作者:起名什么的最烦啦
链接:https://zhuanlan.zhihu.com/p/27965213
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
CNN由于固定的几何结构,导致对几何形变的建模受到限制。为了解决或减轻这个问题,这篇论文的工作便是提出deformable convolution 和deformable RoI pooling ,来提高对形变的建模能力。deformable convolution 和deformable RoI pooling都是基于一个平行网络学习offset(偏移),使卷积核在input map的采样点发生偏移,集中于我们感兴趣的区域或目标。
背景:如何有效地建模几何形变或变化(包括尺度、姿势等变化)一直以来都是一个挑战。大体上有两种方法来处理该问题:1)构建一个包含各种变化的数据集。其实就是数据扩增。2)使用具有形变不变性的特征和算法(例如SIFT )。然而,以上的方法存在着如下缺点:1)几何形变被假设是固定和已知的,这是一种先验信息,用这些有限的、已知的形变来进行数据扩增或设计算法,可想而知,对于新的、未知的形变则无法处理。2)手工设计的特征或算法无法应对过度复杂的形变,即便该形变是已知的。
Deformable Convolution :
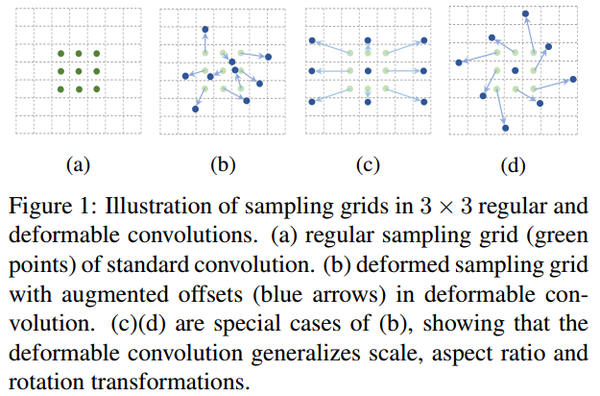
上图是在二维平面上deformable convolution和普通的convolution的描述图。(a)是普通的卷积,卷积核大小为3*3,采样点排列非常规则,是一个正方形。(b)是可变形的卷积,给每个采样点加一个offset(这个offset通过额外的卷积层学习得到),排列变得不规则。(c)和(d)是可变形卷积的两种特例。对于(c),加上offset,达到尺度变换的效果;对于(d),加上offset,达到旋转变换的效果。
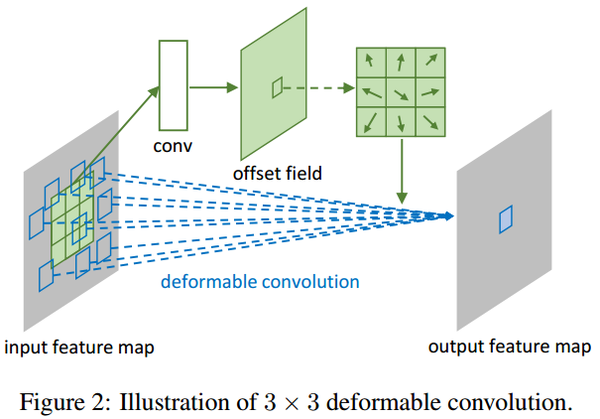
如上图所示,有一个额外的conv层来学习offset,共享input feature maps。然后input feature maps和offset共同作为deformable conv层的输入,deformable conv层操作采样点发生偏移,再进行卷积。
Deformable RoI Pooling :
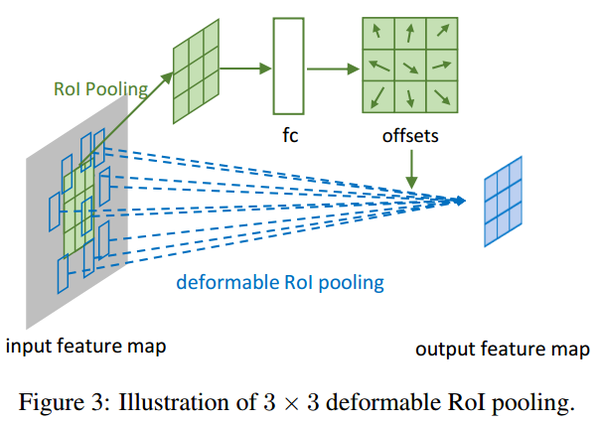
如上图所示,RoI被分为3*3个bin,被输入到一个额外的fc层来学习offset,然后通过一个deformable RoI pooling层来操作使每个bin发生偏移。
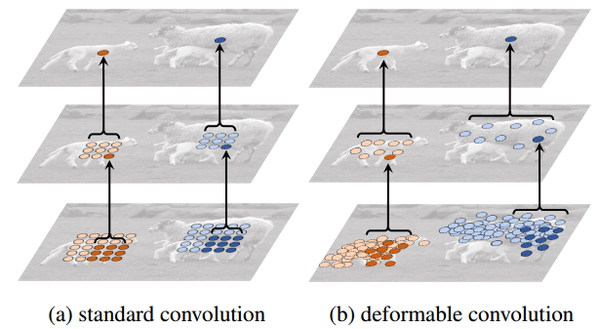
上图展示了两层的3*3卷积层的映射。对于标准的卷积,后面层的feature map上的一个点,映射到前面层所对应的感受野是规则的,无法考虑到不同目标的外形、大小不同;而可变形的卷积则考虑到了目标的形变,映射到前面层的采样点大多会覆盖在目标上面,采样到更多我们感兴趣的信息。

上图是可变形卷积采样点的一个可视化。三张图片为一组,绿点表示激活点,红点表示激活点映射到原图的采样点,三张图片分别对应背景、小目标和大目标的采样点可视化。
notes:end to end;可以被整合到任意网络模型;增加的参数量较少
更详细的理解:https://blog.csdn.net/qq_21997625/article/details/84899914
参考:
可變形的卷積網路 Deformable Convolutional Networks - Learning by Hacking