本文介绍下DCN的基本原理代码,以及用到DCN的一篇CVPR2019的目标检测文章GARPN
论文链接
Deformable Convolutional Networks:https://arxiv.org/pdf/1703.06211.pdf ICCV2017
Deformable ConvNets v2: More Deformable, Better Results: https://arxiv.org/pdf/1811.11168.pdf
Region Proposal by Guided Anchoring:https://arxiv.org/abs/1901.03278 CVPR2019
主要贡献:为了解决fixed geometric structures of CNN modules对于目标物体形变,尺寸不一适应不好的问题,在卷积层和roi pool引入offset从而使得模型将更多的注意力放在与物体有关的区域,适应不同尺度和形状的目标。V2则是在offset的基础上引入weight,让Deformable Conv不仅能学习offset,还能学习每个采样点的权重(modulation)

传统卷积的话就是

其中R表示为3*3的卷积核,对于每个位置p0,输出y
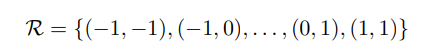
DCNv1中
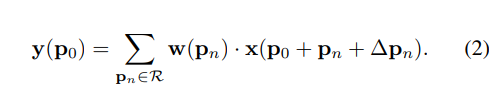
∆pn表示offset, x(p)的值用双线性插值获取,在DCNv2中
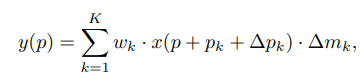
∆pk and ∆mk are the learnable offset and modulation scalar for the k-th location.主要的框架图如下图,对于输入的feature map首先用一个conv生成与输入的feature map同尺寸的channel为2N的offset field,N根据卷积核的大小进行取值,比如卷积核大小为3*3,所以N=9, 这里的2表示为卷积核的每个点对应的offset有两个方向分别为x,y。如果是DCNv2的框架图,这里的2N应该改为3N,多出的一个N对应着那个modulation scalar。

代码:https://github.com/open-mmlab/mmdetection/blob/master/mmdet/ops/dcn/deform_conv.py
一般用在resnet四个block的后三个block的每个Bottleneck的第二个conv中
DCNv1:
class DeformConv(nn.Module):
def __init__(self,
in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
dilation=1,
groups=1,
deformable_groups=1,
bias=False):
super(DeformConv, self).__init__()
assert not bias
assert in_channels % groups == 0, \
'in_channels {} cannot be divisible by groups {}'.format(
in_channels, groups)
assert out_channels % groups == 0, \
'out_channels {} cannot be divisible by groups {}'.format(
out_channels, groups)
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = _pair(kernel_size)
self.stride = _pair(stride)
self.padding = _pair(padding)
self.dilation = _pair(dilation)
self.groups = groups
self.deformable_groups = deformable_groups #表示将输入通道分成num_deformable_groups份,每份单独拥有各自的一对偏移,在DCNv2中默认为4,DCNv1中为1
# enable compatibility with nn.Conv2d
self.transposed = False
self.output_padding = _single(0)
self.weight = nn.Parameter(
torch.Tensor(out_channels, in_channels // self.groups,
*self.kernel_size))
self.reset_parameters()
def reset_parameters(self):
n = self.in_channels
for k in self.kernel_size:
n *= k
stdv = 1. / math.sqrt(n)
self.weight.data.uniform_(-stdv, stdv)
def forward(self, x, offset):
return deform_conv(x, offset, self.weight, self.stride, self.padding,
self.dilation, self.groups, self.deformable_groups)class DeformConvPack(DeformConv):
"""A Deformable Conv Encapsulation that acts as normal Conv layers.
Args:
in_channels (int): Same as nn.Conv2d.
out_channels (int): Same as nn.Conv2d.
kernel_size (int or tuple[int]): Same as nn.Conv2d.
stride (int or tuple[int]): Same as nn.Conv2d.
padding (int or tuple[int]): Same as nn.Conv2d.
dilation (int or tuple[int]): Same as nn.Conv2d.
groups (int): Same as nn.Conv2d.
bias (bool or str): If specified as `auto`, it will be decided by the
norm_cfg. Bias will be set as True if norm_cfg is None, otherwise
False.
"""
_version = 2
def __init__(self, *args, **kwargs):
super(DeformConvPack, self).__init__(*args, **kwargs)
self.conv_offset = nn.Conv2d(
self.in_channels,
self.deformable_groups * 2 * self.kernel_size[0] * self.kernel_size[1], #self.deformable_groups默认为1,kernel_size=3
kernel_size=self.kernel_size, #3
stride=_pair(self.stride), #2
padding=_pair(self.padding), #1
bias=True) #注意这里是True,在resnet其他conv中都是false
self.init_offset()
def init_offset(self): #注意初始化方式
self.conv_offset.weight.data.zero_()
self.conv_offset.bias.data.zero_()
def forward(self, x):
offset = self.conv_offset(x) #对应figture2中的conv,x[bs,in_channel, w,h] offset[bs,18,w/2,h/2]
#weight[out_channel,in_channel,3,3], stirde=2, padding=1, dilation=1, groups=1, deformable_groups=1
return deform_conv(x, offset, self.weight, self.stride, self.padding,
self.dilation, self.groups, self.deformable_groups)DCNv2
class ModulatedDeformConv(nn.Module):
def __init__(self,
in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
dilation=1,
groups=1,
deformable_groups=1,
bias=True):
super(ModulatedDeformConv, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = _pair(kernel_size)
self.stride = stride
self.padding = padding
self.dilation = dilation
self.groups = groups
self.deformable_groups = deformable_groups
self.with_bias = bias
# enable compatibility with nn.Conv2d
self.transposed = False
self.output_padding = _single(0)
self.weight = nn.Parameter(
torch.Tensor(out_channels, in_channels // groups,
*self.kernel_size))
if bias:
self.bias = nn.Parameter(torch.Tensor(out_channels))
else:
self.register_parameter('bias', None)
self.reset_parameters()
def reset_parameters(self):
n = self.in_channels
for k in self.kernel_size:
n *= k
stdv = 1. / math.sqrt(n)
self.weight.data.uniform_(-stdv, stdv)
if self.bias is not None:
self.bias.data.zero_()class ModulatedDeformConvPack(ModulatedDeformConv):
"""A ModulatedDeformable Conv Encapsulation that acts as normal Conv layers.
Args:
in_channels (int): Same as nn.Conv2d.
out_channels (int): Same as nn.Conv2d.
kernel_size (int or tuple[int]): Same as nn.Conv2d.
stride (int or tuple[int]): Same as nn.Conv2d.
padding (int or tuple[int]): Same as nn.Conv2d.
dilation (int or tuple[int]): Same as nn.Conv2d.
groups (int): Same as nn.Conv2d.
bias (bool or str): If specified as `auto`, it will be decided by the
norm_cfg. Bias will be set as True if norm_cfg is None, otherwise
False.
"""
_version = 2
def __init__(self, *args, **kwargs):
super(ModulatedDeformConvPack, self).__init__(*args, **kwargs)
self.conv_offset = nn.Conv2d(
self.in_channels,
self.deformable_groups * 3 * self.kernel_size[0] *
self.kernel_size[1], #self.deformable_groups默认为4,也可以为1,kernel_size=3
kernel_size=self.kernel_size, #3
stride=_pair(self.stride), #2
padding=_pair(self.padding), #1
bias=True)
self.init_offset()
def init_offset(self):
self.conv_offset.weight.data.zero_()
self.conv_offset.bias.data.zero_()
def forward(self, x):
out = self.conv_offset(x) #对应figture2的conv,conv_offset[in_channel,4*3*3*3,w,h],out[bs,108,w/2,h/2]
o1, o2, mask = torch.chunk(out, 3, dim=1)
offset = torch.cat((o1, o2), dim=1) #offset[bs,72,w/2,h/2]
mask = torch.sigmoid(mask) #对应那个∆mk modulation scalar mask[bs,36,w/2,h/h]
#weight[out_channel,in_channel,3,3], stirde=2, padding=1, dilation=1, groups=1, bias=None, deformable_groups=4 表示将输入通道分成num_deformable_groups份,每份单独拥有各自的一对偏移
return modulated_deform_conv(x, offset, mask, self.weight, self.bias,
self.stride, self.padding, self.dilation,
self.groups, self.deformable_groups)DCN的另外一种用法:
Region Proposal by Guided Anchoring
在Region Proposal by Guided Anchoring中,作者 Guided Anchoring: 物体检测器也能自己学 Anchor对RPN进行改造,利用Guided anchoring来对RPN进行改进,最后生成了质量更高的anchor,在anchor generation中的location预测F1每个点存在gt的概率,shape预测F1存在的gt的w,h,最后为了解决Consistency的问题,即每个位置 anchor 形状不同而破坏了特征的一致性。使用了feature adaption,代码中其实就是用的DCNv2

class FeatureAdaption(nn.Module):
"""Feature Adaption Module.
Feature Adaption Module is implemented based on DCN v1.
It uses anchor shape prediction rather than feature map to
predict offsets of deformable conv layer.
Args:
in_channels (int): Number of channels in the input feature map.
out_channels (int): Number of channels in the output feature map.
kernel_size (int): Deformable conv kernel size.
deformable_groups (int): Deformable conv group size.
"""
def __init__(self,
in_channels,
out_channels,
kernel_size=3,
deformable_groups=4):
super(FeatureAdaption, self).__init__()
offset_channels = kernel_size * kernel_size * 2 #18
self.conv_offset = nn.Conv2d(
2, deformable_groups * offset_channels, 1, bias=False) #deformable_groups=4
self.conv_adaption = DeformConv(
in_channels,
out_channels,
kernel_size=kernel_size, #3
padding=(kernel_size - 1) // 2, #1
deformable_groups=deformable_groups)
self.relu = nn.ReLU(inplace=True)
def init_weights(self):
normal_init(self.conv_offset, std=0.1)
normal_init(self.conv_adaption, std=0.01)
def forward(self, x, shape):
offset = self.conv_offset(shape.detach()) #x就是图中的F1,这里shape.detach()是为了将shape从计算图的这条路剥离?从而F1'的梯度不影响这个???
x = self.relu(self.conv_adaption(x, offset))
return x同时就像作者在 Guided Anchoring: 物体检测器也能自己学 Anchor中降到的,用GARPN得到了高质量的proposal之后提升的精度反而确实有限的,作者最后发现采用1. 减少 proposal 数量,2. 增大训练时正样本的 IoU 阈值(这个更重要)会有效,并且对了对比实验


注:以下内容来自:Guided Anchoring: 物体检测器也能自己学 Anchor
同时提出了两种对于 anchor 设计的两个准则,alignment(中心对齐) 和 consistency(特征一致)。其中 alignment 是指 anchor 的中心点要和 feature 的位置对齐,consistency 是指 anchor 的特征要和形状匹配。
- Alignment
由于每个 anchor 都是由 feature map 上的一个点表示,那么这个 anchor 最好是以这个点为中心,否则位置偏了的话,这个点的 feature 和这个 anchor 就不是非常好地对应起来,用该 feature 来预测 anchor 的分类和回归会有问题。我们设计了类似 cascade/iterative RPN 的实验来证明这一点,对 anchor 进行两次回归,第一次回归采用常规做法,即中心点和长宽都进行回归,这样第一次回归之后,anchor 中心点和 feature map 每一个像素的中心就不再完全对齐。我们发现这样的两次 regress 提升十分有限。所以我们在形状预测分支只对 w 和 h 做预测,而不回归中心点位置。
- Consistency
这条准则是我们设计 feature adaption 的初衷,由于每个位置 anchor 形状不同而破坏了特征的一致性,我们需要通过 feature adaption 来进行修正。这条准则本质上是对于如何准确提取 anchor 特征的讨论。对于两阶段检测器的第二阶段,我们可以通过 RoI Pooling 或者 RoI Align 来精确地提取 RoI 的特征。但是对于 RPN 或者单阶段检测器的 anchor 来说,由于数量巨大,我们不可能通过这种 heavy 的方法来实现特征和框的精确 match,还是只能用特征图上一个点,也就是 512x1x1 的向量来表示。那么 Feature Adaption 起到了一个让特征和 anchor 对应更加精确的作用,这种设计在其他地方也有可以借鉴之处。
参考:
如何评价 MSRA 视觉组最新提出的 Deformable ConvNets V2? - 知乎 https://www.zhihu.com/question/303900394