
文章目录
1. Motivation
由于CNNs固定的几何结构,它们在建模几何变化中受到了限制。
Convolutional neural networks (CNNs) are inherently limited to model geometric transformations due to the fixed geometric structures in their building modules.
视觉识别中的一个关键挑战是如何在对象比例,姿势,视点和零件变形中适应几何变化或模型几何变换,传统的方法有以下2种:
A key challenge in visual recognition is how to accommodate geometric variations or model geometric transformations in object scale, pose, viewpoint, and part deformation.
-
第一种方法是建立具有足够理想变化的训练数据集,这个通常对训练数据进行数据增强来实现,但是这会增加昂贵的训练和复杂的模型参数。
-
第二个方法是使用变换不变性特征和算法,例如SIFT(scale invariant feature transform)和建立在目标检测器中的滑动窗口方法。
但是这2个方法都存在2个drawbacks。首先,假设几何变换是固定的并且是已知的。这种假设组织了对于新任务处理位置的集合变化的泛化性。其次,手工设计的特征不变性和算法难以应对复杂的变换,即使它们是已知的。
CNNs也具有以上2种drawbacks,CNNs受到大模型位置变换的限制,这些限制来源于CNN模块固定的几何特征:卷积层中卷积核在输入特征图上固定的位置上进行采样,池化层通过固定的比例来减少spatial resolution,RoI Pooling层将一个RoI分离成固定的bins等等。
这些都缺乏geometric transformations。这就有2个问题:
For one example, the receptive field sizes of all activation units in the same CNN layer are the same.
For another example, while object detection has seen significant and rapid progress [14, 47, 13, 42, 41, 36, 6] recently, all approaches still rely on the primitive bounding box based feature extraction. This is sub-optimal, especially for non-rigid objects.
2. Contribution
在本文中,作者提出了2个新的模块,可以极大的增强CNNs对于建模几何变换的能力。
第一个是deformable convolution,对于标准的2D卷积中,在标准的网格采样的locations加入了2D offsets,如图1所示。offsets通过先前的特征图以及额外添加的卷积层得到。因此,可变的方式是以一种local,dense和adaptive的准则建立在输入的特征上。
第二个是deformable RoI pooling,它对于每一个RoI Pooling中的每一个bin所在的position添加了offset,与deformable convolution类似,offsets是通过前者特征图学习到的,使得不同形状的object都可以变化自适应的localization。
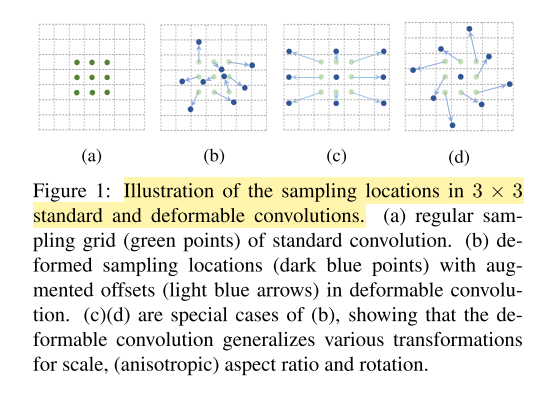
3. Deformable Convolutional Networks
3.1 Deformable Convolution
普通的2D卷积操作包含2个步骤。
- 通过一个规则的网格R来对整个输入的特征图x进行sampling。
- 接着通过卷积核权重w来对采样值values进行加权。
其中R表示卷积核的大小,左上角为 ( − 1 , − 1 ) (-1, -1) (−1,−1),右下角为 ( 1 , 1 ) (1, 1) (1,1)。。其中 p n p_n pn表示R中的所有位置。普通的卷积操作由公式1和公式2所示:
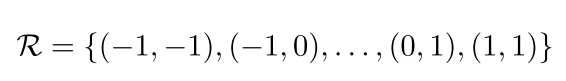
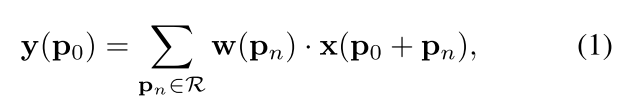
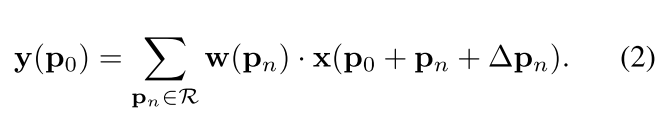
在可变卷积中,R利用offsets { Δ p n ∣ n = 1 , . . . , N } \{\Delta p_n |n=1,...,N \} { Δpn∣n=1,...,N}进行增强,其中 N = ∣ R ∣ N=|R| N=∣R∣,sampling是在不规则并且偏移的位置上 p n + Δ p n p_n+\Delta p_n pn+Δpn进行的, Δ p n \Delta p_n Δpn表示偏移(通过图2的offset field得到)。其中, p = p 0 + p n + Δ p n p=p_0+p_n + \Delta p_n p=p0+pn+Δpn,q表示特征图X上所有的spatial locations。原公式2通过双线性插值变换为公式3,表示如下:
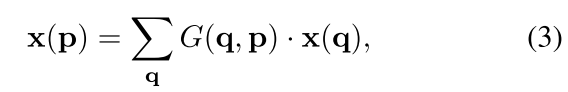
其中 G ( ⋅ ) G(\cdot) G(⋅)是双线性插值kernel,由于G是包含x与y的2维的,计算偏移后的p对于特征图x上的每一个location q q q的双线性插值,接着在乘上原特征图上q上的特征值,最后将所有的 G ( q , p ) ⋅ x ( q ) G(q,p) \cdot x(q) G(q,p)⋅x(q)相加起来。对于双线性插值kernelG, G ( q , p ) G(q,p) G(q,p)可以展开为公式4:
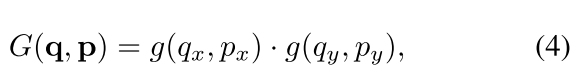
其中 g ( a , b ) = m a x ( 0 , 1 − ∣ a − b ∣ ) g(a,b)=max(0, 1-|a-b|) g(a,b)=max(0,1−∣a−b∣)。我的理解是根据 g ( a , b ) > 0 g(a,b)>0 g(a,b)>0可以得知, ∣ a − b ∣ < 1 |a-b|<1 ∣a−b∣<1,也就是就是围绕在q周围的距离为1的所有的pixels。因此,公式3计算的比较快的(但是要遍历所有的像素点,这一点search比较慢),因为 G ( q , p ) G(q,p) G(q,p)只对于一部分qs是non-zero的。
如图2所示,offsets是通过在input feature map上添加的卷积核得到的。卷积核的spatial resolution和dilation都是和普通的卷积核一样的,例如论文中使用 3 × 3 3 \times 3 3×3,dilation为1的卷积核。通过这一步得到的offset fileds的特征图大小为 H × W × 2 N H \times W \times 2N H×W×2N,其中offset field的和input feature map的spatial resolution大小相同。而channel为2N(在这里N=3x3=9,也就是对于与卷积核进行卷积操作的9个pixels,要计算它们的x和y方向上的偏移,因此是2 x 9 = 18)。在训练中,产生输出特征的卷积核以及偏移都是同时进行学习。为了学习偏移,梯度通过公式3和公式4进行反向传播。
3.2 Deformable RoI Pooling
在通常的RoI Pooling,RoI pooling将大小为 w × h w \times h w×h的RoIRoI分割为了 k × k k \times k k×k的bins,并且输出 k × k k \times k k×k的feature map y,其中对于第(i,j)个的bin的特征图y的值用公式5表示:
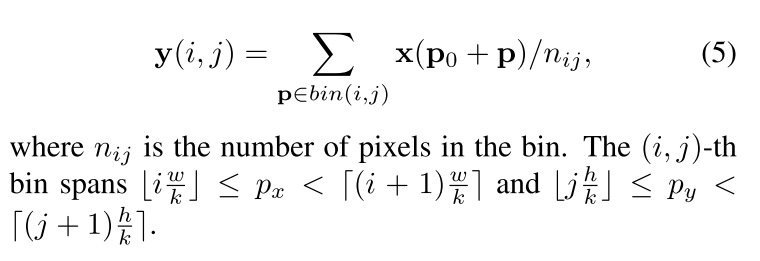
对于Deformable RoI Pooling,对于每一个bin,都有一个offsets { Δ p i , j ∣ 0 ⩽ i , j < k } \{\Delta p_{i,j}|0 \leqslant i,j < k \} { Δpi,j∣0⩽i,j<k},一共有k x k个bin的offsets。公式5可以转变为公式6,表示如下:
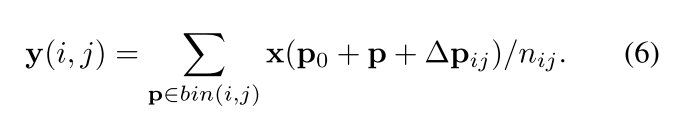
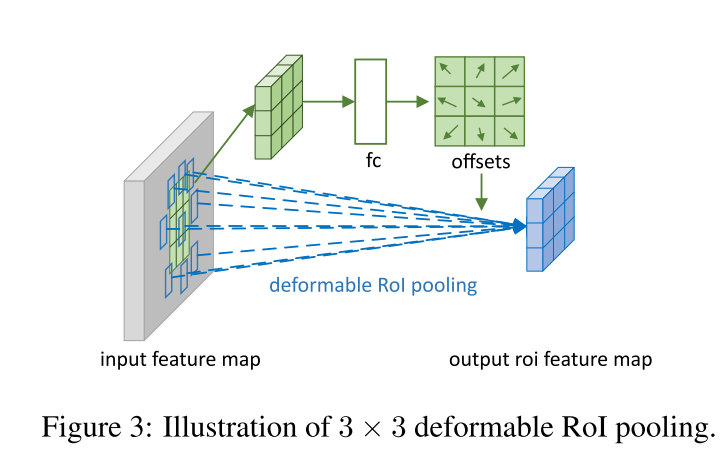
公式6同样通过公式3和公式4的双线性插值来实现。图3描述了如何获得offsets,首先,RoI Pooling通过公式5,来产生经过pool后的特征图。接着从池化后的特征图上,使用一个fc层(eg. channel维度变化为256 --> 2,输出为k x k x 2)来产生正则化的偏移 Δ p ^ i j \Delta \hat p_{ij} Δp^ij。然后通过 Δ p i , j = γ ⋅ Δ p ^ i , j ⋅ ( w , h ) \Delta p_{i,j}=\gamma \cdot \Delta \hat p_{i,j} \cdot (w,h) Δpi,j=γ⋅Δp^i,j⋅(w,h)转换为公式6中的 Δ P i j \Delta P_{ij} ΔPij。
The offset normalization is necessary to make the offset learning invariant to RoI size.
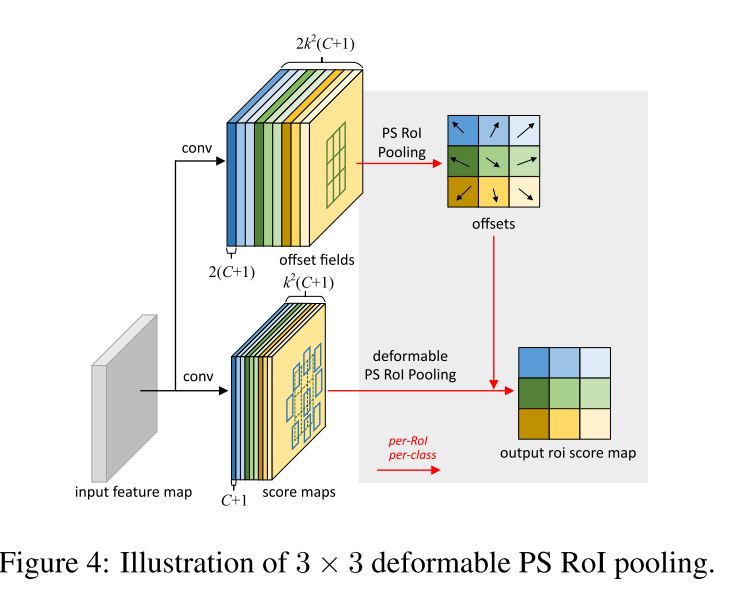
3.3 Position-Sensitive (PS) RoI Pooling
In short, the difference from RoI pooling in Eq.(5) is that a general feature map x is replaced by a specific positive-sensitive score map xi,j.

3.4 Deformable ConvNets

