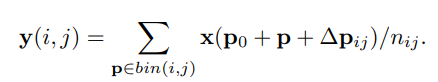1.简介
偶然了解到了可形变卷积这篇文章,看了几篇博文后大致了解的差不多了,但是有些细节还是看了代码之后才理解。这里想自己写一下关于这篇论文的了解,希望自己能够讲清楚。这里放一篇写的很好地博文链接,想更深入了解代码的可以去看一下。DCN可形变卷积实现1:Python实现_可变形卷积pytorch_Adenialzz的博客-CSDN博客
这里先放一下原文的摘要:
卷积神经网络(cnn)由于其构建模块中固定的几何结构,固有地局限于模拟几何变换。在这项工作中,我们引入了两个新的模块来增强cnn的变换建模能力,即形变卷积和形变RoI池。两者都是基于用额外的偏移量来增加模块中的空间采样位置,并在没有额外监督的情况下从目标任务中学习偏移量的想法。新的模块可以很容易地取代现有cnn中的普通模块,并且可以很容易地通过标准反向传播进行端到端训练,从而产生可形变的卷积网络。大量的实验验证了我们的方法的性能。我们首次证明了在深度cnn中学习密集空间变换对于复杂的视觉任务(如目标检测和语义分割)是有效的。
2.可形变卷积的原理
其实可形变卷积并不是改变卷积核,卷积核一直都是3x3大小的,里面的权重也是通过训练得到的,可以就看成一个正方形。变得其实是与之做卷积操作的原特征图的像素值。
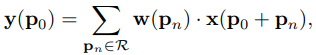
![]()
一个普通的卷积操作的流程是什么,一个3x3的卷积核,规律的以固定的步长移动窗口,对每个窗口内的原特征图的像素值进行相乘求和,输出一个值。第一个公式就是普通卷积的公式,y中的p0代表输出特征图的某一个点,x中的p0代表这个点对应的卷积核在原特征图中作用时的中心点坐标。下面我画的图能够很好地理解这一点,Pn是卷积核相对于P0的坐标,从(-1,-1)到(1,1),其中也包括(0,0)。所以先确定P0的坐标x,y,这样通过相对坐标Pn就能够遍历卷积核范围内的像素值了。
可形变卷积的操作其实就变了一个地方,就是原特征图的像素值,他不再是输入特征图的那个位置的像素值,而是经过网络学习后,其他地方的像素值。举个例子,原特征图位置(1,1)的像素值是150,正常卷积就是当窗口里有(1,1)时,就将卷积核对应位置的权重乘上150。但是可变性卷积不是,网络经过学习产生一个偏移值,假如偏移值(x,y)是(2,3),这样(1,1)+(2,3)=(3,4),若位置(3,4)的像素值为20。这时原特征图中位置(1,1)的像素值就不是150,而是20了。当卷积核窗口里包含(1,1)时,是按照20来计算的。
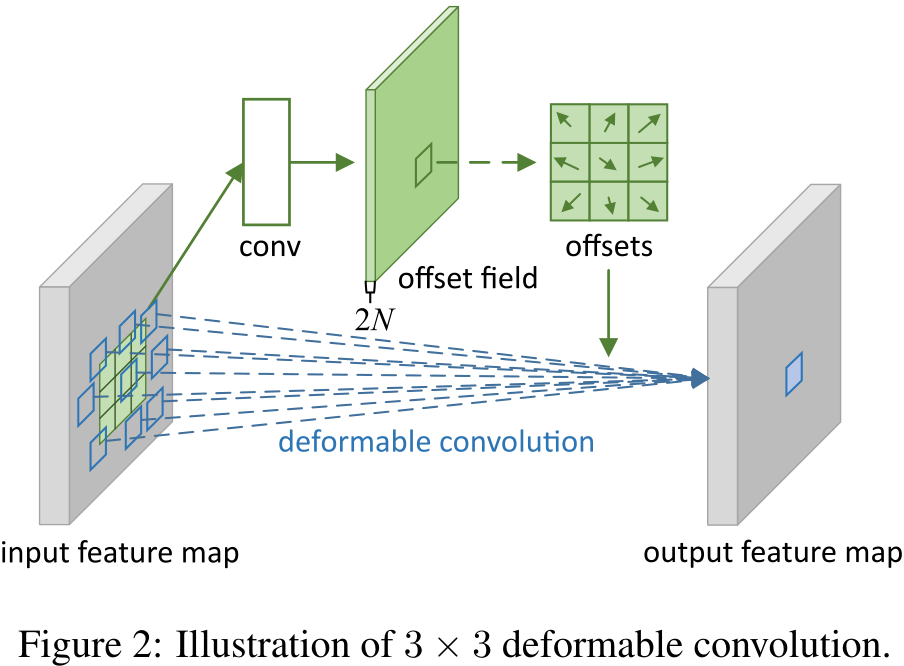
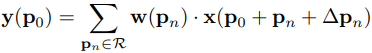
上图就是可形变卷积的操作示意图,先将原特征图卷积得到一个通道数为2N的特征图,这一步是在求偏移值。N是kernal_size*kernal_size,乘2是因为偏移值具有x方向和y方向。然后将这个2N通道的offsets加到原卷积公式中去,就得到了偏移后的坐标。

但是偏移后的坐标基本上都是小数,所以想要确定该坐标的像素值,就需要双线性插值的操作。下面的公式就是文章给出的双线性差值的公式。最后再通过3x3步长为三的卷积操作得到最后与输入特征图shape相同的输出特征图。
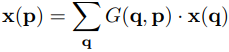
3.可形变ROI池化
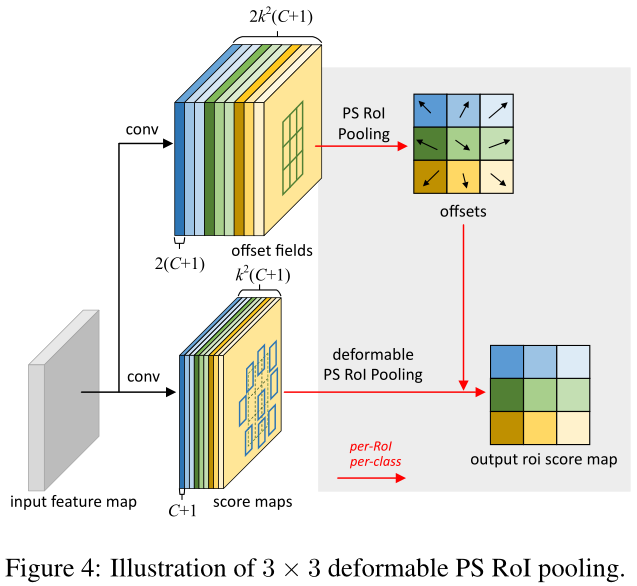
k是输入特征图的尺寸,滑动窗口时产生k 2 k^2k 2个scroe map, 每个score map包括C类物体和1个背景的结果,2同样是offsets的x,y两个值。普通ROI池化公式为:
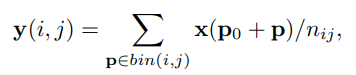
可形变的ROI池化公式为: