ps好久没更新博客了,主要之前想把grt团队代码加入fpn,然后多尺度下预测.没成想玩崩了.结果很不正常.调了很多参数都不行(主要改了模型,多尺度标签,多尺度损失函数等等相应问题).后来有点其他事要忙.
上周之前刚把降假阳性的3dcnn模型搞定(还要用3dunet降假阳性(联合),没写),趁着训练的时候看下之后可能用到的网络.Deformable ConvNets其实我是先看到了V2,总体明白但有些细节的东西感觉总是似懂非懂.尝试了看代码,但也是一个头两个大.那么我先看第一个版本就是V1.
一开始找的资料也都是翻译的还有就是稍微结合点代码说的.但是我还是很懵逼.比如其中一步很重要的就是双线性插值怎么就形变了(不理解).后来我找了DFann大神的这篇博客https://blog.csdn.net/u011974639/article/details/79675408从头教你什么是仿射变换.一下子就明白了原来矩阵的缩放旋转(旋转不直观,我还去证明了下,有兴趣的可以去试试最好知其所以然)平移可以由乘以一个列向量来实现也就是放射变换.
而且DFann大神还提供了代码,我花了不少时间调试查看中间值才明白了代码的实现放射变换的方式.
放射变换简单来说:(主要思想)
1.建两个代表xy2维坐标位置的两个矩阵X和Y,大小为特征矩阵大小
# 创建棋盘grid,平分整个图片 x = np.linspace(-1, 1, width) y = np.linspace(-1, 1, height) x_t, y_t = np.meshgrid(x, y)
2.X和Y压成两列,再加一列1可实现放射变换时的平移,再乘以放射矩阵.
# 制作原始坐标点的列向量(xt, yt, 1)
ones = np.ones(np.prod(x_t.shape))
sampling_grid = np.vstack([x_t.flatten(), y_t.flatten(), ones])
# 把所有像素整到一起 sampling_grid的shape为(batch, 3, H*W)
sampling_grid = np.resize(sampling_grid, (num_batch, 3, height*width)) # 列向量扩展batch
# 做仿射矩阵运算 M*K
batch_grids = np.matmul(M, sampling_grid)
# batch grid 的 shape (num_batch, 2, H*W)
3.根据得到的仿射变换后的矩阵进行一系列变换维度,取整,重构维度等操作,获得X和Y对应网格内的值填入(其中包括双线性插值,坐标超出图片范围的取0)
Spatial Transfomer Networks
顺势大神又在https://blog.csdn.net/u011974639/article/details/79681455讲了STN
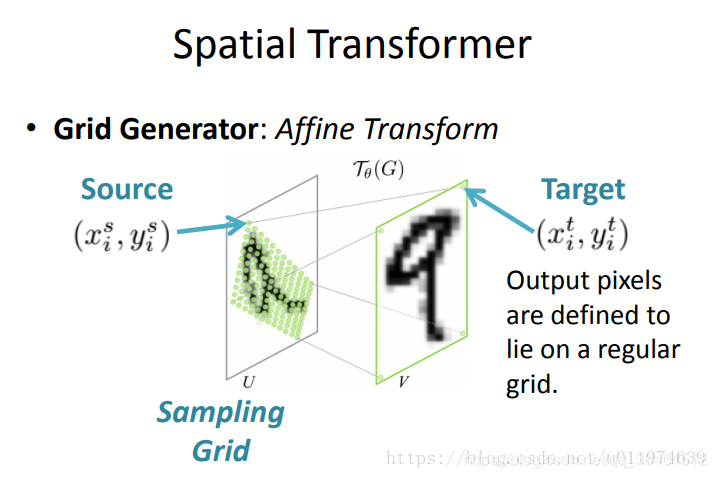
1.先用一个网络同卷积或乘积得到2维矩阵放射变换的参数(x,y放在一起了)下图中2*3矩阵.

2.接着输出采样网格,即在输入中采样的点生成期望的转换输出.就是上图的target(其实上图source,target理论上换一下也是ok的)
3.第三步就是双线性差值获得采样网格点的值.如下图
Deformable ConvNets
现在就可以再次理解的我们的正题了,DCN和STN都是具有内部转换参数和学习参数,都是纯粹的学习数据。deformable ConvNets相比的来讲,是更简单、有效,深度和端对端的训练。相比于STN学习一组仿射变换参数,Deformable学习卷积核中各个采样点的偏移量。与此相对的常规的扩张卷积是固定的偏移量。所以更加简单.
这里再截取大神mykeylock的博客https://blog.csdn.net/mykeylock/article/details/77746499的一段话:
可变形卷积很好理解,但如何实现呢?实现方面需要关注两个限制:
1、如何将它变成单独的一个层,而不影响别的层;
2、在前向传播实现可变性卷积中,如何能有效地进行反向传播。
这两个问题的答案分别是:
1、在实际操作时,并不是真正地把卷积核进行扩展,而是对卷积前图片的像素重新整合,
变相地实现卷积核的扩张;
2、在图片像素整合时,需要对像素进行偏移操作,偏移量的生成会产生浮点数类型,
而偏移量又必须转换为整形,直接对偏移量取整的话无法进行反向传播,这时采用双线性差值的方式来得到对应的像素。
——————————————————————————————————————————
可变性卷积的流程为:
1、原始图片batch(大小为b*h*w*c),记为U,经过一个普通卷积,卷积填充为same,即输出输入大小不变,
对应的输出结果为(b*h*w*2c),记为V,输出的结果是指原图片batch中每个像素的偏移量(x偏移与y偏移,因此为2c)。
2、将U中图片的像素索引值与V相加,得到偏移后的position(即在原始图片U中的坐标值),需要将position值限定为图片大小以内。
position的大小为(b*h*w*2c),但position只是一个坐标值,而且还是float类型的,我们需要这些float类型的坐标值获取像素。
3、例,取一个坐标值(a,b),将其转换为四个整数,floor(a), ceil(a), floor(b), ceil(b),将这四个整数进行整合,
得到四对坐标(floor(a),floor(b)), ((floor(a),ceil(b)), ((ceil(a),floor(b)), ((ceil(a),ceil(b))。这四对坐标每个坐标都对应U
中的一个像素值,而我们需要得到(a,b)的像素值,这里采用双线性差值的方式计算
(一方面得到的像素准确,另一方面可以进行反向传播)。
4、在得到position的所有像素后,即得到了一个新图片M,将这个新图片M作为输入数据输入到别的层中,如普通卷积。
---------------------
不过在理解1的时候还有冲突,卷积后的(b*h*w*2c)中c有的仅仅是认为是输入特征图的通道数,有的认为是形变卷积核的大小决定的(3*3=9,c=9).不过看代码好像是一种,看论文更像是后一种.