一、论文简述
1. 第一作者:Han Hu
2. 发表年份:2023
3. 发表期刊:The Photogrammetric Record
4. 关键词:MVS,三维重建,深度学习,自适应卷积
5. 探索动机:尽管使用自适应匹配窗口获得了令人鼓舞的结果,几何先验的确定仍然是一个挑战。
Ideally, the estimation of the photo-consistency must be confined within a certain region, for example, within the boundaries of the target object. Low-level geometrical features, such as line contours, planar segments or superpixels, are typically used to adaptively select the supporting domain. However, low-level features are vulnerable to noise and may not correspond to the object boundaries. For instance, even correctly defined line contours may not essentially represent the contours of discontinuous regions. Therefore, the determination of meaningful geometrical priors requires high-level semantic understanding of the object rather than low-level geometric clues.
6. 工作目标:提升匹配特征的有效性。
7. 核心思想:本文提出了一种使用可变形卷积网络(DCNs)的MVS自适应区域聚合方法。
- a learnable adaptive region aggregation method for MVSNet based on DCNs for effectively matching descriptors;
- a dedicated offset regulariser for the learnable offsets of the DCN to enhance its convergence.
8. 实验结果:
The proposed method outperforms the state-of-the-art method in dynamic areas with a significant error reduction of 21.3% while retaining its superiority in overall performance on KITTI. It also achieves the best generalization ability on the DDAD dataset in dynamic areas than the competing methods
9.论文下载:
https://github.com/YueyueBird-su/DFPN_Module_in_MVS
https://onlinelibrary.wiley.com/doi/10.1111/phor.12459
二、实现过程
1. 具有自适应聚合窗口的可变形特征提取器
CNN令人印象深刻的特征学习能力允许创建高级特征。如前所述,确定合适的支持域来计算光度一致性需要对场景的语义理解,例如,窗口的自适应聚合必须利用通过CNN层获得的潜在特征。DCNs在卷积中引入额外的像素偏移,并在移位的位置选择特征,从而产生不规则的感受野。使用DCN对图像匹配的自适应聚合窗口进行建模。下图演示了 3 × 3可变形卷积,如何从N维特征学习偏移并进行卷积。
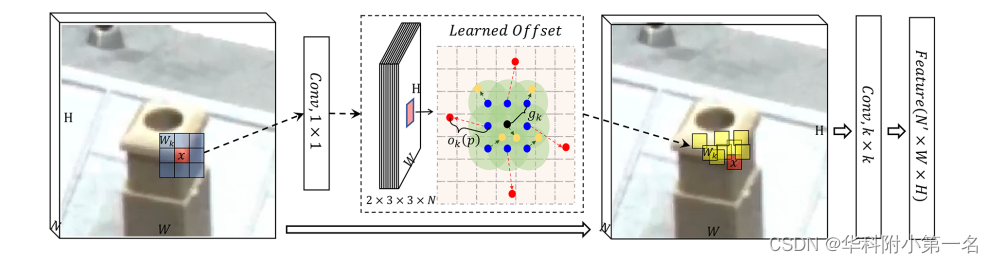
该方法能有效克服边界区域不同视点图像不一致导致深度图不准确的问题。

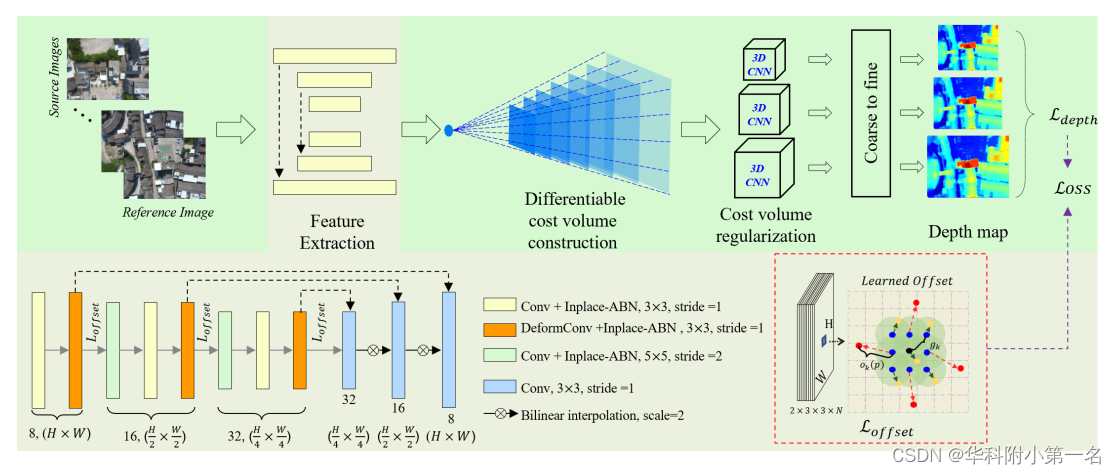
2. 损失函数
在粗到细匹配策略中,生成了多尺度深度图Dl。因为精细匹配的质量取决于粗层次的结果,所有的深度图都对最终的损失函数有贡献。L1被用作损失函数。此外,对真值深度图进行双线性插值下采样。多尺度深度图的最终损失定义为:
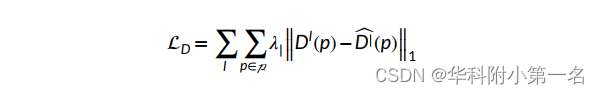
其中λ={2,1,0.5}被设置为一个递减的权重,以平衡图像分辨率的差异。
由于深度损失LD对低频对应的连续值的偏差进行建模,因此在语义分类方面并不优于one-hot表示。与其他形式的神经网络相比,使用语义信息标签进行训练的神经网络表现更好。尽管特征提取网络的参数明显少于分类任务,但在DCNs中使用核偏移量会导致收敛性能不足。由于相似性匹配的描述符通常是局部化的,并且框架涉及多个层来增加感受野,因此使用以下偏移正则器来约束DCN中所有偏移图中的偏移距离。

其中,每个核点p的偏移距离记为ok(p) =√x2 +y2,且偏移量小于3像素被截断为0。上述两种损失通过经验权值平衡,并联合用于反向传播L=LD + 10LO。