论文地址:https://arxiv.org/abs/1703.06211
摘要:卷积神经网络的固定几何结构限制了模型对物体形变的建模能力,在本工作中,我们引入了两个新的模块来增强CNNs的形变建模能力,即可变形卷积和可变形RoI池。通过额外的偏移量参数增强空间位置采样能力,并从目标任务中学习偏移量,不需要附加偏移量监督。新模块可以很容易的在现有网络中进行替换,通过标准反向传播很容易进行端到端的训练。大量的实验验证了该方法的性能。首次证明了在深层CNN中学习密集空间变换对于复杂视觉任务如目标检测和语义分割是有效的。
1.引言
视觉识别的一个关键挑战是如何适应几何变化或物体尺度,姿势,关键点,和部分变形的几何建模能力。一般来说,有两种方法。首先是建立具有足够多变化的训练数据集。这是通常通过增加现有的数据样本来实现,例如,通过仿射变换。健壮的表示可以从数据中学习,但通常代价是较长的训练时间和复杂的模型参数。第二个是使用transformation-invariant 特征和算法。这一类别包括许多众所周知的技术,例如SIFT(尺度不变特征变换)的[42]和基于滑动窗口的对象检测。但上面的方法有两个缺点,第一,几何形变假设是已知且固定的,使用这样的先验知识对数据进行扩充,并设计特征和算法。这个假设阻碍了对具有未知几何变换的新任务的泛化,这些未知的形变没有学习。第二,手工设计的不变特征和算法对于过于复杂的特征变换是很难的甚至不可行。
总而言之,固定的CNN网络模型结构限制了对未知形变的学习能力,所谓固定的模型结构主要来自于两个方面:1.卷积核对于输入的特征图在固定的位置进行采样。2.池化层以固定的池化率(stride=2)进行池化以减小空间分辨率,ROL池层将RoI分成固定的空间容器等。因此缺少内部的机制来处理几何形变。
这造成了明显的问题。例如,同一CNN层中所有激活函数的感受野都是一样的。这对于在空间位置上编码语义的深层CNN是不太理想的。因为不同的位置可能对应于不同尺度或变形,自适应感受野的确定对于具有精细定位的视觉识别任务是很有帮助的,如用FCN进行语义分割。本篇论文我们引入了两种模块极大增强了CNN网络对几何形变的建模能力。

第一个是可变形卷积。它在标准卷积中的采样位置上增加了2D偏移,它使得卷积核采样进行自由的形变如图1,偏移量通过额外的卷积层由输入的特征层进行学习得到。因此形变是以局部、密集和自适应方式的输入特征为条件的。第二个是可变形ROI池化,它增加了一个偏移量在先前标准的ROI的位置上,类似的,偏移量通过输入的特征层学习得到。这两个模块都是轻量级的。它只增加了很少的参数和计算量来进行偏移量的学习。它们可以方便的在各种CNN网络中替换对应的卷积或ROI池化,并且可以容易地通过标准的反向传播进行端到端的训练。这种网络称之为可变形卷积网络,或deformable ConvNets。
我们的方法与transform networks [26] and deformable part models有着极其相似的地方,它们都有内部转换参数而且学习这些参数纯粹来自数据本身。一个关键的不同点是可变形ConvNets是处理密集空间的网络、简单、高效、深层和端到端的转换方式。在第3.1节中,我们详细讨论了我们的工作与以往的工作相比,并分析了可变形网络的优势。
2.可变形卷积网络
CNN中的特征映射和卷积都是3D的,可变形卷积和RoI池模块运行在2D空间域上。横跨通道维度时操作保持不变。不失一般性,为了表示清晰,这里在2D中描述模块,对3D的扩展非常简单。标准卷积操作包含两个部分,1.在输入特征映射x上使用常规网格R进行采样2.求权重W采样的和。R定义了感受野的大小和dilation,如R = {(-1; -1); (-1; 0); : : : ; (0; 1); (1; 1)},定义了一个dilation=1的3*3卷积核。对于输出的特征图y上的每个位置P0,则有:
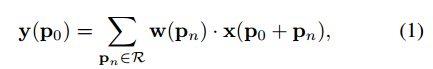
Pn枚举了R中的位置。在可变形卷积中,R通过偏移量{∆pn|n = 1; :::; N}被增强,N=|R|,于是有:
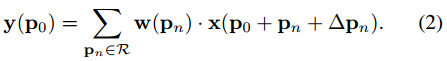
现在,采样是在不规则位置和偏移位置上Pn+∆Pn。由于偏移∆Pn通常是分数的,所以式(2)通过双线性插值实现,如
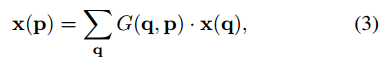
其中,p表示任意(分数)位置(p=p0 + pn + ∆pn),q表示特征图x中的所有空间位置;G(...)是双线性插值核函数,G(...)是二维的,它可以分解成两个一维的,如下;
![]()
g(a; b) = max(0; 1 - |a - b|)

偏移量是通过在同一输入特征上引入一个卷积层来获得,卷积核具有与当前卷积层相同的空间分辨率和膨胀率。输出偏移量与输入特征图具有相同的空间分辨率。通道2N对应N*2D的偏移量(一个平面上的偏移量用一个二维点(x,y)表示)。在训练期间,用于生成输出特征图和偏移量的卷积核同时学习,为了学习偏移,梯度通过式(3)和(4)中的双线性运算反向传播。
2.3 Deformable ConvNets
可变形卷积和ROI池化模块与原来对应普通的操作有着相同的输入输出,因此可以很容易的替代原有CNN部分对应操作。在训练中,为了学习偏移量这些增加了conv和fc的层用0权重初始化。它们的学习率设置为β倍现有层的学习速率(默认情况下为β=1,对于Faster-RCNN中的fc层,β=0.01),通过双线性插值的反向传播进行训练。为了将可变形ConvNets与最新的CNN体系结构集成在一起,我们注意到这些体系结构包括两个阶段。首先,一个深层完全卷积网络生成整个输入图像的特征图。第二,浅层任务特定网络从特征图得到结果。我们详细说明了以下两个步骤:1.可变形卷积用于特征提取,我们采用了两个性能非常好的网络Resnet101和InceptionResNet-v4.最初的Inception-ResNet是为图像设计的识别。对于密集的预测任务,它有一个特征不对准的问题。 为了解决对齐问题,修改版本叫做Aligned-Inception-ResNet【20】。
两个模型都由几个卷积块组成,平均池化和1000-way fc层用于ImageNet分类。平均池和fc层被移除,最后增加了一个随机初始化的1×1卷积将信道尺寸减小到1024。如同普通的操作[4,7],在最后一个卷积块中的有效步长从32个像素减少到16个像素,以提高特征图的分辨率。特别地,在最后一个块的开始处,步幅从2改变为1(“conv5”对于ResNet-101和Aligned-Inception-ResNet)。为了补偿步幅减小的操作,在这个卷积块中卷积滤波器的膨胀从1更改为2。可选地,可变形卷积应用于最后的几个卷积层(核大小>1)。我们用不同数量的这种层进行实验,发现3是不同任务的良好权衡。如下表所示:

语义分割和检测任务:
DeepLab[5]是一种最新的语义方法分割。在用于生成(C+1)映射的特征映射,该映射表示每个像素的分类分数然后一个soft-max层输出每个像素的分类概率。