深度学习具体应用
经典网络的学习
LeNet-5

上图是LeNet-5的结构(来自吴恩达的课件,下面所有图片均来自于吴恩达课件),该网络只有卷积层,pooling层和全连接层,pooling层使用的是均值池化,非线性激活使用的是sigmoid/tanh,而不是现在最常用的ReLU。
原文地址:http://www.dengfanxin.cn/wp-content/uploads/2016/03/1998Lecun.pdf
AlexNet
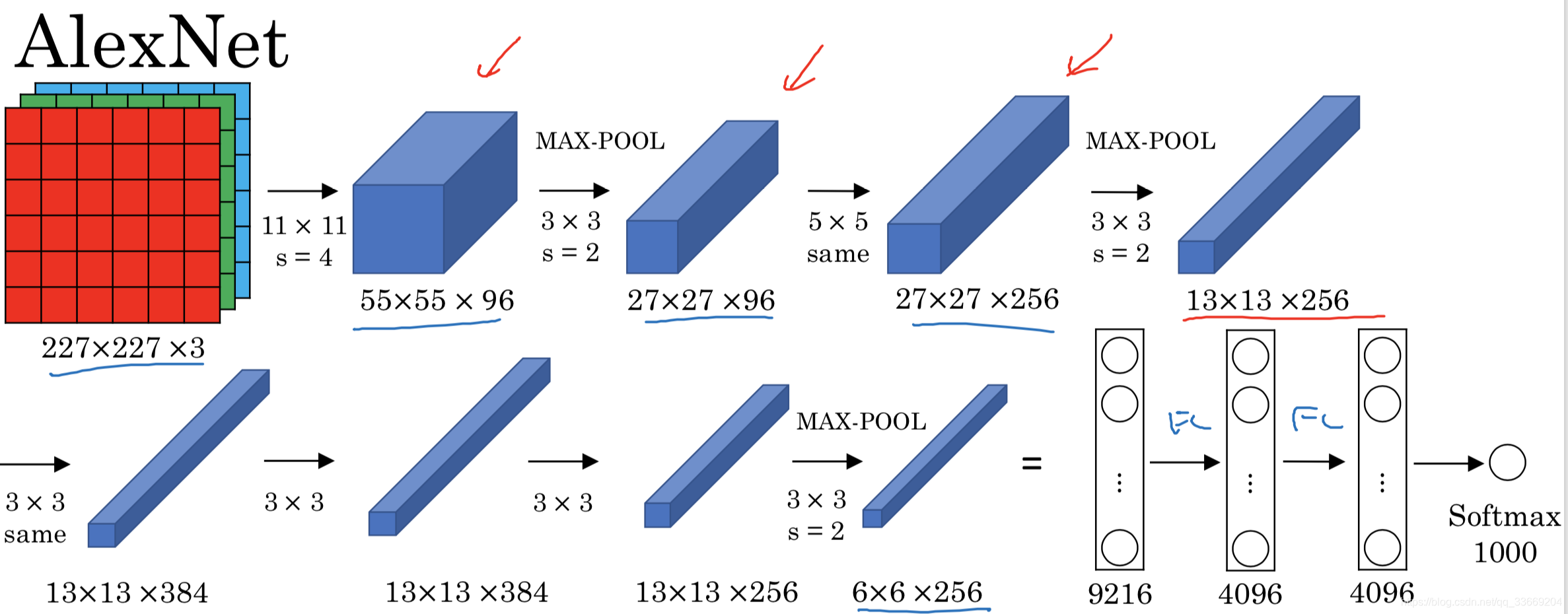
该网络与LeNet比较:
- 结构相似但是网络更深
- 使用ReLU作为激活函数
- 使用GPU进行并行计算
- Local Response Normalization(LRN局部相应归一化层):选取一个位置,对该位置上一个通道的值进行归一化(作用很小,现在的网络很少使用)
原文地址:https://www.nvidia.cn/content/tesla/pdf/machine-learning/imagenet-classification-with-deep-convolutional-nn.pdf
VGG-16
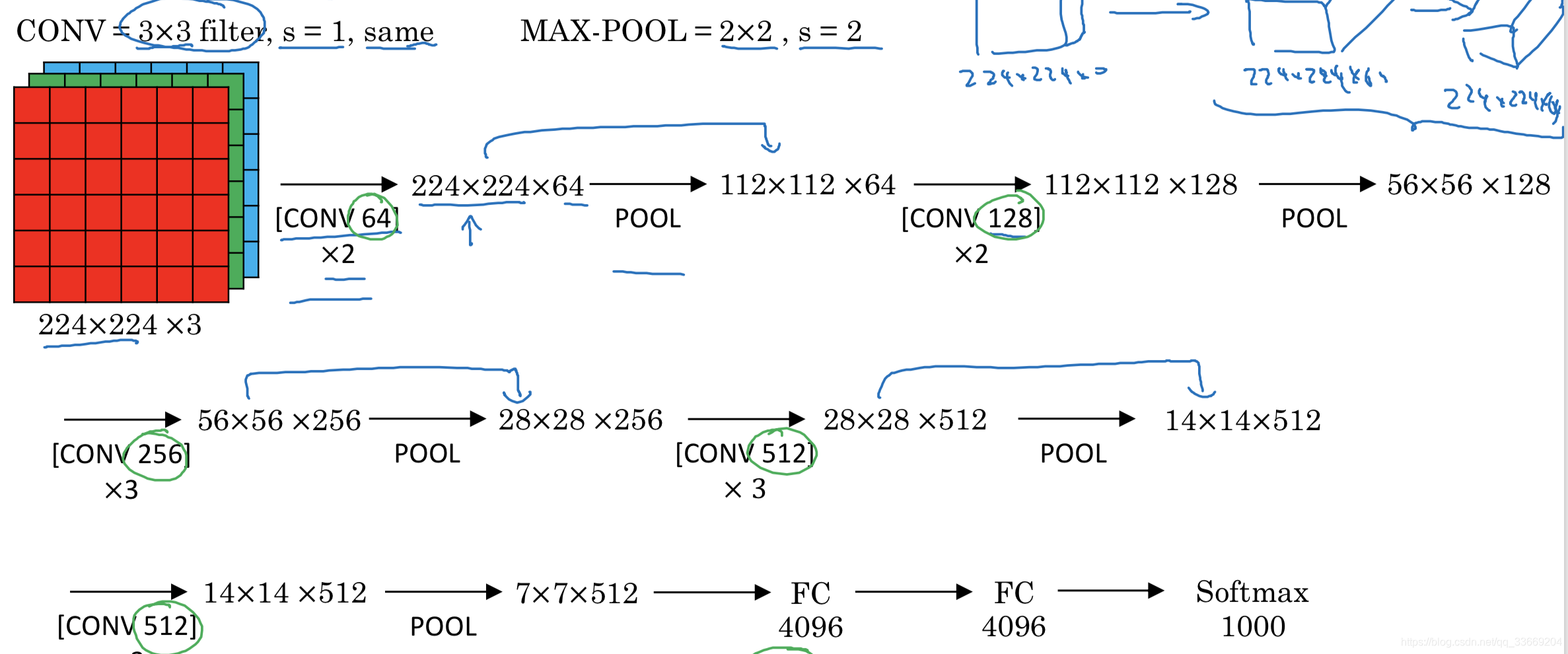
结构更为规整(卷积层后边带pooling层),而且随着网络加深,输入长宽的减少与信道数目的上升是有规律的
原文地址:https://arxiv.org/pdf/1409.1556.pdf http://arxiv.org/abs/1409.1556.pdf
(PS:吴恩达推荐阅读顺序为:先读Alex,再读VGG,最后LeNet)
Residual Network(残差网络)
出现的原因是由于训练非常深的网络时发现十分难训练,且经常出现梯度消失和梯度爆炸。
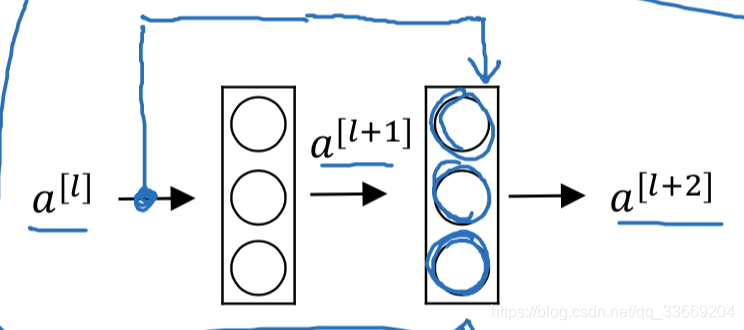
残差网络也叫做short cut或skip connection。
残差网络的计算流程为:
通过计算公式我们可以知道,残差网络是将前边层的输出加在线性激活之后,非线性激活之前。
残差网络为什么有用
理论上神经网络越深,那么训练误差越小,但是实际操作时发现,plain network(不带残差网络的网络)随着层数的增加,训练误差表现出先减小后增大的现象;而残差网络则表现为随着层数的加深训练误差越来越小。产生这种现象的原因可能是由于
,当
和
为0时,残差网络中
。因此在残差网络中很容易产生恒等函数而对于普通的网络很难产生恒等函数,所以在残差网络中随着层数的加深,网络的效果至少不会变差。
另外残差网络也可以解决梯度消失问题,详细解释在 https://blog.csdn.net/superCally/article/details/55671064
所以残差网络解决了:
- 退化:层数越深,误差越大
- 梯度消失
原文地址:https://arxiv.org/pdf/1512.03385.pdf
Network in Network
在神经网络中,在不考虑
(
)卷积层的前提下,长宽大小的变化我们可以通过pooling层来控制,为了控制channel的改变引入了1*1的卷积,通过该种特殊的卷积层来不做padding的前提下,只改变channel的值
原文地址:https://arxiv.org/pdf/1312.4400.pdf
Inception network
让神经网络自己选择使用哪种结构进行训练。
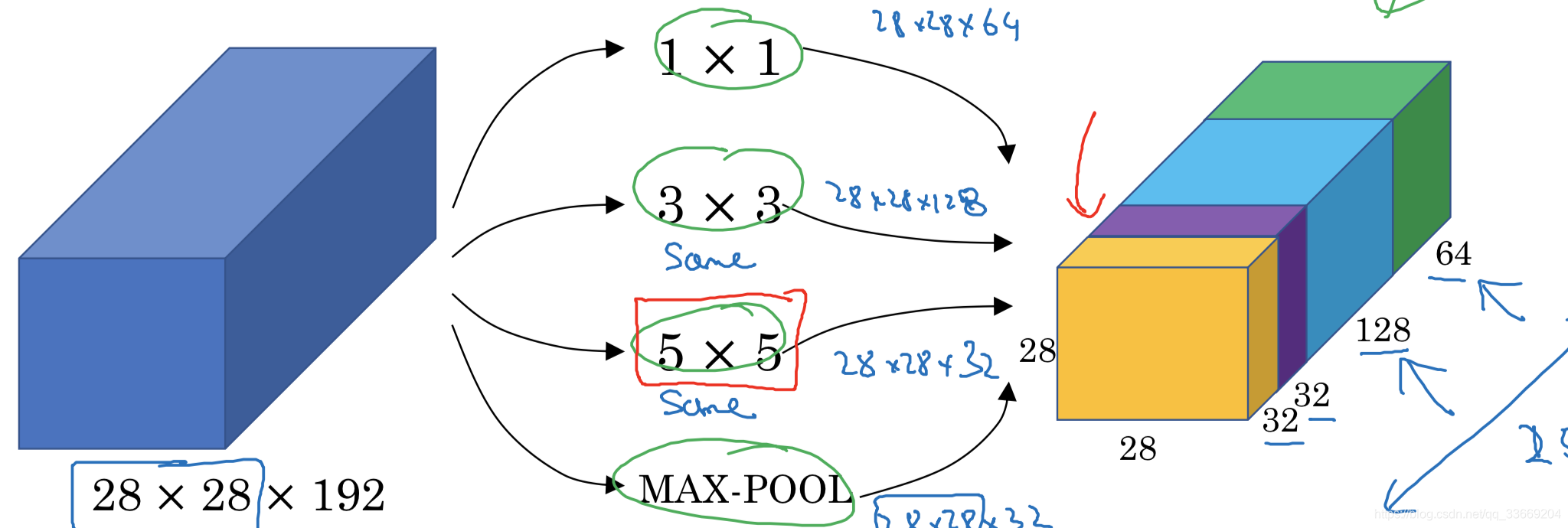
在上图中就是让网络自己选择使用卷积层还是池化层,卷积层使用哪种尺寸,注意这里pooling是做过padding的特殊pooling层(不改变输入的长宽)。
但是对于卷积层来说如果channel过大,那么卷积核的尺寸越大需要的参数越多,难以计算。于是引入11的卷积层改变channel的大小。
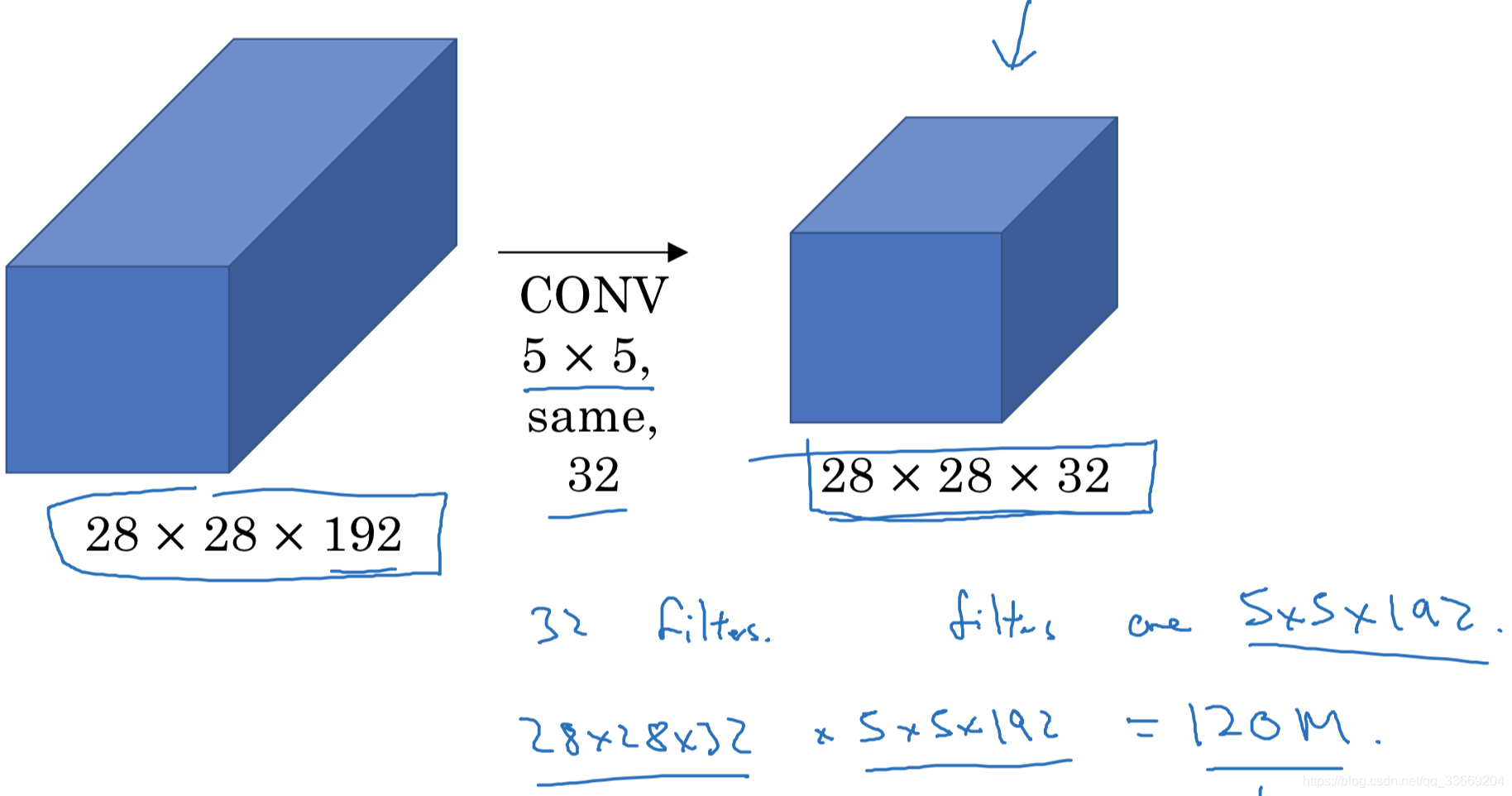
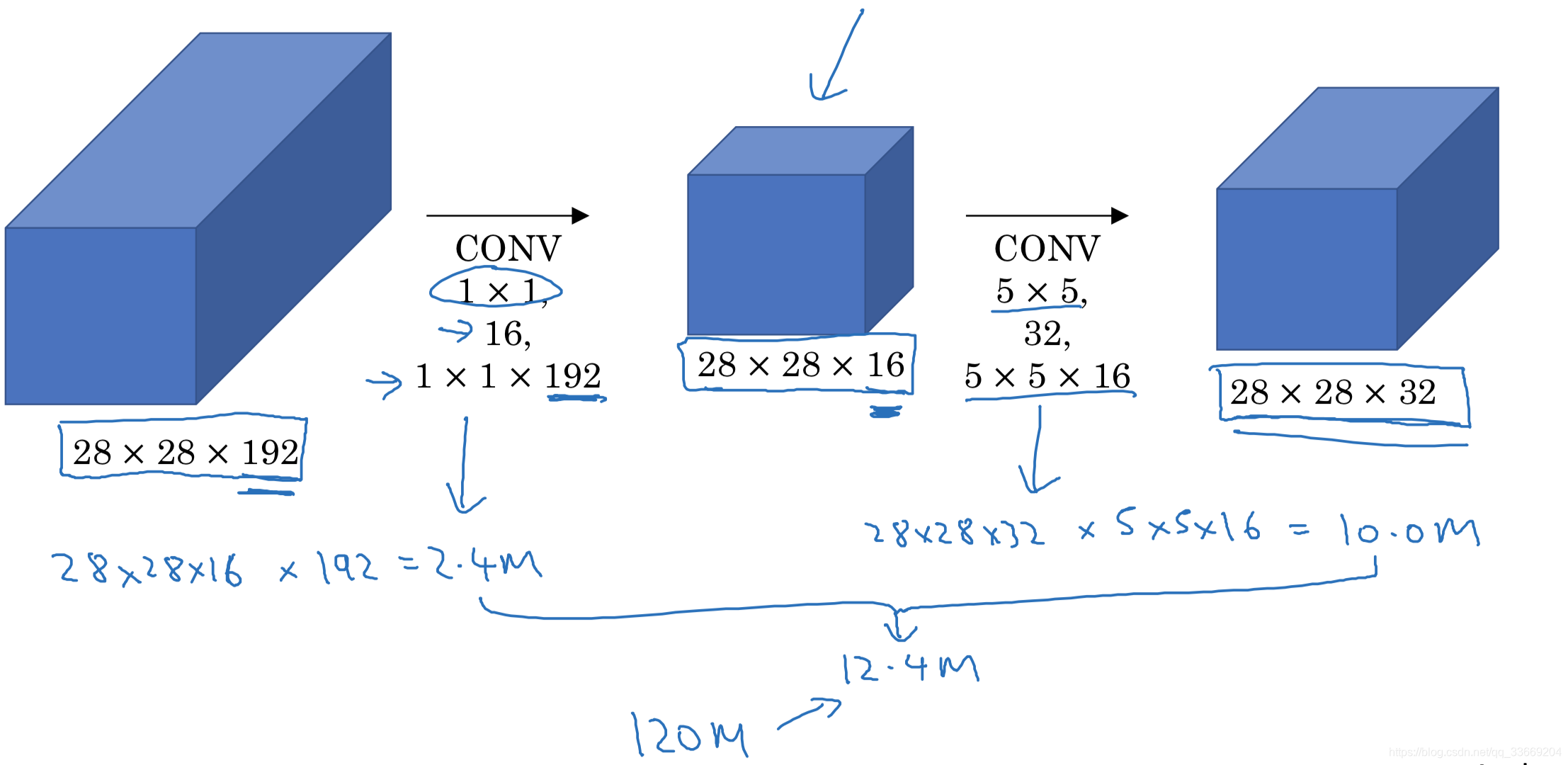
添加的11卷积层称为bottleneck layer,实验证明,只要合理构筑bottleneck layer那么既可以降低计算复杂度也不会影响识别性能。
所以Inception Network的基本结构为

原文地址为:https://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Szegedy_Going_Deeper_With_2015_CVPR_paper.pdf
迁移学习和数据增强
迁移学习
由于在计算机视觉中,很多任务可以从别的任务中寻求可以使用的特征提取方式,因此一般框架可以冻结前面的参数只训练新添加层的参数或者将输入
经原框架运行到softmax之前的层,再将输出结果放到自己的网络中进行训练。
添加新层数的多少取决于数据的多少。
一般来说,使用别人网络参数进行初始化取得的效果往往比随机初始化的效果好。
数据增强
- 垂直镜像对称
- 随机裁剪
- Rotating, shearing, local warping
- color shift:对不同颜色channel的改变要根据一定的分布进行
深度学习中一些小知识
深度学习网络的知识来源有两个,一是标记的数据;二是手动设计的特征/网络结构/其他的部分。拥有的数据越多需要手动设计的工作越少,算法越简单;反之,数据少那么就需要更多的手动设计,算法越复杂。
在竞赛上提高准确度的小方法
- 集成:独立训练多个网络取输出的平均(要保存所有的网络,占内存)
- multi-crop:以10-crop为例,原图像取中心crop,再取左上,左下,右上,右下4个crop,再对镜像图片取同样的五个crop,将这10个crop用分类器计算去平均(不占内存,占时间)