Preface
本文对于SVM(Support Vector Machine,支持向量机)的做了一些准备工作,并在接下来的几篇文章正式初步学习SVM。
主要内容:
Notation(符号约定)
Functional Margins And Geometric Margins(函数间隔和几何间隔 )
Optimal Margin Classifier(最有间隔分类器)
Primal Problem(原始问题)
Dual Optimization Problem(对偶优化问题)
Notation
在SVM学习中我们将改变之前的学习习惯:
- 分类标识由 ,来作为分类的标识来区分不同类别。例如 标识类别一, 标识类别二。
- 假设函数由
。
其中, 中的w与b分别对应于 中的对应关系为:
Functional Margins
定义:一个超平面 和某个特定的训练样本 相关的函数间隔为:
超平面 表示的是由参数 确定的分界。
如果需要
获得一个较大的值,那么:
当
时,需要
远大于0;
当
时,需要
远小于0;
以及当 时,我们认为分类结果是正确的。
定义:一个超平面 和整个的训练集中的所有训练样本 相关的函数间隔为:
Geometric Margins
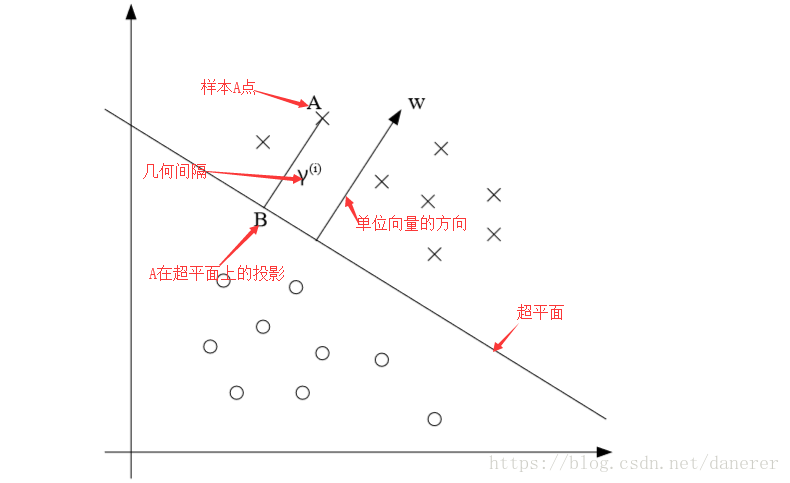
通过上图我们可以知道,一个样本
A点到超平面
的几何间隔为
,且
为超平面
指向A点方向的单位向量,A点
在超平面
上的投影B点为:
同时,由于B在超平面上,所以:
- 注: 。
所以,我们可以得出几何间隔为 :
由于我们总是考虑对训练样本的争取分类,所以将几何间隔为 一般化为:
如果 , 。更一般的有, 。
定义:一个超平面 和整个的训练集中的所有训练样本 相关的几何间隔为:
Optimal Margin Classifier
最优间隔是指调整参数 使得几何间隔 最大。
Step1:条件假设
,
,
只需要选一个条件。
对于上述条件的解释:
调整参数
对于超平面
无影响,例如将
扩大两倍
得到
,即超平面位置不发生变化。所以我们可以通过缩放
来满足上述条件。
表示
的第一个位置的数字为1。
Step2:公式推演
首先看看函数间隔,你给参数前乘一个大于零的数,函数间隔就会变大,这个不好。再来看看几何间隔,由于要将参数单位化,所以就不受参数的非因素影响,就是说当几何间隔最大的时候,真的就是训练样本距离超平面最大。这样用几何间隔就可以非常健壮的描述样本与超平面之间的距离。
形式一:
形式二:
形式三:
Lagrange Duality
我们会使用拉格朗日乘数法来解决关于约束优化问题:
我们的目标函数是:
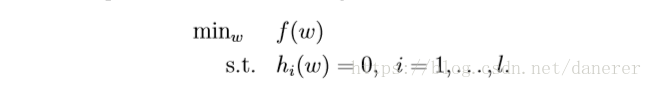
接下来我们构造拉格朗日算子:
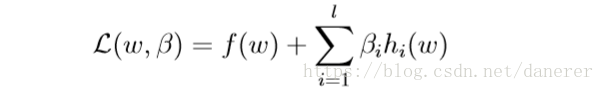
然后分别对参数进行求导,并令其为零:
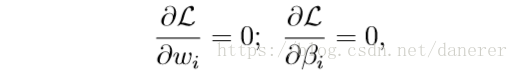
然后解上述等式构成的方程组,求得
。最后将
带回到目标函数。
Primal Problem
在这里我们构造出原始优化问题的目标函数:
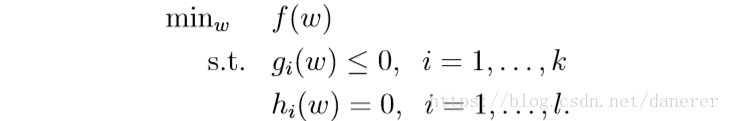
现在我们开始使用拉格朗日乘数法来解决原始优化问题:
我们定义一个增广拉格朗日函数,在这里
与
为拉格朗日乘数:
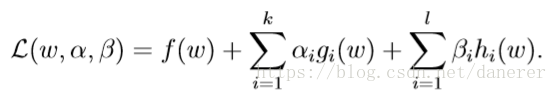
定义一个
函数,这里的下标p表示primal:
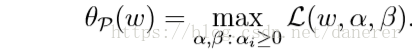
所以:
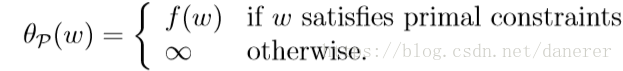
所以
就是我们的目标问题——原始优化问题:
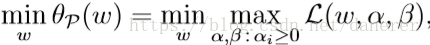
Dual Optimization Problem
我们定义函数
,其中D表示duo(对偶):

现在我们定义对偶优化问题:
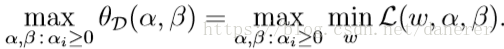
定义: 是原始优化问题 的最优值。
定义: 是原始优化问题 的最优值。
有这样一个在通常条件下成立的事实:
,即对偶优化问题的最优值小于等于原始优化问题的最优值。更一般的有,对于某个函数
而言,总是存在
。
For example:
。
关于对偶理论可以参考 运筹学(第四版) 清华大学出版社 第64页
对偶问题的一些性质:
1. 目标函数值相同时,各自的解为最优解
2. 若原问题有最优解,那么对偶问题也有最优解,且目标函数值相同
3. 还有互补松弛性,无界性,对称性等等
当原问题和对偶问题都取得最优解得时候,那么他们分别的目标函数也就到达了最优值。根据对偶问题的性质2,可以得到 那么我们就可以求解对偶问题来得到原问题 的最优值。
为了使得
我们需要满足一些条件,接下来我们开始推演
:
假设一:
是一个凸函数(
的Hessian矩阵是半正定矩阵)。
假设二:
是仿射函数(
,仿射的意思是这个函数任何时候都是线性的)。
假设三:
是严格可执行的(
)
通过这三个假设,我们得到KKT(Karush-Kuhn-Tucker conditions)条件(
是对偶最优问题的解,
),我们得到KKT:
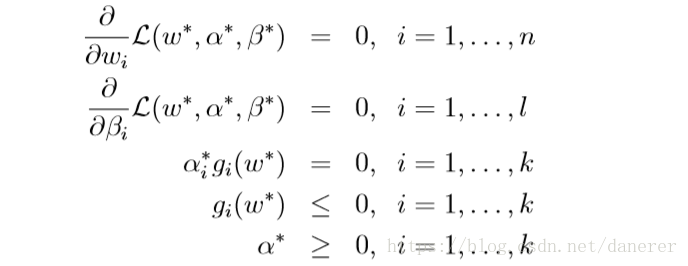
其中,
成为KKT互补条件,对于
,必有
。
参考资料
https://blog.csdn.net/xiaocainiaodeboke/article/details/50443680