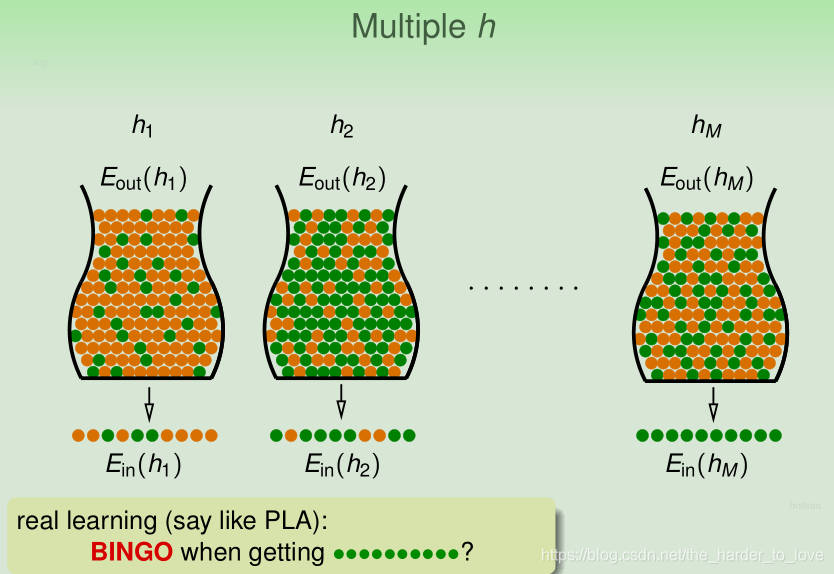
假设现在有150名同学,每人抛五次硬币,问出现连续朝上五枚硬币的概率是多少?
由于同学数量高达150名,出现连续朝上五枚硬币的概率达到
,倘若我们用硬币全部朝上的数据而选择一直猜硬币朝上,
and
BAD Sample and BAD Data
由于假设集增多,极端数据出现的可能性增大,由于我们的选择,导致 and 差别过大,我们将这样的选择称为 .
big (far from ), but small (correct on most examples) called BAD Data.
![[BAD Data for Many h]](https://img-blog.csdnimg.cn/20190420111631116.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3RoZV9oYXJkZXJfdG9fbG92ZQ==,size_16,color_FFFFFF,t_70)
$$ \begin{aligned} \ \mathbb{P}_{\mathcal{D}}[\mathrm{BAD} \ \mathcal{D}] & = \mathbb{P}_{\mathcal{D}}[\mathrm{BAD} \ \mathcal{D} \ for \ h_1 \ or \ \mathrm{BAD} \ \mathcal{D} \ for \ h_2 \ or \ ... \ or \ \mathrm{BAD} \ \mathcal{D} \ for \ h_M] \\ \ & \le \mathbb{P}_{\mathcal{D}}[\mathrm{BAD} \ \mathcal{D} \ for \ h_1]+\mathbb{P}_{\mathcal{D}}[\mathrm{BAD} \ \mathcal{D} \ for \ h_2]+...+\mathbb{P}_{\mathcal{D}}[\mathrm{BAD} \ \mathcal{D} \ for \ h_M](union \ bound) \\ \ & \leq 2 \exp \left(-2 \epsilon^{2} N\right)+2 \exp \left(-2 \epsilon^{2} N\right)+\ldots+2 \exp \left(-2 \epsilon^{2} N\right) \\ \ & {=2 M \exp \left(-2 \epsilon^{2} N\right)} \end{aligned} $$
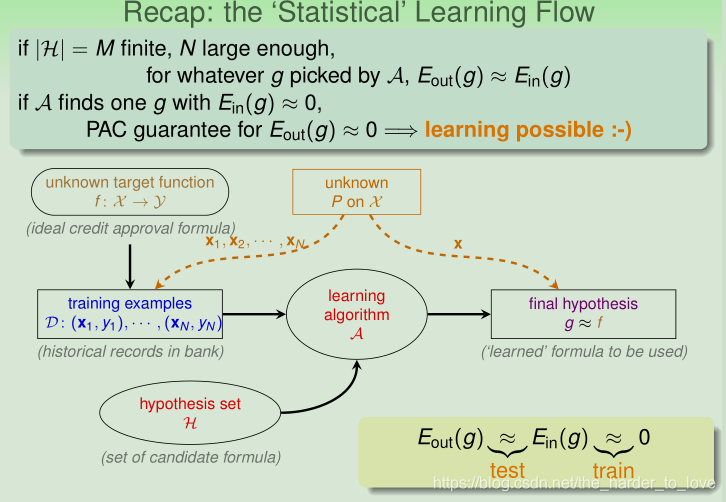
The ‘Statistical’ Learning Flow
若假设集(
)大小为有限的
,
足够大,通过机器学习演算法(
)学习到的对于任意一个
,都有
.
若此时
学到一个
,就能保证
=> learning impossible 真正学到了知识:-).
Fun Time
Consider 4 hypotheses.
For any
and
, which of the following statement is not true?
1 the BAD data of
and the BAD data of
are exactly the same.
2 the BAD data of
and the BAD data of
are exactly the same.
3
4
Explanation
参考多个
中,霍夫丁不等式的上界推导公式。
对于BAD data
,
和
相差大,那么假设h对于
,所得到
和
相差也会大,所以
和
都是BAD data.
所以
和
有相同的BAD data.
Summary
讲义总结
假设集(
)大小为有限的
,
足够大,通过机器学习演算法(
)学习到的对于任意一个
,都有
.
若此时
学到一个
,就能保证
=> learning impossible 真正学到了知识:-).
学习是可行的。
Learning is Impossible?
absolutely no free lunch outside
Probability to the Rescue
probably approximately correct outside
Connection to Learning
verification possible if
small for fixed
Connection to Real Learning
learning possible if
finite and
small
参考文献
《Machine Learning Foundations》(机器学习基石)—— Hsuan-Tien Lin (林轩田)
