卷积神经网络
computer vision
针对图像任务不能和之前一样直接使用全连接进行,因为如果图片分辨率很高那么向量化之后需要的参数空间很大,不便于计算,于是引入了卷积计算
边缘检测
边缘检测分为垂直边缘检测(vertical detection)和水平边缘检测(horizontal detection)。
垂直边缘检测使用的过滤器为
该过滤器的原理是当左边明亮,右边深色时就会认为是垂直边缘
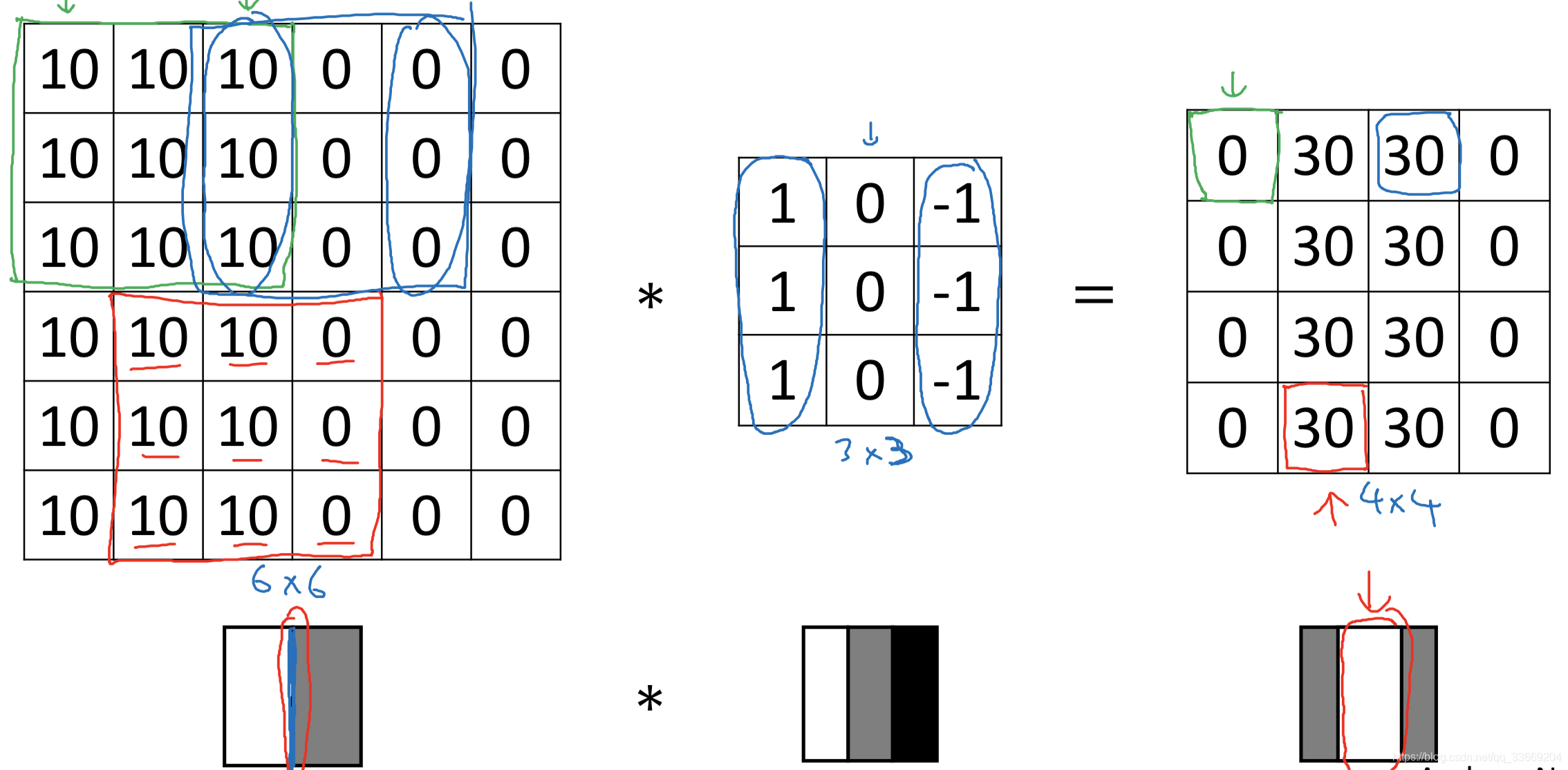
输出图片中间的明亮处可以认为在原图片中的该位置有明显的边缘。
该边缘检测方法可认为是卷积的一个典型例子
同样,水平算子可以表示为
对于深度学习来说,可以通过神经网络来学习一样这样的算子进行边缘检测。
padding
使用原因:
- 若不使用,那么每一次卷积之后图像都会变小
- 边缘部分的像素在卷积过程中使用的较少,因此图像大部分的边缘信息在卷积过程中都丢失了
使用padding后,每隔一个像素进行卷积的输出结果为:
其中 为输入图片的大小, 为padding的大小, 为卷积核的大小
根据是否padding,我们将卷积操作分为Valid convolution和Same convolution
- valid convolution为不使用padding的卷积,因此输出大小为
- same convolution为使用padding的卷积,输出图片的尺寸和输入图片的尺寸大小相同
在计算机视觉的任务重,我们认为kernel为奇数,这样做一方面是因为kernel为偶数时图片两边会产生不对称填充;另一方面奇数kernel会产生一个像素中心店,这个中心点有时候会有用(如指出滤波器的位置)。
stride convolution
stride是指每隔多少个像素进行一次卷积
若输入为
的图片,卷积核为
,padding为
,stride为
,那么在stride convolution后的输出图片大小为
这里需要指出两种卷积的不同定义:在数学上我们说的卷积需要将卷积核向左翻转
,然后左右互换;在深度学习中的卷积是卷积核直接与输入对应位置相乘。这样做一方面简化的代码实现的复杂度,另一方面也可以取得满意的效果
多个channel的卷积
卷积核的channel个数与输入channel个数相同
为输入channel的个数,
为卷积核的个数
卷积层的实现
卷积层在激活之前会加一个bias,然后再激活,基于这个实现,我们可以理解卷积实际上是对kernel大小的像素进行之前学习过的深度学习连接,然后再激活。
若有一个10层输出,输出中每一个值由前一层经
的卷积得到,那么参数个数为?
输出的每一层的卷积核参数个数为
,在卷积之后需要加上bias,所以参数个数为
,10层输出于是总个数为
。不管输入图片多大,需要的参数个数为 280(即对输入每一层的所有位置上的像素使用同一个卷积)。这样大大减少了参数的个数‘避免过拟合’。
于是当前层每一个卷积核为
激活之后
,
,也可以将channel的个数放在前面即
权重个数为
,bias为
Pooling
作用:如果过滤器中提取到某个特征,那么保留其最大值;如果没有提取到特征,那么其最大值依旧很小
注意pooling不改变channel的个数
除了Max pooling之外,也有average pooling。对于pooling我们经常设置的超参数为
,
。基于这两个超参数,pooling层通常会使长和宽减半,pooling层很少使用padding,而且pooling层没有参数需要学习。
Fully connected (FC)
全连接层是将上一层的输出平整化为一个单一向量,进行与之前学习的神经网络相同的链接进行运算。全连接层可以不止一个。我们可以认为之前的网络每一层都使用全连接。
为什么使用卷积
极大的减少了参数的个数,避免了过拟合。
参数少的原因有两个:
- 参数共享:一个特征检测器若在一个区域内有用,那么他对其他区域也会有用
- 稀疏连接:每一层输出的值只依赖其对应 kernel上的值,其他像素值均不会对该输出产生影响