目录
Abstract
CNN由于其固定的结构而受限于模型的几何变换,本文提出的两个新模块加强了CNN的变换能力,(Deformable Convolution,DC)和(Deformable RoI Pooling,DRP)。两者的设计均是基于在模块中通过偏移来增墙空间采样位置,并从目标任务中学习偏移量。实验证明,DCN可以替代CNN用以实现如目标检测、语义分割等复杂的视觉任务。
论文贡献:
1.提出一种适应性采样方法;
2.在不显著增加参数量和计算的情况下提高目标检测和语义分割模型的性能;
3.可以轻易集成到基于CNN的计算机视觉任务中
1. Introduction
Deformable convolution network由两个模块构成,一个是deformable convolution,一个是 deformable RoI pooling。
CNN中在特征图上的卷积操作是三维的,即平面加通道。而deformable convolution和deformable RoI pooling则是二维空间的的,他们改变卷积在平面上的采样位置,即感受野的位置,而通道维度则没有改变,通过这种方式提高特征提取的性能。如图

2. Deformable Convolutional Networks
Deformable Convolution
2D卷积有两步:
第一步是通过一个卷积核在特征图上采样;
第二步把这些采样点乘不同权重w后相加。
卷积中采样点是规则的,比如一个扩张度(dilation)为1 的3×3卷积核表示为:
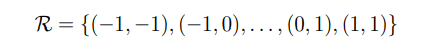
p若o则是输出特征图y上的一点,那么卷积操作就定义为:
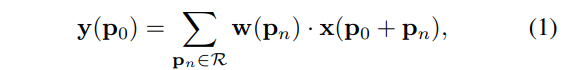
可变卷积的deformation指的则是改变卷积操作中的第一步——修改采样点位置,可通过给采样点加位移offset实现。
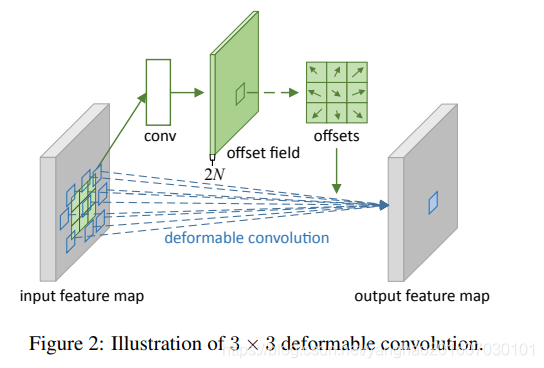
原理如下图:
首先通过一个和正常卷积一样的卷积和对输入特征图做卷积,得到一个和输出特征图空间维度一样的特征图大小,通道数位2N,2是每个点有x和y方向的偏移,N是二维空间上卷积的一个感受野大小,N=k×k。对应于输出特征图上的每个点,其卷积的采样点通过offsets特征图上该点处的2N个channel上的2N个offsets值来确定。确定采样点后就通过权重w相加得到输出图上该点最终值。
上述的公式表示:
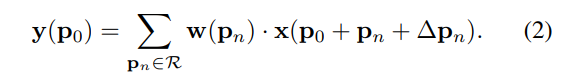
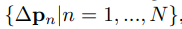
ΔPn就是我们的offsets,共N(N=k×k)个。
然后细节上补充一点,ΔPn通常会是小数,从而P=P0+Pn+ΔPn也是小数,那么x(p)取值就要谨慎选择,这里取P四周的四个整数点q,通过双线性插值来求得x(P).
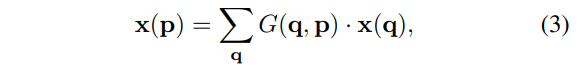
其中G是二维的,可分为两个一维的运算。
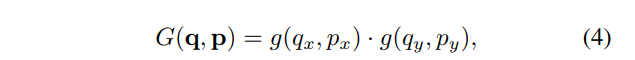
其中g(a, b) = max(0, 1 − |a − b|)。
上式即双线性插值,简单讲就是四个点分两组先x方向线性插值得到两个点,然后这两个点再y方向线性插值得到最终值。
示意图:图源:https://blog.csdn.net/u013010889/article/details/78803240
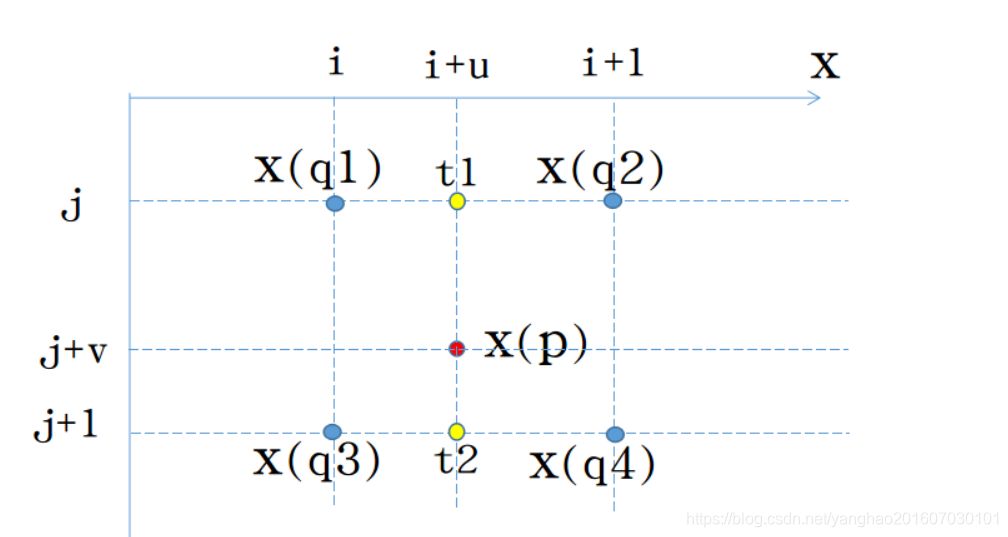
强调以下,这里用于生成采样点偏移的卷积核与生成最终特征图的卷积核尺寸和步长都一样,他们都作用于同一个输入特征图,且生成的offset field和生成的特征图尺寸一样,两个卷积核同时学习,而对于offset field的学习可能会出现小数的坐标点,因此反向传播过程中利用线性插值来学习梯度,也就是上面提到的双线性插值方式。
Deformable RoI Pooling
RoI Pooling将输入的任意大小的矩形区域转换为固定大小的特征。
RoI Pooling所作操作:首先将RoI映射到特征图上,然后给定输入特征图x,以及一个大小为w×h,其左上角为P0 的RoI,,则RoI Pooling将特征图划分为k × k个bins,每个bins通过池化操作输出一个值,最终输出一个k × k的特征图y。
于是对于第(i, j)个bin有
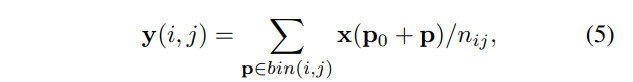
其中 n i j n_{ij} nij是该bin(i,j)中的像素个数。bin(i,j)中像素p的两个坐标 p x , p y p_x,p_y px,py的取值范围如下:
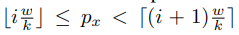
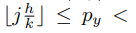
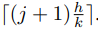
与上面的可变性卷积等式(2)相似,这里给每个bin内的所有像素加上一个偏移{∆ p i j p_{ij} pij |0 ≤ i, j < k},然后上面的等式5就变成了下面的等式6.
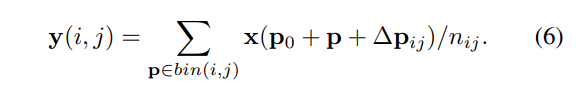
通常 ∆ p i j ∆p_{ij} ∆pij是个小数,所以等式6要经过上文中提到的双线性插值计算,即等式(3)和(4)。
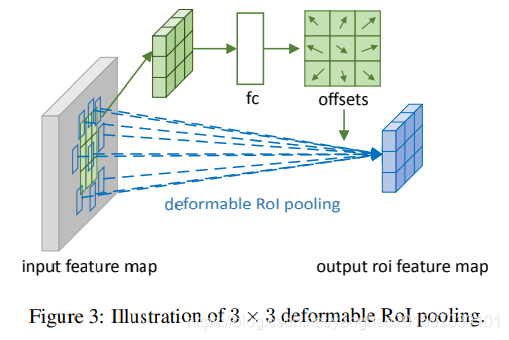
图3显示了如何获取该偏移,首先, RoI pooling 生成池化后的特征图,之后在此特征图上通过一个全连接生成归一化后的偏移∆ p i j ^ \hat{p_{ij}} pij^,然后该偏移会通过和RoI的宽和高进行元素级相乘得到用于等式(6)中的∆ p i j p_{ij} pij,即有 ∆ p i j = γ ⋅ ∆ p i j ^ 。 ( w , h ) ∆p_{ij}=γ ·∆\hat{p_{ij}}。(w,h) ∆pij=γ⋅∆pij^。(w,h)。其中 γ γ γ是一个预定义的标量,用来调整偏移的数量级,一般令 γ γ γ=0.1,而偏移的归一化则能让offset具有尺度不变性,其中的全连接层通过反向传播学习,可见附录A。
Position-Sensitive (PS) RoI Pooling。作为RoI Pooling的变种,Position Sensing RoI Pooling也有其可变性形式,即deformable PS RoI pooling.其架构图如下:
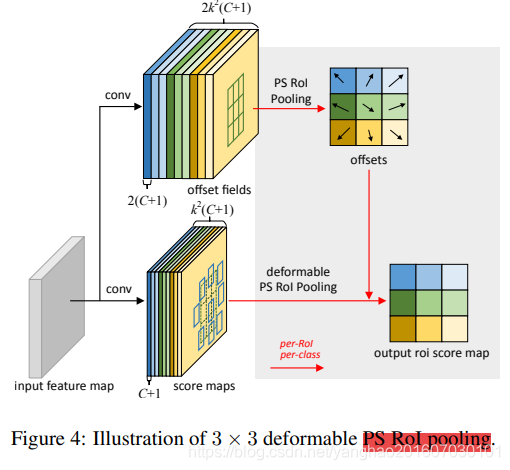
下面的分支和RoI大体相同,除了每个bin来自特定的score map,如(i,j)对应第(i,j)个map,这里不单独讨论每个类的情况。即在deformable PS RoI pooling中,等式(6)唯一的变化是x变成了 x i , j x_{i,j} xi,j。但是除公式外,偏移的学习也不同,deformable PS RoI pooling跟随全卷积的思想,图4中上面的分支就是offsets学习分支,将输入特征图传入一个卷积,得到通道为2×(C+1)×k×k,尺寸和score map一样的offset fields,这里学习得到的偏移是归一化后的偏移,需要通过和deformable RoI pooling中一样的变换方式得到 ∆ p i j ∆p_{ij} ∆pij。其中C+1对应种类数加背景,2是x,y这两维,k×k对应划分的N个部分,每个部分的在每一格子的偏移单独一个通道。正如下面那个分支中物体为每个部分的得分单独一个通道一样。
Deformable ConvNets
可变形卷积核RoI Pooling模块与他们的朴素版本(非可变形)的输入输出相同。所以在现存的CNN中容易替换他们的朴素版本,训练时增加conv核fc层来学习偏移,使用0初始化权重。他们的学习设置为现有层的β倍(默认β为1,Faster R-CNN中的fc层的β=0.01),通过双线性插值和反向传播学习。得到的CNN叫做deformable ConvNets.
怎么把deformable ConvNets和现存的SOTA CNN架构结合呢,首先我们要注意到这些架构分为两个阶段:第一个阶段深度全卷积网络在整个输入图片上提取特征图;第二个阶段浅层的特殊网络在此特征图上生成结果。下面详述这两个阶段。
Deformable Convolution for Feature Extraction。文中使用了两个SOTA模型来做特征提取,即ResNet-101和修改过的Inception-ResNet版本,这两个模型都由几个convolutional blocks,一个average pooling,一个用于ImageNet分类的1000-way fc layer组成,这里都去掉他们的average pooling和1000-way fc layer,并且在最后添加一个1×1卷积来减小通道数为1024.和一些常见的设置一样,这里还将最后一个卷积块的开始stride从2变为1,以使得最后一个块的有效stride从32变16,从而使得输出特征图分辨率大些,为了做补偿,最后一个块的所有卷积核的dilation从1变为2.
可以选择将deformable convolution用到最后几个卷积层,实验表明使用3个可变形卷积取得最佳平衡。
Segmentation and Detection Networks.。如上文提到,一个特殊的网络建立在特征提取网络输出的特征图上。论文中这里举例了实例分割核目标检测的一些head网络,其中目标检测放目针对检测网络头Faster R-CNN核R-FCN做了替换说明,即使用可变形的RoI Pooling和位置敏感的可变形RoI Pooling替换其中对应的朴素版本。
3. Understanding Deformable ConvNets
这项工作的思想是基于通过偏移来增强卷积的空间采样位置,和增强RoI Pooling,并且从目标任务中学习偏移。
随着可变形卷积的堆叠,可变形卷积的影响越大,如图5所示,左边最上层的标准卷积中感受野和采样点都是固定的,而右边可变形卷积中它们则会适应性的改变。
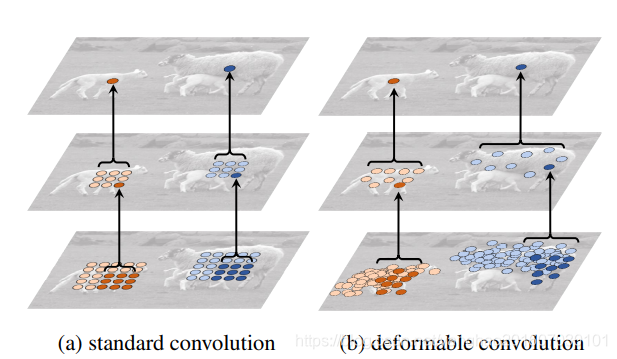
图5.2个卷积层分别展示:a是标准卷积的固定感受野,b是可变形卷积的适应性感受野。
3.1. In Context of Related Works
这部分从多个方面介绍论文的相关工作,内容参考(十三)论文阅读 | 目标检测之DCN
Spatial Transform Networks, STN,空间变换网络是在深度学习领域中学习数据空间变换的开创工作。
Active Convolution,同样地,这项工作也是在卷积过程中学习对采样位置的偏移,并通过反向传播更新参数。但有所不同的是:(1)它在不同的空间位置共享偏移;(2)偏移参数是静态的,即对于每个任务或每次训练单独学习。
Effective Receptive Field,这项工作揭示了感受野中的像素点贡献不尽相同。有效区域只占据了感受野的很小一部分,且像素点的总体贡献呈高斯分布。这就需要一种适应性的区域采样方法。
Atrous Convolution(dilated convolutions),空洞卷积最早出现在语义分割任务中,目的是在卷积的过程中增大感受野,从而可以在深层网络中保留图像的原始特征。同时,可以通过设置不同空洞率捕捉多尺度上下文信息。如下图是一维空洞卷积示意图:
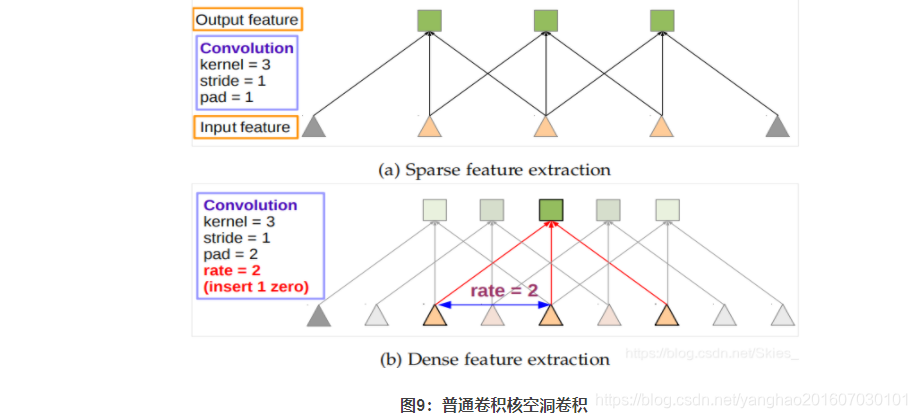
如上图,普通卷积对应于稀疏采样;空洞卷积对应于密集采样。空洞卷积通过在输入特征图上加入零填充,得到输出特征图的感受野增大。如图(b)中对应感受野为5 55,图(a)中对应感受野为3。空洞卷积最早在DeepLab中提出,论文来自这里。
Deformable Part Models, DPM,可变形RoI池化的思想类似于DPM。DPM是传统的基于像素梯度的目标检测方法,核心思想是将目标对象建模成几个部件的组合。它不能实现端到端训练,且需要大量的先验信息,如部件以及部件的大小等。
DeepID-Net,其与可变形RoI池化的思想类似,但实现更加复杂。DeepID-Net基于R-CNN实现,且难以集成到目标检测模型中实现端到端训练。其余的部分介绍了空间金字塔池化、SIFT、ORB等相关工作。
4. Experiments
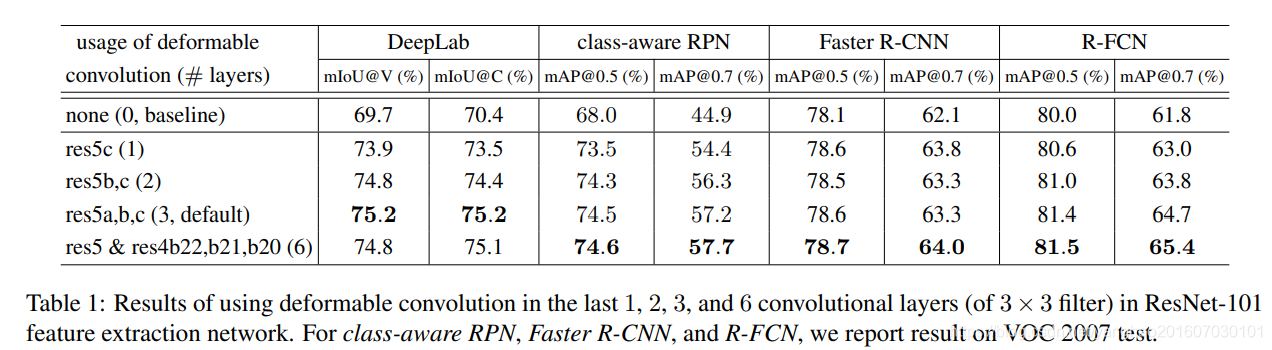
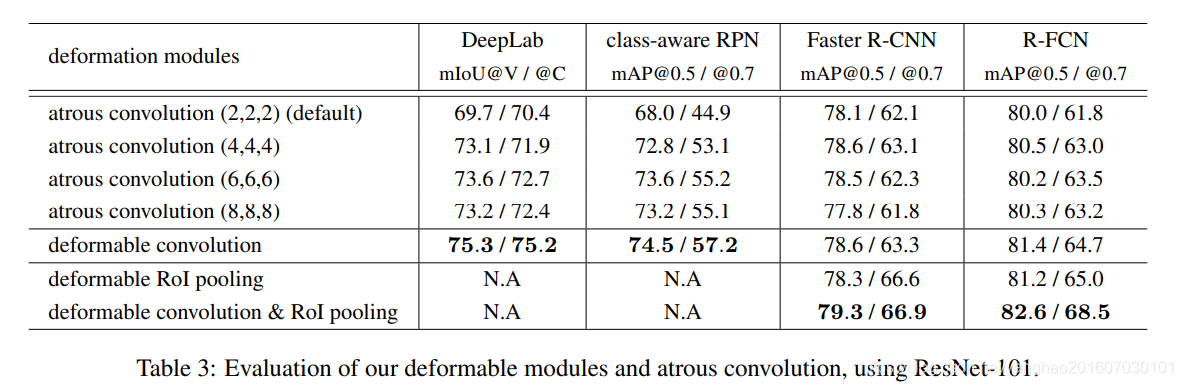
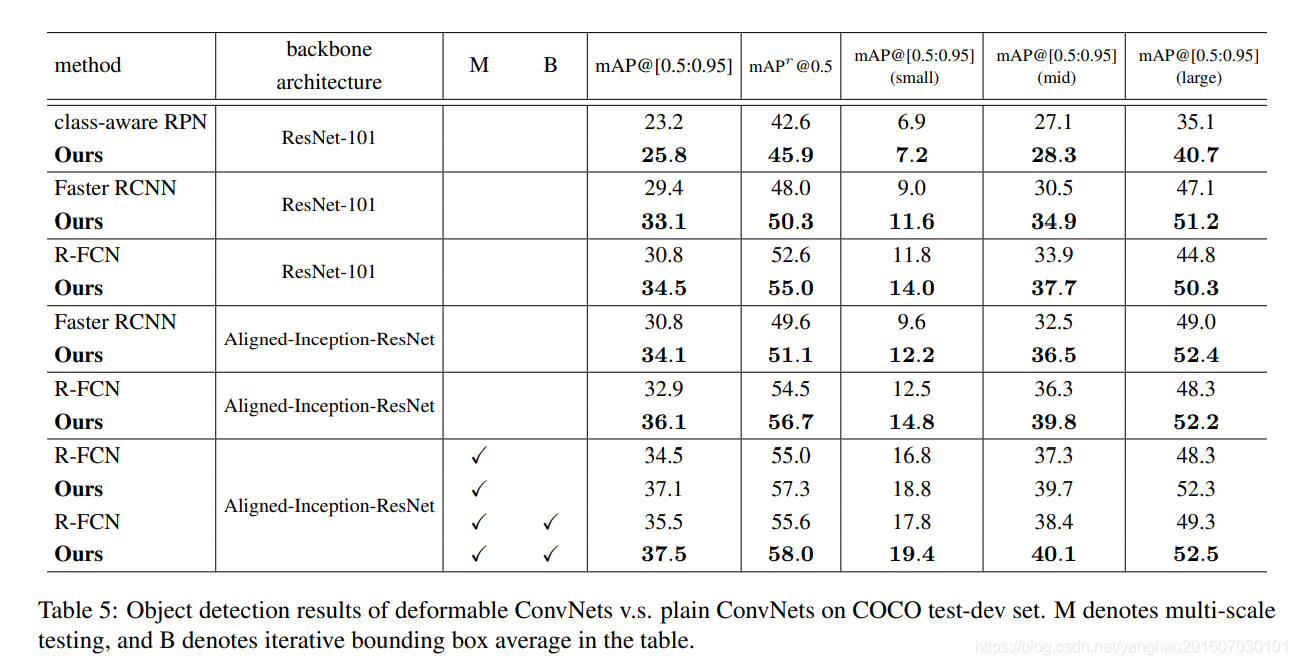
经典模型应用可变形卷积后的提升。
5. Conclusion
论文提出一种适应性采样的方法,进而提出可变形卷积神经网络DCN。第一次提出一种灵活有效的方法来学习CNN的密集空间变换来解决复杂的视觉任务。并且DCN可以在不增加大量参数和代价的情况下与任何基于CNN的模型结合并提高模型精度。
DilatedConv和Deconvolution
文中还提到了dilation(扩展)dilated convolutions又名空洞卷积(atrous convolutions,这里简单做个笔记。
要提高感受野有哪些方法?
我们可能都会想到通过pooling或者让卷积核的stride>1,这样得到的特征图上每个像素的感受野会变大。但是这2种方式的会让我们的特征图分辨率变小,而有时候我们需要在提升感受野的同时保持图像有高分辨率,例如实力分割中,分类是像素级别的,最终的分类特征图和输入图片尺寸一样大,如果用上面两种方式就需要经过downsampling和upsampling,过程中必然会有进度损失。
那么有没有不让分辨率变小,同时又能增加输出特征图上每个像素感受野的方式呢?有,那就是空洞(扩张)卷积(dilated conv)
下面引用知乎谭旭对空洞卷积和反卷积的解释:
链接:https://www.zhihu.com/question/54149221/answer/192025860

(a)图对应3x3的1-dilated conv,和普通的卷积操作一样,(b)图对应3x3的2-dilated conv,实际的卷积kernel size还是3x3,但是空洞为1,也就是对于一个7x7的图像patch,只有9个红色的点和3x3的kernel发生卷积操作,其余的点略过。也可以理解为kernel的size为7x7,但是只有图中的9个点的权重不为0,其余都为0。 可以看到虽然kernel size只有3x3,但是这个卷积的感受野已经增大到了7x7(如果考虑到这个2-dilated conv的前一层是一个1-dilated conv的话,那么每个红点就是1-dilated的卷积输出,所以感受野为3x3,所以1-dilated和2-dilated合起来就能达到7x7的conv),©图是4-dilated conv操作,同理跟在两个1-dilated和2-dilated conv的后面,能达到15x15的感受野。对比传统的conv操作,3层3x3的卷积加起来,stride为1的话,只能达到(kernel-1)*layer+1=7的感受野,也就是和层数layer成线性关系,而dilated conv的感受野是指数级的增长。dilated的好处是不做pooling损失信息的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息。
deconv和dilated conv的区别:
deconv的具体解释可参见如何理解深度学习中的deconvolution networks?,deconv的其中一个用途是做upsampling,即增大图像尺寸。而dilated conv并不是做upsampling,而是增大感受野。可以形象的做个解释:对于标准的k*k卷积操作,stride为s,分三种情况:
(1) s>1,即卷积的同时做了downsampling,卷积后图像尺寸减小;
(2) s=1,普通的步长为1的卷积,比如在tensorflow中设置padding=SAME的话,卷积的图像输入和输出有相同的尺寸大小;
(3) 0<s<1,fractionally strided convolution,相当于对图像做upsampling。比如s=0.5时,意味着在图像每个像素之间padding一个空白的像素后,stride改为1做卷积,得到的feature map尺寸增大一倍。
而dilated conv不是在像素之间padding空白的像素,而是在已有的像素上,skip掉一些像素,或者输入不变,对conv的kernel参数中插一些0的weight,达到一次卷积看到的空间范围变大的目的。当然将普通的卷积stride步长设为大于1,也会达到增加感受野的效果,但是stride大于1就会导致downsampling,图像尺寸变小。大家可以从以上理解到deconv,dilated conv,pooling/downsampling,upsampling之间的联系与区别,欢迎留言沟通交流。