0 摘要
最近的成果显示,如果神经网络各层到输入和输出层采用更短的连接,那么网络可以设计的更深、更准确且训练起来更有效率。本文根据这个现象,提出了Dense Convolutional Network (DenseNet),它以前馈的方式将每个层都连接到其他每一层。然而传统的 层卷积神经网络有 连接(每一层与其后面的一层相连接),而DenseNet的任一层不仅与相邻层有连接,而且与它的随后的所有层都有直接连接,所以该网络有 个直接连接。DenseNets有如下几个令人信服的优点:缓解了消失梯度问题,增强了特征传播,促进了特征重用,大大减少了参数的数量。本文计算架构在四个具有高度竞争的目标识别数据集(CIFAR-10,CIFAR-100, SVHN, and ImageNet)上进行实验。DenseNets相对于目前最先进的算法有明显的改善,且采用更少的计算来实现高性能。代码和预训练模型如下:https://github.com/liuzhuang13/DenseNet
1 介绍
卷积神经网络(CNN)已成为占主导地位的机器学习的视觉物体识别方法。尽管CNN最早被提出已经有20年了,但计算机硬件和网络结构的改进才使得最近才能真正的训练深度神经网络。原始的LeNet5包含了5层,VGG网络19层,Highway和ResNets超过了100层的大关。
随着神经网络变得越来越深,一个新的研究问题出现了:当输入(或梯度)信息经过许多层时,当它到达网络的结束(或开始)时,它就会消失并“洗出”。许多最近的文章着力解决这个问题,ResNets 和 Highway Networks旁路信号通过identity connections从一层到下一层。Stochastic depth缩短resnets,通过训练期间随机丢弃层,来获得更好的信息和梯度流。FractalNets将不同数量的卷积块的多个并行层序列重复组合,以获得较大的深度,同时在网络中保持许多短路径。尽管这些不同的方法在网络拓扑结构和训练过程中有所不同,但它们都具有一个关键特征:它们创建了从前面层到后续层的短路径。
在本文中,我们提出了一种将这种方法提炼成简单连接模式的架构:为了确保网络中各层之间的最大信息流,我们直接将所有层(具有相同的特征图尺寸的层)连接起来。为了保留前向传播的特性,每一层的输入来自前面所有层的输出,并将其自身的特征映射传递到所有后续层。如图1所示。 至关重要的是,与ResNets相比,我们没有采用合并之前所有层的特征到一层的方法;相反,我们把它们连接起来,结合所有层的特点。因此,第
层会有
个输入,由之前的所有卷积块的特征图组成。它自己的特征映射被传递到所有的
后续层。这在
层网络中引入
个连接,而不像传统体系结构中的
那样。 由于其密集的连接模式,我们将我们的方法称为密集卷积网络(DenseNet)。
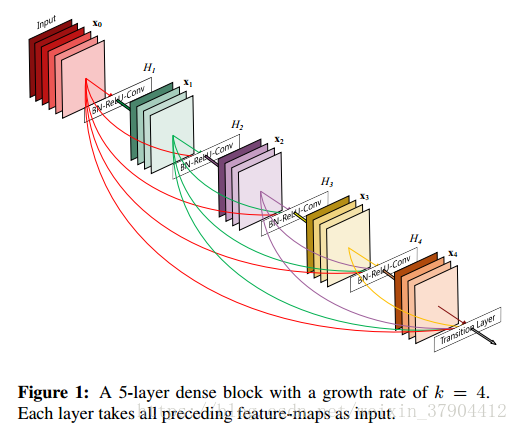
这种密集的连接模式的直观效果是它需要的参数比传统的卷积网络少,无需重新学习冗余特征图。传统的前馈结构可以看作是一种状态的算法,它是从层到层传递的。每个层从其上一层读取状态并写入后续层,它改变了状态,但也传递了需要保存的信息。 ResNets保存信息是通过附加的identity connection。ResNets 最近的改进版本表明,有很多层的贡献很少,实际上可以在训练期间随机丢弃,使得ResNet的状态类似于展开的递归神经网络,但是ResNets的参数数目要大得多,因为每一个层都有自己的权重。我们提出的DenseNet体系结构清楚地区分添加到网络的信息和保存的信息。DenseNet层很窄(例如,每层12个filter),添加少量特征图的网络,保持其余的特征图不变,最终的分类器的结果是基于网络的所有特征图。
除了更好的参数效率之外,DenseNets的一大优势是改善了整个网络中的信息流和梯度,这使得它们易于训练。每一层都可以直接从损失函数和原始输入信号中获得梯度,从而产生隐含的深层监督。这有助于深入网络体系结构的训练。 此外,我们还观察到密集连接具有正则化效应,缓解了训练集小导致的过拟合现象。
3 DenseNets
考虑一张单一的图像
通过一个卷积神经网络。这个网络有
层,每层实现一个非线性变换
。其中,
是层的编号,
可以是BN、ReLU、池化、卷积组成的复合函数。
作为
层的输出。
ResNets. 传统的卷积是把前馈网络
层的输出作为
层的输入,产生了如下的转换关系:
。ResNets 添加一个skip-connection绕过非线性变换的特征函数:
resnets的优点是梯度直接通过identity function从后面层流向前面的层,然而,identity function和
输出求和可能阻碍网络中的信息流。
Dense connectivity. 为了进一步改善层之间的信息流,我们提出了不同的连接模式:我们引入了从任何层到所有后续层的直接连接。 图1展示出了由此产生的DenseNet的布局。 因此,第
层接收所有前面的层
的特征图作为输入:
其中,
是指在层
中产生的特征图的拼接。 由于密集的连接性,我们把这种网络结构称为密集卷积网络(DenseNet)。
Composite function. 我们定义
为三个连续操作的复合函数:批量归一化(BN),其次是(ReLU)和
卷积(Conv)。即,
Pooling layers.方程(2)中使用的连接操作在特征图的大小改变时是不可行的(第一步的dense connectivity,如果特征图的尺寸不一致,不能进行连接操作的)。 然而,卷积网络的一个重要组成部分是下采样层,它会改变特征图的大小。 为了适配这种下采样,我们将网络划分为多个密集连接的密集块,见图2。我们将块之间的层称为过渡层(transition layers),在过渡层对它们做卷积和池化。 在我们的实验中使用的过渡层由batch normalization层和
卷积层,然后是
平均池化层组成。
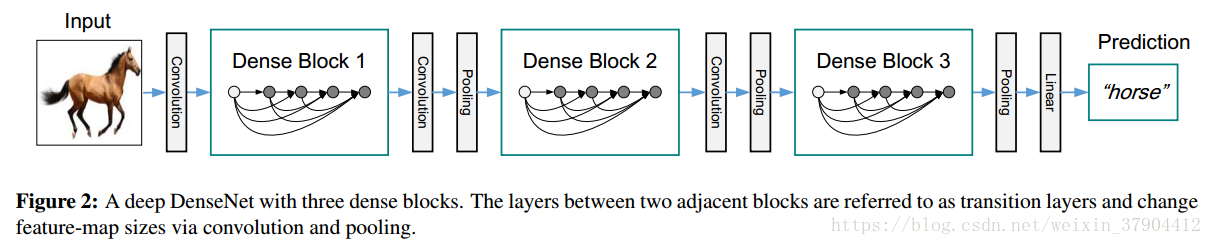
Growth rate.如果每个函数
产生
个特征图,由此可见,
层有
个输入特征图,其中
是输入层的通道数(如果是初始的RGB,
)。DenseNet和现有的网络体系结构的一个重要的区别是,DenseNet可以有很窄的层,例如,
。我们将超参数
作为网络的增长率。我们在第4节中提到,一个相对较小的增长率足以在我们测试的数据集上获得了最先进的结果。对此的一个解释是:每一层都可以访问其块中的所有前面的特征图,因此可以访问到网络的“集体知识”。 可以将特征图视为网络的全局状态。 每个层都将自己的
个特征图添加到这个状态。 增长率规定了每个层对全局状态贡献的新信息量。 全局状态一旦写入,就可以从网络中的任何地方访问,与传统的网络体系结构不同的是,并不需要一层一层地复制它。
Bottleneck layers.虽然每个层只输出
个特征图,但它通常有更多的输入。
的卷积可以作为Bottleneck layers在每3×3卷积之前减少输入特征图的数量(意思是降维),从而提高计算效率。我们发现这个设计对于DenseNet特别有效。我们将Bottleneck layers加入DenseNet中,称为DenseNet-B,即:
在我们的实验中,我们让每个
卷积产生
个特征图。
Compression.为了进一步提高模型的紧凑性,我们可以减少transition layers(过渡层)的特征图数量。 如果一个密集块包含
个特征图,我们让下面的过渡层产生
个输出特征图,其中,
被称为压缩因子。 当
时,过渡层上的特征图的数量保持不变。 我们称DenseNet的
为DenseNet-C,在实验中设定
。 当使用
的Bottleneck layers和transition layers时,我们将模型称为DenseNet-BC。
Implementation Details. 在除ImageNet以外的所有数据集上,我们实验中使用的DenseNet有三个密集块,每个块都有相同数量的层。在进入第一密集块之前,对输入图像进行卷积输出16通道的特征图(或DenseNet-BC增长率的两倍)。 对于卷积核大小为
的卷积层,输入的每一边都被填充一个像素以保持特征图大小的不变。我们使用
卷积,然后使用
平均池化作为两个连续密集块之间的过渡层。 在最后一个密集块的末尾,采用一个全局平均池化,然后附加一个softmax分类器。三个密集块中的特征图大小分别是
,
和
。 我们试验了配置分别为
,
和
的基本DenseNet结构。对于DenseNetBC,评估配置为
,
和
的网络。
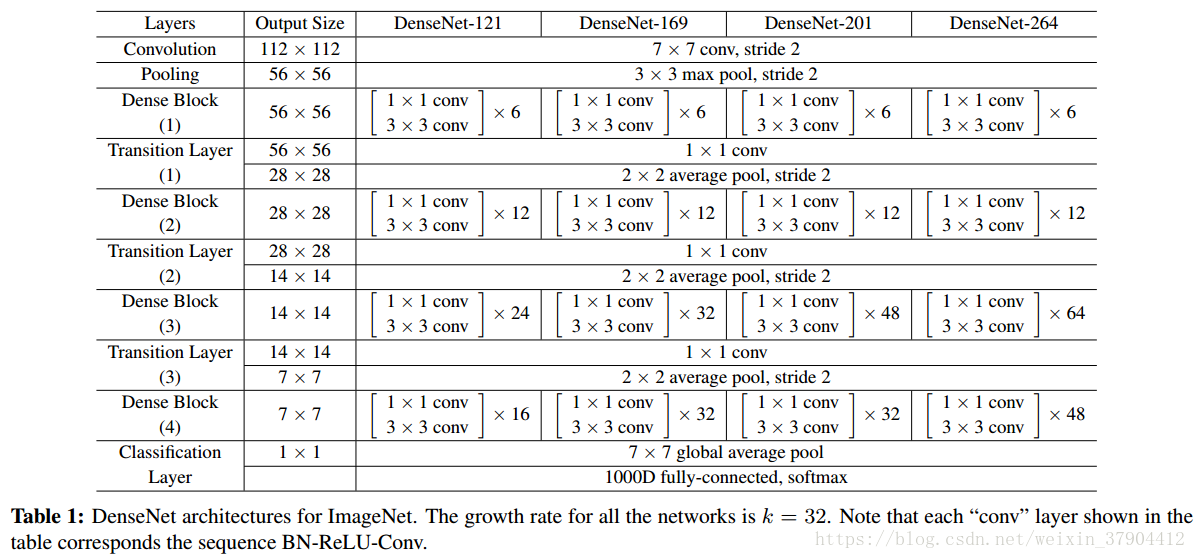
在ImageNet的实验中,我们使用了DenseNet-BC结构,在
的输入图像上有4个密集块。 初始卷积层包括为步长为2的
个
卷积的;所有其他层中的特征图的数量设置为
。我们在ImageNet上使用的确切网络配置如表1所示。
4 实验
我们验证了DenseNet在几个标准数据集上的有效性,并与现有的ResNet及其变体架构进行了比较。
4.1 数据集
CIFAR. 两个CIFAR数据集由32×32像素的彩色自然图像组成。 CIFAR-10(C10)由10个图像和100个类别的CIFAR-100(C100)组成。 训练和测试集合分别包含50,000和10,000个图像,并且我们有5000个训练图像作为验证集。我们采用广泛用于这两个数据集的标准数据增强方案(镜像/移位)。 我们用数据集名称末尾的“+”标记(例如C10 +)表示采用的数据增强。对于预处理,我们使用the channel means 和 standard deviations对数据进行归一化处理。 为了最后的运行,我们使用所有50,000张训练图像,并在训练结束时报告最终的测试错误。
SVHN. 街景房屋号码(SVHN)数据集包含32×32彩色数字图像。 训练集中有73,257幅图像,测试集中有26,032幅图像,531,131幅图像用于额外训练。按照惯例,我们使用所有的训练数据没有任何数据增强,并且从训练集中分离出具有6000个图像的验证集合。 我们选择训练期间验证错误最低的模型并报告测试错误。 我们并将像素值除以255,使其在[0,1]范围内。
ImageNet. ILSVRC 2012分类数据集包括来自1,000个类的120万个用于训练的图像和50,000个用于验证的图像。 我们采用与ResNet中相同的数据增强方案来训练图像,并且在测试时应用尺寸为224×224的single-crop 或 10-crop 。我们在验证集上报告分类错误。
4.2 训练
所有的网络都使用随机梯度下降(SGD)进行训练。 在CIFAR和SVHN上,我们用64 batch size 分别训练300和40轮。 最初的学习率设定为0.1,在训练时期总数中的50%和75%除以10。 在ImageNet上,采用batch size为256训练90轮。学习速率初始设置为0.1,在30和60轮时降低10倍。由于GPU内存的限制,我们最大的型号(DenseNet-161)以mini-batch size 128进行训练。为了弥补较小batch size,我们训练这个模型100轮,在90轮时采用除以10的学习率.
我们使用
的权重衰减和0.9的Nesterov动量,其中Nesterov动量不衰减。 我们采用由[10]引入的权重初始化。 对于没有数据增强的三个数据集,即C10,C100和SVHN,我们在每个卷积层(除了第一个卷积层)之后添加一个dropout层,并将丢失率设置为0.2。 测试错误仅针对每个任务和模型设置评估一次。
4.3 CIFAR和SVHN的分类结果
我们用不同的深度
和增长率
来训练DenseNets。 表2列出了CIFAR和SVHN的主要结果。为了突出总体趋势,我们将超过现有技术水平的以粗体显示,并以蓝色表示最好的结果。
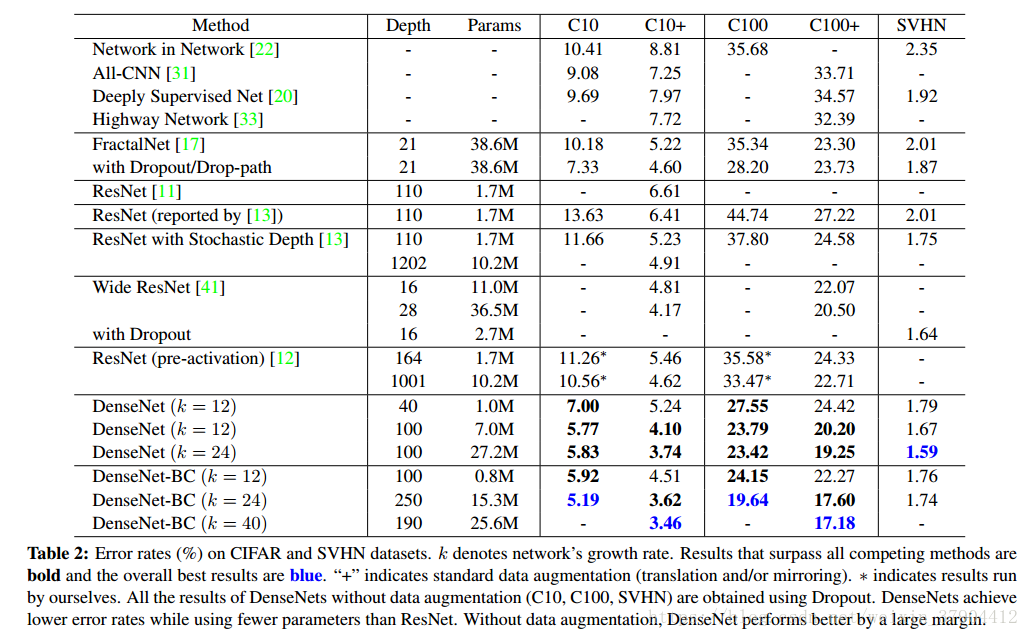
Accuracy.可能最明显的趋势可能起源于表2的最后一行,这表明在所有CIFAR数据集上,具有
和
的DenseNet-BC一致地优于现有技术水平。 它在C10 +上的错误率为3.46%,在C100 +上的错误率为17.18%,明显低于ResNet架构的错误率。我们在C10和C100上的最好结果(没有数据增加)更令人鼓舞:两者都比FractalNet低30%,并且具有drop path的正则化。 在SVHN上,当使用dropout层时,
和
的DenseNet也超过了ResNet所取得的最好结果。 然而,250层的DenseNet-BC并没有进一步改善其性能。 这可以解释为SVHN是一个相对容易的任务,而且深的模型可能会产生过拟合现象。
Capacity. 在没有压缩或Bottleneck layers的情况下,随着
和
增加,DenseNets表现出更好的性能。 我们把这主要归因于模型能力的相应增长。 这最好由C10 +和C100 +列表示。 在C10 +上,随着参数从1.0M增加到7.0M,再增加到27.2M,误差从5.24%下降到4.10%,最终下降到3.74%。在C100 +上,我们观察到了类似的趋势。 这表明DenseNets可以利用越来越深的模型的代表性力量。 这也表明它们不会出现过拟合或残余网络的优化困难。
Parameter Efficiency. 表2的结果表明,densenets利用参数比其他结构更有效(特别是resnets)。在过渡层的Bottleneck layers结构和降维densenet BC特别有效。例如,我们的250层模型只有15.3M的参数,但它一直优于其他模型,如FractalNet和Wide ResNets有超过30M的参数。 我们还强调,
和
的DenseNet-BC(例如,C10 +上的4.51%比4.62%,C100 +上的22.27%比22.71%) 与1001层预激活ResNet使用90%参数的可达到同等的性能。图4(右图)显示了这两个网络在C10 +上的训练损失和测试误差。 1001层深的ResNet收敛到较低的训练损失值,但有类似的测试错误。 我们在下面进行更详细地分析。
Overfitting. 更有效地使用参数的一个积极副作用是DenseNets不易过拟合。 我们观察到,在没有数据增强的数据集上,DenseNet体系结构相对于之前工作的改进尤其明显。 在C10上,这一改进使得错误率从7.33%降至5.19%,相对减少了29%。 在C100上,减幅从30%左右到28.20%再下降到19.64%。在我们的实验中,我们发现潜在的过拟合单一的设置:在C10,由增加k = 12到k = 24产生的参数的4倍增长导致误差从5.77%适度增加到5.83%。 DenseNet-BC bottleneck和压缩层似乎是对付这一趋势的有效方法。
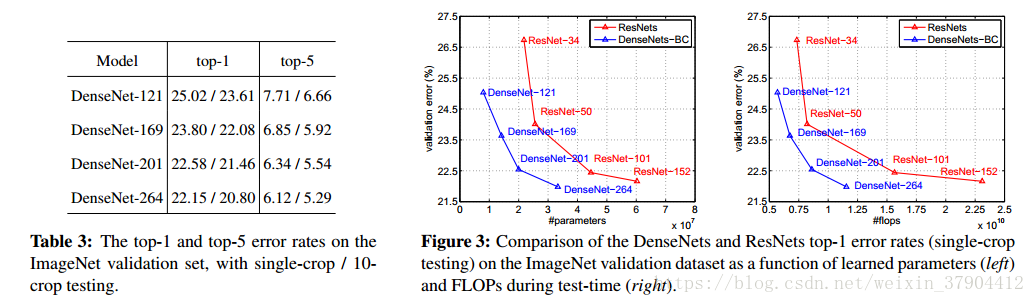
4.4 ImageNet的分类结果
我们在ImageNet分类任务中评估不同深度和增长率的DenseNet-BC,并将其与最先进的ResNet体系结构进行比较。 为了确保两种架构之间的公平比较,我们消除了所有其他因素,如数据预处理和优化设置的差异,采用[8]的ResNet的公开Torch实现。我们只需用DenseNet-BC网络替换ResNet模型,并保持所有的实验设置与用于ResNet的设置完全相同。 唯一的例外是,由于GPU内存限制,我们最大的DenseNet模型采用mini-batch size为128来进行训练,在训练这个模型100轮,第90次学习率下降,以补偿较小的batch size。我们在表3中的ImageNet上报告了DenseNets的single-crop和10-crop验证错误。图3显示了DenseNets和ResNets的single-crop top-1验证错误作为参数数量(左)和FLOP(右)。图中显示的结果表明,DenseNets与最先进的ResNet相媲美,同时需要显着减少的参数和计算来实现比较好的性能。 例如,具有20M参数模型的DenseNet-201产生与具有超过40M参数的101层ResNet相似的验证误差。从右侧面可以观察到类似的趋势,它将验证误差绘制为FLOP数量的函数:一个DenseNet需要尽可能多的ResNet-50执行与ResNet-101相同的计算,这需要两倍计算。
值得注意的是,我们的实验设置意味着我们使用为优化的ResNets而不是DenseNets超参数设置。 可以想像,通过最多两个或三个过渡层提供对所有层的直接监督。然而,损失函数和梯度densenets基本上不太复杂,因为同样的损失函数是各层之间共享。可以想象,更广泛的超参数搜索可以进一步提高ImageNet上DenseNet的性能。