机器学习技法 Lecture1: Linear Support Vector Machine
Large-Margin Separating Hyperplane
回忆之前讲过的线性分类模型,使用的是一个加权求和的形式通过一个超平面将正负例分隔开。
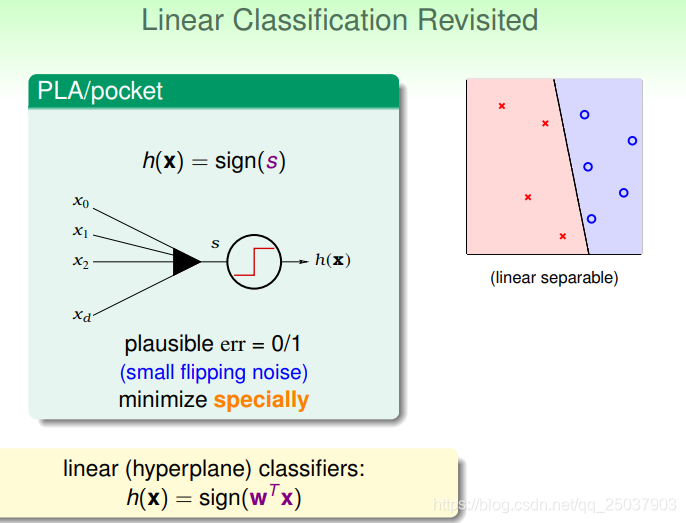
使用PLA算法或是类似的算法,得出来的是一个合理的结果。但是可能存在无数个合理的结果,这些结果里哪一个又是最好的呢?

这样的情况之前讲的算法和VC bound都没有办法区分开来。但是对于人眼来说可能会选出最右边的是最好的分隔。

有一个不太正式但是方便理解的解释是说,如果实际中的点是根据高斯分布均匀分布在原来的训练集的点周围,那么最右边的点能够容忍最大的噪声存在,也就因此有了最强的健壮性。
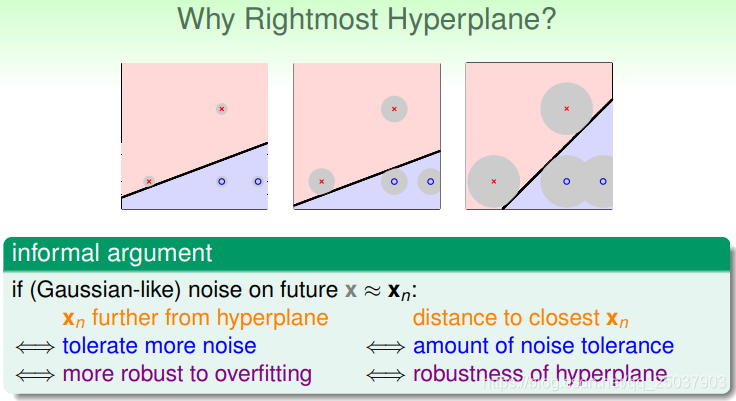
所以说这个结果的健壮性可能与靠近分隔面最近的点到分隔面的距离有关。加入现在得到的结果是一个有宽度的线或者面,那么它的宽度就代表了最终结果的健壮性。如下图所示,最右边的图有最粗的分隔面。

因此我们想要的目标就变为找到最宽的分隔面。而这个宽度实际上指的是最近的点x到这个分隔面的距离,也就是margin。因此这个问题可以形式化为如下形式:
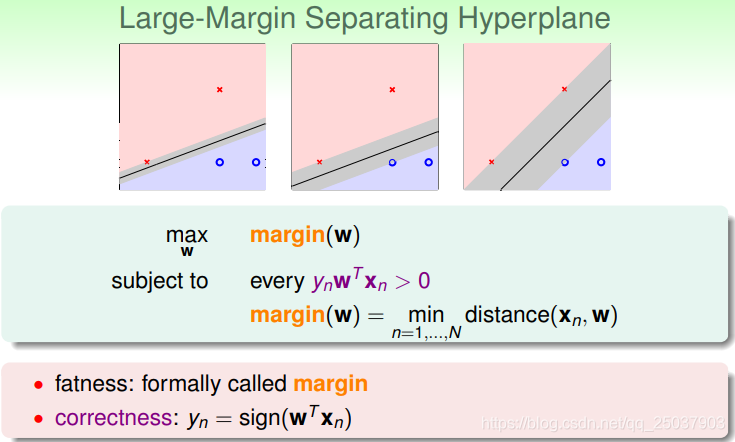
也就是找到一个系数w使得在训练集里距离分隔面最近的点到分隔面的距离margin最大。
Standard Large-Margin Problem
首先回顾一下求点到平面距离的方法。把截距 从w向量里拿出来写为b。
- 假设平面上存在一个点 ,那么这个点符合公式 。
- 将平面外的点 与 连为一条线,那么这个点x到平面的距离可以用线段 投影到法向量 上的部分来表示。
- 也就是
。

在这个线性分类的问题中,对于每个n来说 ,利用这点可以将求距离中的绝对值换掉,也就是 。
因此整个求最好的分隔面的问题可以写为:

因为这个线性分隔面的等式是可以任意放缩的,也就是将等式同时乘上一个系数不会改变结果,即:

设定最小的那个点带入公式后
,因此最优化的目标就变成了
。又因为设定了最小的点带入结果为1之后自动满足了
的限制条件,因此当前的限制条件只有一个了:

而这个等式的还带着min符号的约束很难来求解,因此想办法来放缩为一个更宽松的限制:对于所有的n,
。但是想要放缩成这个条件需要证明这个条件下得到的结果与原条件一样。使用反证法证明如下:

也就是说得到的结果肯定还是在原来的限制条件范围内的。
同时我们把最大化一个倒数改为最小化这个值本身,去掉求模长的根号再加上一个系数,最终得到了问题的标准形式:
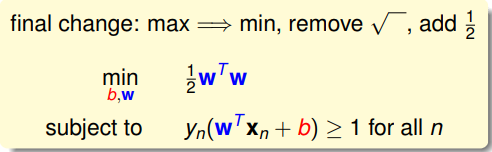
Support Vector Machine
首先来接一个具体的例子,比如有四个点分别对应着结果,通过简单的不等式加减得到最终的结果:

因此最终的结果为:

在这个例子中我们发现,只有距离分隔面最近的三个点起了作用,其他位置的点无论有多少都不会提供给我们任何信息也不会改变结果。因此我们把这些落在限制条件上的会改变结果的点叫做support vector。也是因此这个最优化问题叫做support vector machine。
那么如何来解一般形式的SVM呢?

显然用梯度下降法来进行计算没法做。但是很幸运的是这个问题在凸优化里是一个已经被解决的问题,叫做二次规划问题(quadratic Programming)。是一个简单的优化问题。于是我们只需要将其写为QP的形式使用固定的解法求解即可。

系数对应写起来也比较简单,最终使用QP来解SVM问题的算法过程如下:

hard-margin指的是能够完全分隔开不同类别的点。而Linear指的是这是个在x平面上的线性分类器。如果想要非线性结果需要使用映射函数
。
Reasons behind Large-Margin Hyperplane
现在来探讨一下比较大的margin代表什么意思。如果把SVM算法与正则化的形式相比会得到一个有趣的结果,它们之间的目标和限制条件是相反的:

从对比结果可以看到,其实可以把SVM算法看作是一个限制了
的weighted decay的正则化过程。
另一种解释可以从VC维的方面来看。假如有一个算法返回的是margin大于一个值
的分隔面结果。

那么这个值可能就会影响到分隔面能够shatter的点的数量:
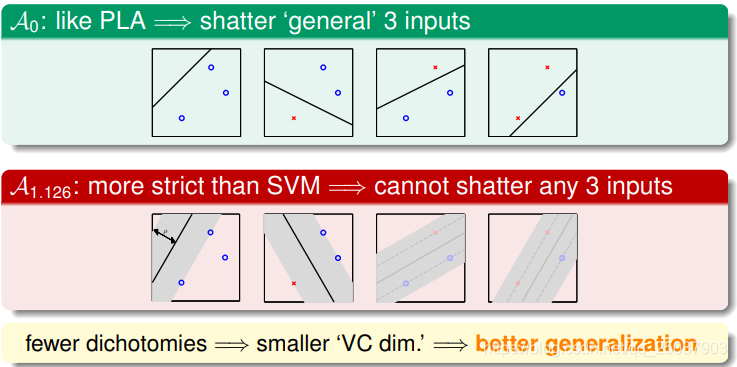
而更少的dichotomies代表的是更小的VC维,可能也就代表了更好的泛化结果。
不过我们没有讲过一个算法的VC维如何定义,讲过的只是一个假设集合的VC维。算法的VC维可以看成是满足了一些条件的,依赖于数据的一种VC维。而对于Large-Margin Algorithm来说,它的VC维在x满足一个分布时可以写为如下形式:

现在我们学了新的模型元素,可以看到不同的元素能够带来不同数量的假设函数:

能导致比较少的假设数量的方法对于泛化性能是比较好的。但是比较多的假设数量的方法能带来比较复杂的分隔面,更易于搜寻到一个更好的
。而现在我们有了一个新的组合方式,把这几个元素组合起来得到新的模型:
