逻辑回归
1、逻辑回归为什么不采用平方损失?
因为平方损失是一个非凸函数,利用梯度下降容易陷入局部最优
 2、sigmoid函数的导数
2、sigmoid函数的导数
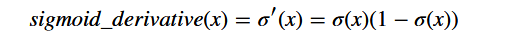
3、逻辑回归参数更新过程
 逻辑回归损失(交叉熵损失)和平方损失,计算得到的梯度dw和db是一的,dw=x(A-Y),db=A-Y,如果借助向量运算,同时计算m个样本,那么梯度需要对m求平均。在编码时,还需要考虑维度信息,如转置。。
逻辑回归损失(交叉熵损失)和平方损失,计算得到的梯度dw和db是一的,dw=x(A-Y),db=A-Y,如果借助向量运算,同时计算m个样本,那么梯度需要对m求平均。在编码时,还需要考虑维度信息,如转置。。
浅层神经网络
1、为什么要使用非线性的激活函数?
如果使用线性激活函数,那么就只能进行线性变换,有再多的隐含层都是无用的,因为多次线性变换的结果与一次线性变换结果几乎没有区别,那么多个隐含层相当于浪费。。。
机器学习里也有用线性函数做激活函数的,那就是线性回归。
2、神经网络的反向传播公式:(一个隐含层)
注意:手推BP算法时,需要注意以下几点:
- 在吴恩达课程中,最后的输出层的dz = A - Y;
- 样本个数设为1还是n,如果设为n,涉及到求dw和db是需要除以n求平均,另外,样本数n会影响到b的维度,所以需要用sum先对n个b求和再求平均,但是w的维度只与每层神经元个数有关,所以不需要sum求和,只需要求平均;
- 注意是矩阵乘积还是向量乘积;


3、浅层神经网络的随机初始化
在逻辑回归中,可以将权值和偏置都设为零,但在神经网络中,偏置可以初始化为0,但是权重不能初始化为零,如果权值初始化为零,会出现如下结果:
(1)正向传播时,不能打破对称性,每层神经元学习到的东西是一样的,这样得到的分类器并不比逻辑回归强大
(2)梯度下降更新参数时,更新的效果也一样,导致w中多个分类器相同,如图,第一层的两个分类器相同,第二层只有一个分类器(w矩阵一层为一个分类器)
深层神经网络
1、深层神经网络反向传播求梯度公式
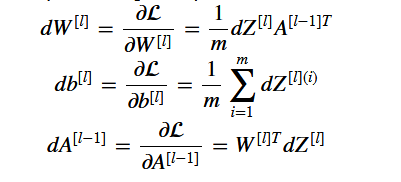
正则化方法
1、L2正则化
l2正则化依赖于这样一个假设,即具有小权值的模型比具有大权值的模型更简单。因此,通过惩罚成本函数中权重的平方值,就可以将所有权重转换到更小的值。这导致了一个更平滑的模型。
在具体实施时,需要注意以下几点:
1>代价函数变了,增加了一项对所有权重求平方和np.sum(np.square(Wl))的步骤,然后乘以λ/m,λ为正则化参数,除以m是因为要对m个样本求平均,因为前边求sum把多个样本都求进去了
2>dW变了,dW多出来一项 λ*W/m 。。。
3>正则化的实质是权重衰减。。
4>当lambda很大时,W是趋近于0的,相当于简化了网络结构
2、Drop out正则化(随机失活)
实际就是给每个神经元加了一个概率(keep_prob),小于keep_prob时就保留,大于是就删除(相当于将此神经元值置为0),从而达到简化网络结构的目的。
注意:drop out 后的a3要再除以一个keep_prob,目的是保证期望不变
对于不同的层,可以采用不同的keep_prob,取决于该层的过拟合程度,当keep_prob为1时,说明该层不需要正则化
缺点:这种正则化方法没有显式的代价函数J(),所以无法显示代价的下降过程
卷积神经网络基础 卷积 池化 全连接
(1)卷积操作
卷积前后的feature map的大小变化为:


填充的作用:
正常卷积,对角落和边缘的信息利用的较少,通过填充,可以充分利用角落和边缘信息
(2)池化
作用:缩小规模,提高计算速度,提高所提取特征的鲁棒性
 注意,池化层没有需要学习的参数。
注意,池化层没有需要学习的参数。
(3) 为什么使用卷积神经网络?
- 参数少
- 参数共享:一个特征检测器(filter)对图片的一部分有用的同时也有可能对图片的另外一部分有用。
- 连接的稀疏性:在每一层中,每个输出值只取决于少量的输入。