基本思想:通过在模型里边,增加额外的偏移,来增强空间采样位置,并且从目标学习这个偏移,而不需要额外的标记。
本文第一次证明,在深度CNN,通过学习稠密的空间变换,对比较复杂的任务有有效的作用,比如目标检测,分割。
代码开源
目标检测的一个挑战就是:如何适应目标的尺度,位置,视角,部分变形的几何变换。通常来说有两种方法,数据增强,使用transformation-invariant features and algorithms。缺点:通过数据增强很难得到所有的变换;对特征不变的手动设计比较难。
由于CNN的固定的几何结构,CNN被限制到已知的变换。什么是CNN固定的几何结构?在固定位置的卷积;pooling的采样比率一定等。所以CNN内部是很难处理几何变换的。由于不同的目标大小不同,所以需要一个具有适应能力的感受野。
本文提出两种方法:
deformable convolution:给标准卷积的规则网格采样位置增加一个2D的偏移。允许采样网格的随意变形。如图1。通过额外的卷积层,从前边的特征图中学习偏移。因此,这种变形是在输入特征上,通过局部,稠密,自适应的方式来进行变形。

deformable RoI pooling:在先前的ROI池化的规则bin位置,对每个bin位置增加偏移。当然,偏移通过先前的特征和ROIs来学习,使得自适应不同形状目标的局部位置。
对偏移的学习所增加的参数和计算较少,可以很容易插入现有网络;很容易通过标准的反向传播进行端对端训练。
可变形卷积架构:CNN中,特征图是3D的,但是我们在2D空间进行操作,通道之间的操作是一样的。(论文称步长为dilation)
deformable convolution如图2,
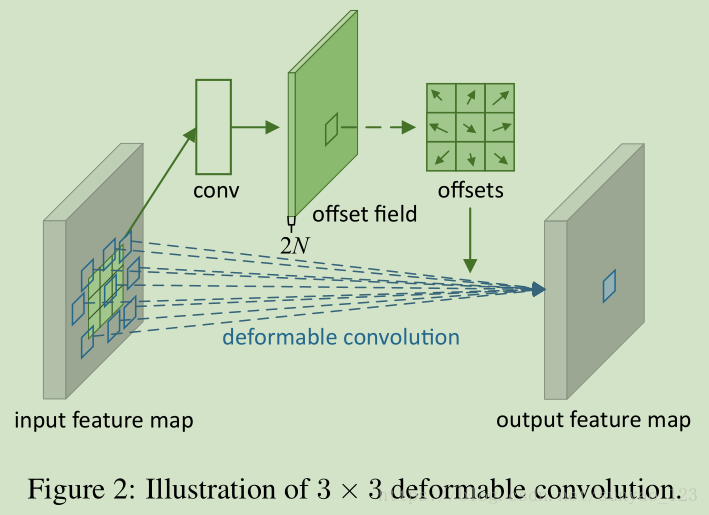
输入特征的通道N,经过卷积后生成2N个通道,最后得到经过变形的N个特征图。其实这个过程并没有对特征图进行卷积运算。所谓的可变形卷积是对特征图进行变换,再经过正常的卷积后,才算是完成一个完整的变形运算。那么上边这个卷积是干啥的呢?为啥要输出2N个通道的特征图呢?其实,上边卷积生成的2N个特征图,是为了计算输入N个特征图中每个像素的位置偏移,因为是x和y两个方向的偏移,所以要产生2倍的通道数。最终的结果是,输出的N个特征图中,相关的像素被移到了一块,所以通过正常的卷积就相当于是变形的卷积核对原始输入特征图中相关的像素进行卷积了。而不是真的把卷积核变成各种各样的形状进行卷积。
deformable RoI pooling如图3,
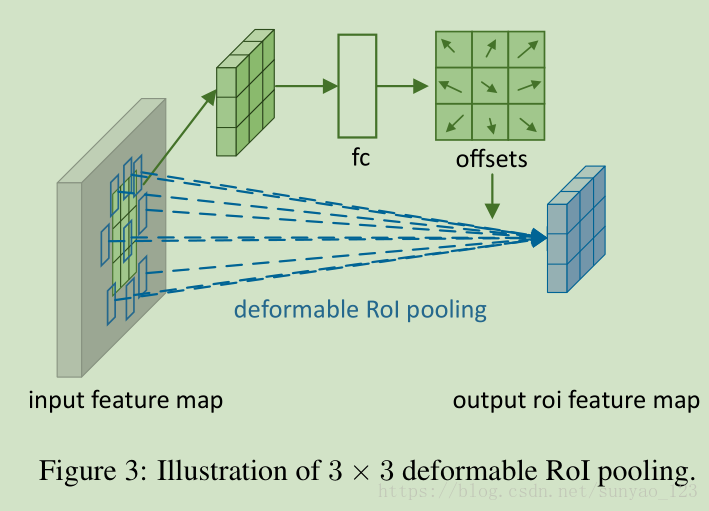
首先将输入特征图进行ROI pooling,然后通过全连接层进行偏移的预测,得到偏移后的特征图,最后通过ROI pooling得到最终的特征图。
这两个不同之处在于一个是通过卷积学习位置偏移,一个是通过全连接学习位置偏移。
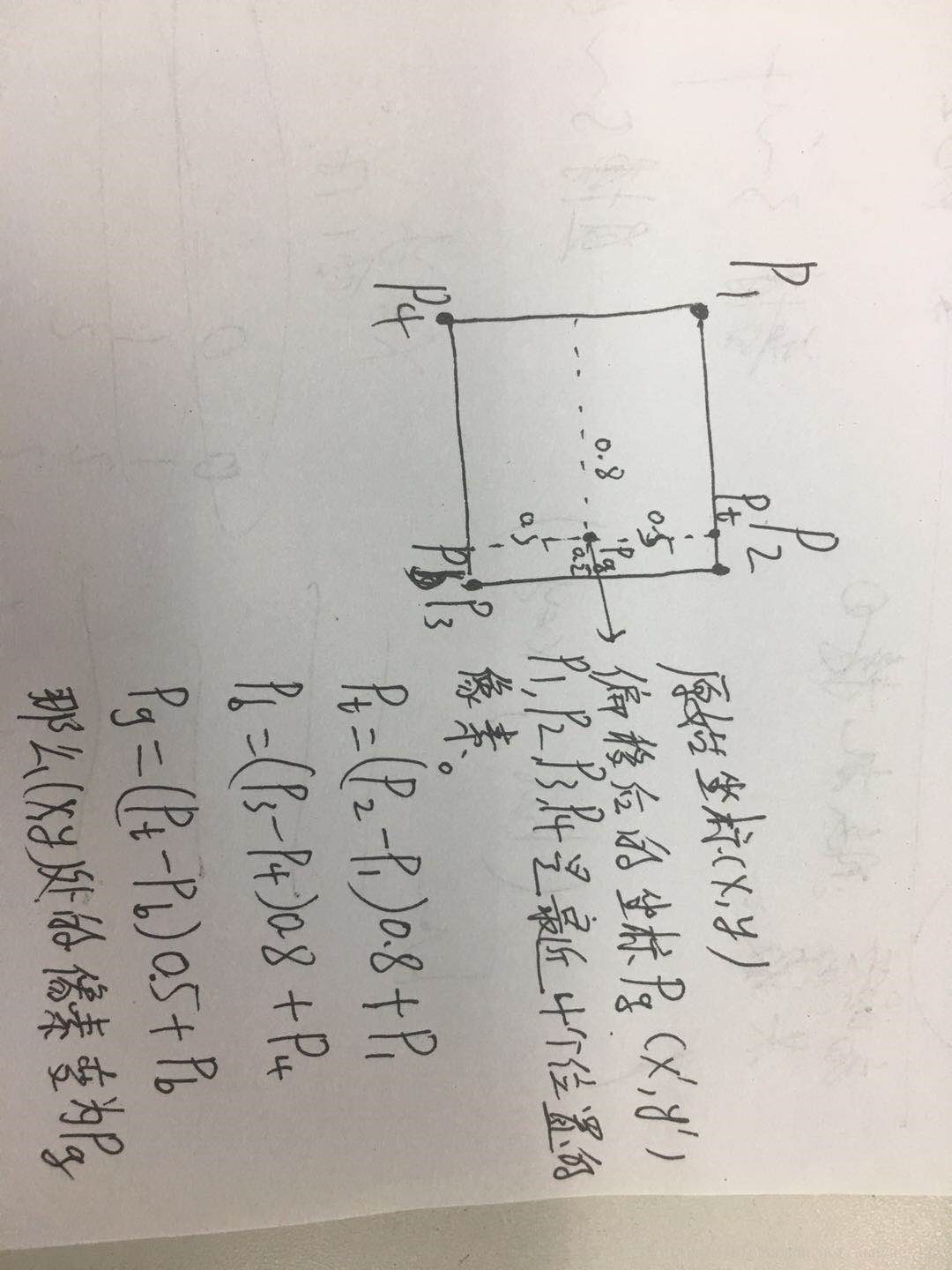
由于经过偏移后的位置是小数,怎么办呢?这时就用到了双线性插值。我们首先得到每个像素经过偏移后的的坐标,找到离这个坐标最近的4个像素,对这4个像素进行双线性插值得到我们这个位置改变后的像素。所有的输入特征图经过这样的步骤之后,得到的新的特征图的每个位置的像素已经改变了,相当于把形似的像素汇集到一起。
双线性插值